稀有事件Logitsic模型及其在我國上市公司財務困境預測中的應用研究
2017-03-31 23:58:57張錫
時代金融 2017年8期


【摘要】我國上市公司一般具有較大的資產規模與較強的盈利能力,發生財務困境的概率較低,數據呈非平衡性。采用傳統Logistic回歸會受到因變量分布不平衡的影響。本文將西方學者在醫學現象研究中普遍使用的稀有事件Logistic回歸引入我國上市公司財務困境預測的研究中,根據財務困境發生實際概率確定樣本觀察單位的權重,構建Relogit回歸模型。研究結果表明,Relogit模型預測效果優于傳統Logistic模型。
【關鍵詞】上市公司 財務困境 Logistic回歸 Relogit回歸
一、引言
Logistic回歸模型由于其假設寬松、形式簡潔、易于解釋等優點,近年來被廣泛應用于因變量為類別變量的各種預測、判別模型當中(付仲良等,2016;方匡男等,2016)。但在實際研究過程中,當因變量分布不均衡時,模型的殘差方差較大,會導致傳統Logistic模型產生有偏的預測結果(魏瑾瑞等,2016)。
國內學者在對我國上市公司發生財務困境的概率進行預測時,一般將上市公司當期是否被特別處理作為因變量(被ST、ST*公司Y=1,否則Y=0),上一期的各項財務指標作為自變量,使用傳統Logistic模型回歸得到判別模型(曾繁榮等,2014;宋曉娜等,2016)。但在我國,上市公司一般具有較大的資產規模與較強的盈利能力,發生財務困境的概率很低,2016年我國A股上市公司發生財務困境的概率不足2%。使用傳統Logistic回歸模型的效果也就打了折扣。針對這一問題,我們雖然可以通過抽樣的方法提高建模樣本中發生財務困境公司的比例,但這樣做一方面會喪失許多優質上市公司的數據,減少樣本量;另一方面,樣本配比的選擇也沒有公認的標準。
與此同時,西方學者Asher et al.(2011),Haem et al.(2014)在醫學現象研究中開始使用稀有事件Logistic回歸(Rare Events Logistic)方法。其思想是基于稀有事件發生的概率,對傳統Logistic回歸結果進行校正。具體校正方法分為先驗校正和加權校正。Prentice和Pyke(1979)首先提出了根據總體中因變量Y=1的抽樣概率進行先驗校正(prior correction)的Relogit方法。由于樣本選擇容易產生偏差,抽樣概率與總體概率之間存在難以克服的差異,Zare et al.(2013)又在此基礎之上提出了加權校正(Weight Correction)的Relogit方法。相比于傳統Logistic回歸模型,Relogit模型根據實際概率確定樣本觀察單位的權重,并且允許更大的建模樣本,模型的估計更加準確。
考慮到我國上市公司發生財務困境概率小于10%,滿足稀有事件的定義標準(趙晉芳等,2011)。同時,本文的研究對象包含了2016年A股的所有上市公司,樣本量滿足大樣本條件,在這種情況下加權校正的模型精度要高于先驗校正,因此本文使用加權校正的Relogit(Weight Correction Relogit)方法進行研究,并與傳統Logistic回歸分析所得結果進行比較。
