中醫(yī)方劑數(shù)據(jù)庫文本挖掘數(shù)據(jù)預處理的嘗試
2015-09-09 20:49:23吳磊李舒
中國中醫(yī)藥圖書情報 2015年3期
關鍵詞:文本挖掘
吳磊+李舒

摘要:目的針對中醫(yī)方劑數(shù)據(jù)挖掘需要提出一套以數(shù)據(jù)清洗為主的數(shù)據(jù)預處理方法,使數(shù)據(jù)規(guī)范、準確和有序,利于后續(xù)處理。方法通過檢索技術(shù),在方劑數(shù)據(jù)庫中獲取文本數(shù)據(jù)源,將非規(guī)范化的數(shù)據(jù)通過輔助詞群行處理、正則表達式替換、異名處理等步驟進行清洗,改進數(shù)據(jù)質(zhì)量。結(jié)果在中國方劑數(shù)據(jù)庫共檢索到1758條記錄,在方劑現(xiàn)代應用數(shù)據(jù)庫共檢索到91條記錄。源文本數(shù)據(jù)經(jīng)預處理后共得到有效記錄6913味藥,可成功導入相關信息挖掘系統(tǒng)進行方劑名稱和中藥名詞的信息抽取。結(jié)論本方法適用于基于中醫(yī)方劑數(shù)據(jù)庫的文本挖掘和知識發(fā)現(xiàn),可成功對源文本數(shù)據(jù)實施清洗,得到標準統(tǒng)一、無噪聲的數(shù)據(jù),實現(xiàn)所需方藥信息的有效抽取,可為中醫(yī)方劑文本型數(shù)據(jù)信息分析與挖掘研究提供有益的借鑒。
關鍵詞:中醫(yī)方劑:方劑數(shù)據(jù)庫:文本挖掘:數(shù)據(jù)預處理:數(shù)據(jù)清洗
doi:10.3969/j.issn.2095-5707.2015.03.003An Attempt on Data Preprocessing for Text Mining in TCM Prescription DatabaseWU Leil, LI Shu2(1. Information Engineering College, Liaoning University of TCM, Shenyang Liaoning 110847, China;2. Department of Medical Informatics, China Medical University, Shenyang Liaoning 110001, China)
Abstract: Objective To propose a set of data preprocessing method based on data cleaning for TCMprescription database; To make data more standard, accurate and orderly, and convenient for follow-up processing.Methods The text data source was retrieved from prescription databases by bibliographic searching techniques.Non-nonnalized data were processed through steps followed by auxiliary word group line processing, regularexpression substitution, and synonyms processing, with a purpose to unprove data quality. Results Totally 1758effective records were retrieved from TCM prescription database, and 91 records were retrieved from prescriptionmodern application database. 