二、Relogit方法
實證研究中,當因變量為二分類變量,自變量為連續變量或虛擬變量時,傳統Logistic方法可以將因變量Y=1的概率表示為
P(X)=■
其中,X1為自變量的觀測值,α、β分別為截距項和回歸參數向量。傳統Logistic回歸系數的極大似然估計值β具有一致性、漸近有效性和漸近正態性,并且在樣本因變量Y的兩類取值頻率相等時建模效果最為理想。
但對于上市公司而言,大部分公司處于財務健康狀態(Y=0),而出現財務困境的上市公司所占比率很小(Y=1)。這會導致傳統Logistic回歸在參數估計和概率預測產生偏差。基于前文所述,本文采用加權校正的Relogit方法進行實證分析。這里簡要介紹加權校正的具體步驟。
研究中可能存在由于樣本選擇導致的總體概率τ與樣本概率■存在差異,加權校正(Weight Correction)則可以通過對樣本觀察單位給予合適的權重來修正選擇偏倚造成的影響。具體而言,對樣本中Y=1的觀察單位給予權重w2=τ/■,對Y=0的觀察單位給予權重w0=(1-τ)/(1-■)。因此,修正后的加權對數似然函數為
L=w■■ln(P■)+w■■ln(1-P■)
L=■wiln(1+exp[(1-2yi)(α+x'β)])
其中,wi=wiyi+w0(1-yi)
此外,Gary King和Langche Zeng(2001)還提出了基于小樣本Relogit回歸的MCN校正法,考慮到本文使用的數據具有大樣本性質,在此不對其進行過多討論。
三、實證分析
(一)數據和變量
本文的樣本選取了2016年中國A股所有上市公司進行研究,所有數據均來自于同花順iFind數據庫。為避免樣本企業同時發行A、B(H)股所帶來的數據不一致,統一取A股市場的數據進行研究。刪除數據缺失樣本后,實際樣本共包含2370家上市企業,其中正常公司(Y=0)2318家,財務困境公司(Y=1)52家。財務困境公司所占比例為2.19%,滿足“稀有事件”的定義條件。
由于本文選取了具有高頻變動特點的股票市場相關指標作為解釋變量,若采用面板數據研究容易忽略不同年份宏觀政策、市場背景不同對指標體系的影響,對模型結果所造成的誤差。因此我們最終選擇截面數據進行研究,通過我國上市公司2015年的所公布的企業財務信息,預測其2016年發生財務困境的概率。
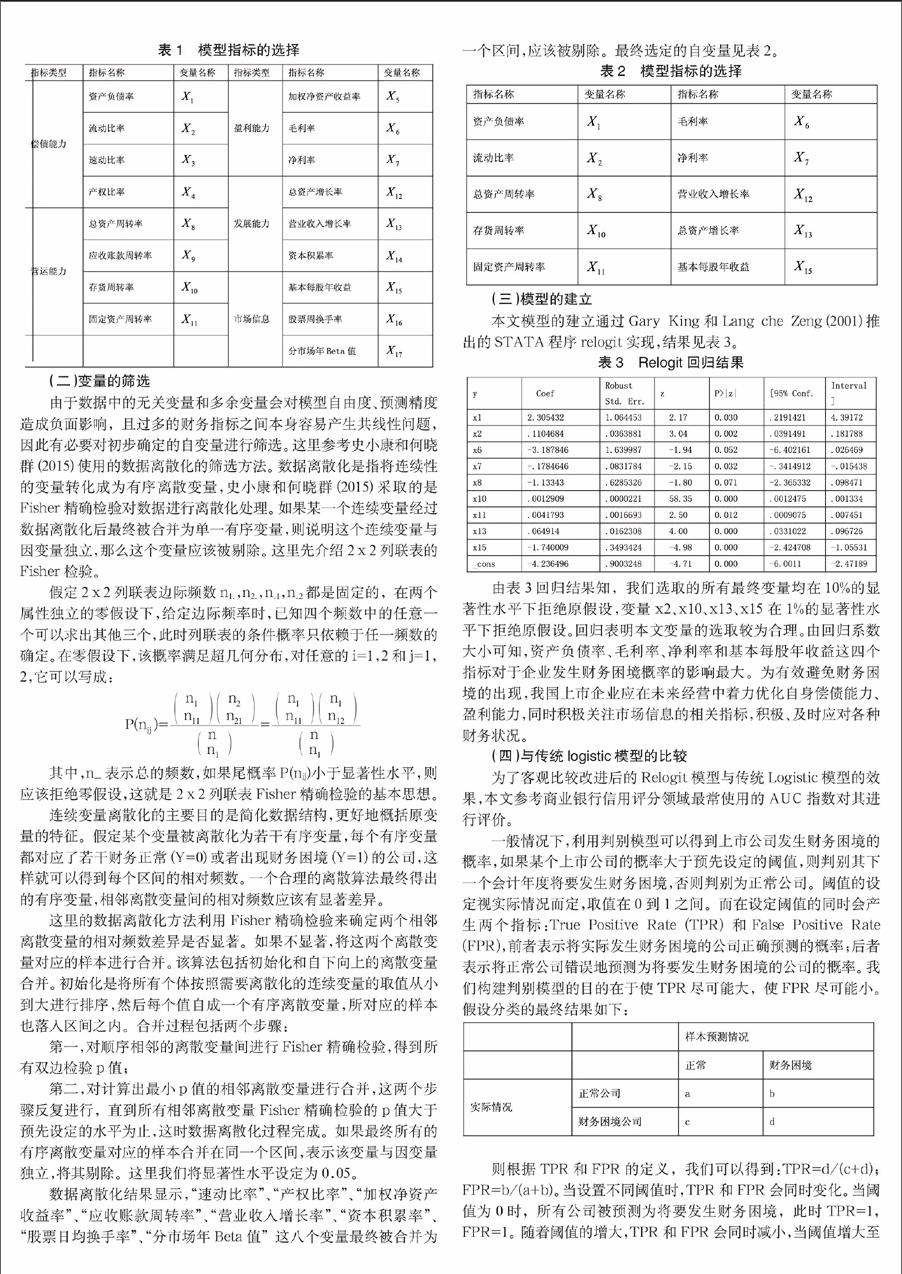
通過參考目前中國銀行規定的企業信用評級及國外權威的標準普爾評級指標體系,反映企業財務狀況的指標應對其營運能力、償債能力、盈利能力、發展能力合理評價,同時參考國內現有文獻,初步確定的自變量如表1所示。
表1 模型指標的選擇
■
(二)變量的篩選
由于數據中的無關變量和多余變量會對模型自由度、預測精度造成負面影響,且過多的財務指標之間本身容易產生共線性問題,因此有必要對初步確定的自變量進行篩選。這里參考史小康和何曉群(2015)使用的數據離散化的篩選方法。數據離散化是指將連續性的變量轉化成為有序離散變量,史小康和何曉群(2015)采取的是Fisher精確檢驗對數據進行離散化處理。如果某一個連續變量經過數據離散化后最終被合并為單一有序變量,則說明這個連續變量與因變量獨立,那么這個變量應該被剔除。這里先介紹2x2列聯表的Fisher檢驗。
假定2x2列聯表邊際頻數n1.,n2.,n.1,n.2都是固定的,在兩個屬性獨立的零假設下,給定邊際頻率時,已知四個頻數中的任意一個可以求出其他三個,此時列聯表的條件概率只依賴于任一頻數的確定。在零假設下,該概率滿足超幾何分布,對任意的i=1,2和j=1,2,它可以寫成:
P(n■)=■=■
其中,n_表示總的頻數,如果尾概率P(nij)小于顯著性水平,則應該拒絕零假設,這就是2x2列聯表Fisher精確檢驗的基本思想。
連續變量離散化的主要目的是簡化數據結構,更好地概括原變量的特征。假定某個變量被離散化為若干有序變量,每個有序變量都對應了若干財務正常(Y=0)或者出現財務困境(Y=1)的公司,這樣就可以得到每個區間的相對頻數。一個合理的離散算法最終得出的有序變量,相鄰離散變量間的相對頻數應該有顯著差異。
這里的數據離散化方法利用Fisher精確檢驗來確定兩個相鄰離散變量的相對頻數差異是否顯著。如果不顯著,將這兩個離散變量對應的樣本進行合并。該算法包括初始化和自下向上的離散變量合并。初始化是將所有個體按照需要離散化的連續變量的取值從小到大進行排序,然后每個值自成一個有序離散變量,所對應的樣本也落入區間之內。合并過程包括兩個步驟:
第一,對順序相鄰的離散變量間進行Fisher精確檢驗,得到所有雙邊檢驗p值;
第二,對計算出最小p值的相鄰離散變量進行合并,這兩個步驟反復進行,直到所有相鄰離散變量Fisher精確檢驗的p值大于預先設定的水平為止,這時數據離散化過程完成。如果最終所有的有序離散變量對應的樣本合并在同一個區間,表示該變量與因變量獨立,將其剔除。這里我們將顯著性水平設定為0.05。
數據離散化結果顯示,“速動比率”、“產權比率”、“加權凈資產收益率”、“應收賬款周轉率”、“營業收入增長率”、“資本積累率”、“股票日均換手率”、“分市場年Beta值”這八個變量最終被合并為一個區間,應該被剔除。最終選定的自變量見表2。
表2 模型指標的選擇
■
(三)模型的建立
本文模型的建立通過Gary King和Lang che Zeng(2001)推出的STATA程序relogit實現,結果見表3。
表3 Relogit回歸結果
■
由表3回歸結果知,我們選取的所有最終變量均在10%的顯著性水平下拒絕原假設,變量x2、x10、x13、x15在1%的顯著性水平下拒絕原假設。回歸表明本文變量的選取較為合理。由回歸系數大小可知,資產負債率、毛利率、凈利率和基本每股年收益這四個指標對于企業發生財務困境概率的影響最大。為有效避免財務困境的出現,我國上市企業應在未來經營中著力優化自身償債能力、盈利能力,同時積極關注市場信息的相關指標,積極、及時應對各種財務狀況。
(四)與傳統logistic模型的比較
為了客觀比較改進后的Relogit模型與傳統Logistic模型的效果,本文參考商業銀行信用評分領域最常使用的AUC指數對其進行評價。