6913 effective Chinese herbal medicines were retrieved after preprocessing, whichcan be successfully imported into relevant information mining system, and information about prescription andherb names can be extracted. Conclusion This method is applicable for text mining and knowledge discovery in TCM prescription database. It can successfully implement data cleaning for source text data, get data with unifiedstandard and without noise, and finally realize the effective extraction of prescription information, which canprovide references for researches on analysis and mining ofTCM prescription text data.
Key words: TCM prescriptions; prescription database; text mining; data preprocessing; data cleaning
近年來中醫(yī)藥信息化發(fā)展迅速,已構(gòu)建及完善了大量的中醫(yī)方劑數(shù)據(jù)庫,中醫(yī)方劑數(shù)據(jù)挖掘和文本挖掘方興未艾。雖然方劑數(shù)據(jù)庫是經(jīng)過一定校對勘誤后的結(jié)構(gòu)化數(shù)據(jù)庫,但庫中原始數(shù)據(jù)通常因年代跨度大,并保留了不同時期原方的信息特點,對方劑、藥物信息的表述準確性及規(guī)范統(tǒng)一方面存在一些問題,存在錯誤的、冗余的、無效的和不一致的噪聲數(shù)據(jù)。因而直接抽取原生信息無法滿足數(shù)據(jù)挖掘和知識發(fā)現(xiàn)的具體要求,需要對數(shù)據(jù)進行必要的預處理,使之規(guī)范、準確和有序,實現(xiàn)數(shù)據(jù)的正確表達和合理組織,達到數(shù)據(jù)挖掘的基本條件。
數(shù)據(jù)預處理是數(shù)據(jù)挖掘中極為重要的方面。數(shù)據(jù)挖掘過程的大部分工作都在數(shù)據(jù)預處理環(huán)節(jié)。根據(jù)統(tǒng)計,在一個完整的數(shù)據(jù)挖掘過程中,數(shù)據(jù)預處理占用約60%的時間,而后的挖掘工作僅占總工作量的10%左右。數(shù)據(jù)清洗( data cleaning)是解決問題數(shù)據(jù)的主要預處理過程,對確保數(shù)據(jù)質(zhì)量具有重要作用。本文以中醫(yī)治療中風病方劑數(shù)據(jù)挖掘為例,探討一種以數(shù)據(jù)清洗為主的數(shù)據(jù)預處理方法,為后續(xù)配伍規(guī)律知識發(fā)現(xiàn)研究提供數(shù)據(jù)支持。
資料與方法
數(shù)據(jù)來源
由于本研究主要針對方劑名稱和藥物名稱進行預處理,因此選用了兩個具備方劑和藥物名稱的數(shù)據(jù)庫,即中國方劑數(shù)據(jù)庫和方劑現(xiàn)代應用數(shù)據(jù)庫,均隸屬于中國中醫(yī)科學院中醫(yī)藥信息研究所自1984年開始進行建設的中醫(yī)藥學大型數(shù)據(jù)庫群。
在中醫(yī)藥在線(http://www.cintcm.com/)的中醫(yī)藥多庫融合平臺( http://cowork.cint cm.com/engine/windex.jsp)中,選擇方劑類數(shù)據(jù)庫中的中國方劑數(shù)據(jù)庫和方劑現(xiàn)代應用數(shù)據(jù)庫,字段選擇均用“主治”,模糊檢索,輸入“中風”,年代不限,檢索時間為2013年11月27日。
研究方法與工具
基于輔助詞群的行處理工具 文本行抽取和處理是文本數(shù)據(jù)預處理中的常用方法,而基于輔助詞群的方法可有效提升其靈活度。該方法是基于預先建立的包含輔助詞群的輔助文件,可對源文件實現(xiàn)抽取或去除包含輔助文件中詞群的行輸出;并可按給定的批量行號提取行。
本研究中的行處理由數(shù)字人文研究內(nèi)容挖掘系統(tǒng)ROST CM實現(xiàn)。
正則表達式文本處理工具正則表達式是一種可以用于模式匹配和替換的規(guī)范,一個正則表達式就是由普通的字符以及特殊字符組成的文字模式,它用以描述在查找文字主體時待匹配的一個或多個字符串。在很多文本編輯器或其他工具里,正則表達式通常被用來檢索和/或替換那些符合某個模式的文本內(nèi)容。