一般情況下,利用判別模型可以得到上市公司發生財務困境的概率,如果某個上市公司的概率大于預先設定的閾值,則判別其下一個會計年度將要發生財務困境,否則判別為正常公司。閾值的設定視實際情況而定,取值在0到1之間。而在設定閾值的同時會產生兩個指標:True Positive Rate(TPR)和False Positive Rate(FPR),前者表示將實際發生財務困境的公司正確預測的概率;后者表示將正常公司錯誤地預測為將要發生財務困境的公司的概率。我們構建判別模型的目的在于使TPR盡可能大,使FPR盡可能小。假設分類的最終結果如下:
■
則根據TPR和FPR的定義,我們可以得到:TPR=d/(c+d); FPR=b/(a+b)。當設置不同閾值時,TPR和FPR會同時變化。當閾值為0時,所有公司被預測為將要發生財務困境,此時TPR=1,FPR=1。隨著閾值的增大,TPR和FPR會同時減小,當閾值增大至1時,沒有公司被預測將會發生財務困境,此時TPR=0,FPR=0。
通過上述過程可知,TPR與FPR存在同向變化的關系。由于我們構建判別模型的目的在于使TPR盡可能大,使FPR盡可能小。因此我們可以根據不同閾值下,TPR和FPR取值作出二者的ROC曲線圖。
■
當ROC曲線越遠離直線y=x,表明可以通過設置合理閾值,增加較少的FPR,來增加較多的TPR,因此模型效果越好。信用評分領域現有的習慣做法是將ROC曲線與x軸之間的面積定量地評價模型的效果,記作AUC。AUC值越大,表明模型擬合狀況越好。
為了客觀比較本文建模使用的加權校正Relogit模型與傳統Logistic模型的建模效果,我們采用相同樣本和解釋變量同時進行Relogit回歸和傳統的Logistic回歸,分別得出了二者的ROC曲線。通過下圖可以看出,Relogit模型AUC值為0.9115,大于傳統Logistic模型的AUC值(0.9093)。說明在因變量分布不均衡的條件下,采用加權校正的Relogit模型要略優于傳統Logistic模型。
■
四、結論
Logistic回歸模型在社會科學領域有著廣泛的應用,也是近十年來在上市公司財務困境預測領域最受親睞的模型,但它在因變量分布不平衡的數據中殘差方差較大,預測效果降低。本文采取加權校正的方法,對傳統Logistic回歸模型進行了改進,構造了能更好適應稀有事件偏態數據特征的Relogit模型。通過ROC曲線和AUC值可以發現,Relogit模型對于大樣本稀有事件的擬合效果要優于普通Logistic回歸模型。由于Relogit模型在實際應用中兼具傳統Logistic模型相似的可操作性和可解釋性,這也為我們在該領域今后的實證中提供了一種可行的方法。但還須注意,上市公司財務困境預測領域選擇的方法較多,譬如神經網絡模型、支持向量機等(鮑新中等,2013;倪志偉等,2014),它們各自使用的是不同的算法,不存在所有情況下都是最優的模型,因此,在實際操作中,我們還須針對實際情況和樣本數據的特征,對各種方法進行科學地比較后,再做出相應的選擇。
參考文獻
[1]Haem,E.,Heydari,S.,et al,“Ovarian Cancer Risk Factors in a Defined Population Using Rare Event Logistic Regression”,Middle East Journal of Cancer,2015,6(1),1-9.
[2]Asher G.W,Archer J.A,Ward J.F.,Scott I.C.,and Littlejohn R.P.,“Effect of melatonin implants on the incidence and timing of puberty in female red deer”,Animal Reproduction Science,2011,123 (3-4),202-209.
[3]Zare,N.,Haem,E.,Lankarani,K.,Heydari,S.,Barooti,E.,“Breast Cancer Risk Factors in a Defined Population: Weighted Logistic Regression Approach for Rare Events”,Journal of Breast Cancer,2013,16 (2),214-219.
[4] King G.,Zeng L.C.“Explaining rare events in international relations”,International Organization,2001,55(3):693-715.
[5] Prentice R.L.,Pyke R.,”Logistic disease incidence models and case-control studies”,Biometrika,1979,66(3):403-411.
[6]付仲良,楊元維,高賢君,趙星源,逯躍鋒,陳少勤.利用多元Logistic回歸進行道路網匹配[J].武漢大學學報(信息科學版),2016,02:171-177.
[7]魏瑾瑞,呂曉云.Logistic模型對非平衡數據的敏感性:測度、修正與比較[J].統計研究,2016,02:79-85.
[8]方匡南,范新妍,馬雙鴿.基于網絡結構Logistic模型的企業信用風險預警[J].統計研究,2016,04:50-55.
[9]宋曉娜,黃業德,張峰.基于Logistic和主成分分析的制造業上市公司財務危機預警[J].財會月刊,2016,03:67-71.
[10]趙晉芳,羅天娥,范月玲,曾平,仇麗霞,劉桂芬.稀有事件logistic回歸在醫學研究中的應用[J].中國衛生統計,2011,06:641-644.
[11]史小康,何曉群.有偏logistic回歸模型及其在個人信用評級中的應用研究[J].數理統計與管理,2015,06:1048-1056.
[12]倪志偉,薛永堅,倪麗萍,肖宏旺.基于流形學習的多核SVM財務預警方法研究[J].系統工程理論與實踐,2014,10:2666-2674.
[13]曾繁榮,劉小淇.引入非財務變量的上市公司財務困境預警[J].財會月刊,2014,08:25-30.
[14]鮑新中,楊宜.基于聚類-粗糙集-神經網絡的企業財務危機預警[J].系統管理學報,2013,03:358-365.
作者簡介:張錫(1993-),女,漢族,安徽阜陽人,畢業于華中農業大學,研究方向:會計學。