正則表達式可用來驗證字符串是否符合指定特征并用來查找字符串,比查找固定字符串更加靈活方便;可以用來替換,比普通的替換更強大。例如表達式“ab+”描述的特征是一個“a”和任意個“b”,那么“ab”“abb”“abbbbbbbbbb”都符合這個特征。
本研究中的正則表達式處理由文本處理工具Textpro實現(xiàn)。
納入和排除標準
納入標準:以方劑主治病證中明確出現(xiàn)中風、半身不遂、偏枯、癱瘓、神識昏蒙、言語蹇澀或不語、口眼歪斜及其同義詞或近義詞為主癥,篩選出主治這些主癥的方劑或其主治內(nèi)容所包含的信息與已知的中風病病因病機符合的方劑。
排除標準:排除方劑所治癥狀可明確為其他因素(非中風)所引起的偏枯、偏癱、口眼歪斜等,無主癥或主癥不符合,及屬于治療外感表證和類中風(中寒、中暑、中濕、痰厥等致半身不遂、偏枯癱瘓)的中風方劑,如風痹;外風、風濕/類風濕型產(chǎn)后中風、小兒中風;風寒/傷寒中風,破傷中風,心肺中風,脾胃中風,肝臟中風,中毒等。2結(jié)果與分析
中國方劑數(shù)據(jù)庫共檢索到1758條記錄,在方劑現(xiàn)代應用數(shù)據(jù)庫共檢索到91條記錄。以“一般模板”進行套錄,保存為HTML格式;再將源文件的HTML格式轉(zhuǎn)為ANSI編碼的TXT格式;最后來自兩個數(shù)據(jù)庫的兩組文本合并。之后經(jīng)標準過濾并整理去重后,共得到有效記錄648條,重新編號后形成待處理源文本,其中取自中國方劑數(shù)據(jù)庫1號源文件的部分文本數(shù)據(jù)如圖1所示。
基于輔助詞群的文本行處理
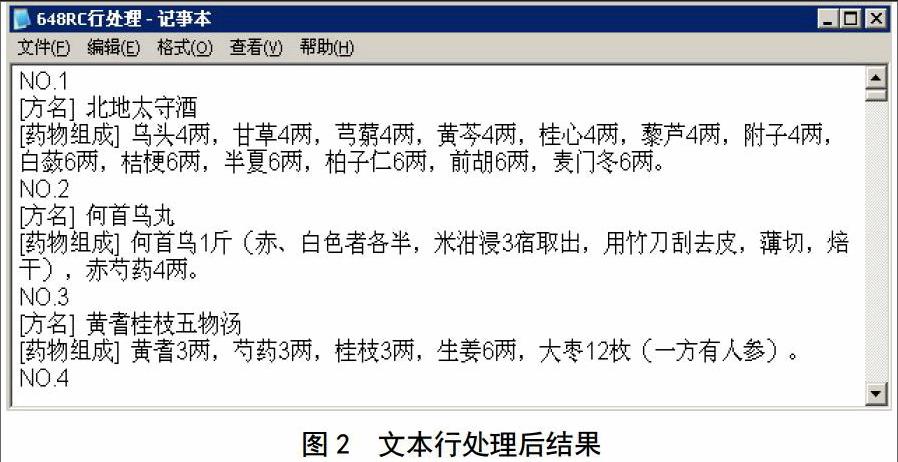
為提取源數(shù)據(jù)中主要關注的方藥信息,使用ROSTCM的基于輔助詞群的行抽取與處理方法對信息進行清理,“方名”和“藥物組成”兩字段除外。輔助詞群設置為[別名][處方來源][劑型][功效][加減][主治][制備方法][用法用量][用藥禁忌][用法用量][各家論述][臨床應用][備注][藥理作用]。經(jīng)過文本行處理后,源文件內(nèi)容轉(zhuǎn)為如下形式,如圖2所示。
基于正則表達式的文本處理
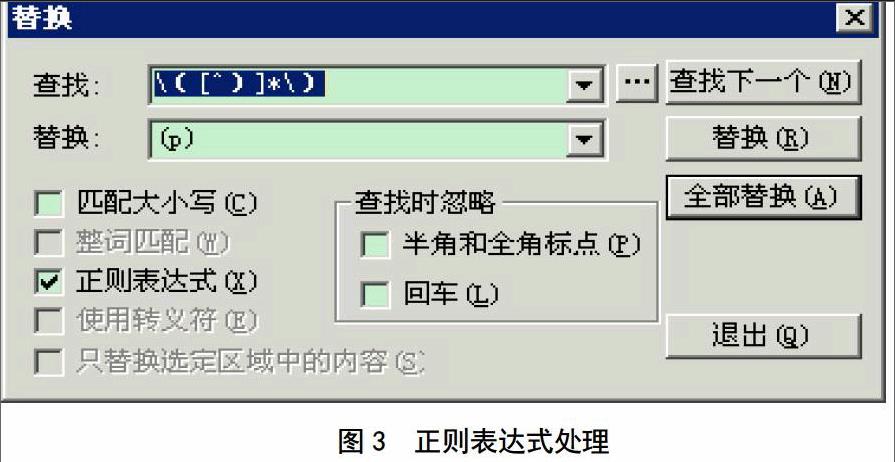
本研究中,因特殊制法和劑量信息暫不考慮,這些信息需要被屏蔽。文本源數(shù)據(jù)的特殊制法部分都采用了中文括號表示,故使用正則表達式替換操作,表達式設置為“\([^)]冰\)”(意為從一個開括號到最近的閉括號)。該操作在支持REGEX的Textpro工具中進行,如圖3所示。
如“何首烏1斤(赤、白色者各半,米泔浸3宿取出,用竹刀刮去皮,薄切,焙干)”,處理完形后,為“何首烏1斤(p)”。
對于劑量信息,首先刪除藥名后的“等”和“各等分”字符,如“川芎等”、“當歸各等分”,去掉后為“川芎”“當歸”;再使用自定義替換功能將中文劑量字符統(tǒng)一轉(zhuǎn)換為數(shù)字字符,如將“半兩”轉(zhuǎn)為“0.5兩”;最后再清除劑量和制法信息。具體做法為:使用正則表達式“\d[^:]冰\:”(意為從一個數(shù)字字符到最近的英文分號),將其替換為英文分號,可將劑量信息去除。
藥物名稱不一致處理
源文本中的“藥物組成”字段為長文本類型,包括各種中草藥的名稱,是非規(guī)范化的數(shù)據(jù),存在不一致問題。中藥品種眾多,名稱復雜,因時代、地域不同而有別,常根據(jù)藥物的形態(tài)、產(chǎn)地、顏色、功效等特征來命名。因此源文本數(shù)據(jù)中同藥異名、同名異藥的現(xiàn)象十分普遍。例如僵蠶處方名有天蟲、僵蟲、白僵蟲等多種名稱,但均實屬同一藥物,應都規(guī)范為僵蠶。
本研究的中藥異名問題,主要參考《中藥學》教材及《中藥大辭典》進行規(guī)范化處理。原則上將長名轉(zhuǎn)為短名,如:明天麻轉(zhuǎn)為天麻,甘菊花轉(zhuǎn)為菊花等,如反之,則會出現(xiàn)如“甘甘菊花”的無效結(jié)果;但有些藥確要將短名化長名,則需確認源文本中藥名前后皆以英文分號結(jié)尾(無劑量等信息):如將“芎”化為“川芎”,“白附”化為“白附子”。
依據(jù)參考書建立藥名轉(zhuǎn)換規(guī)范對照表,使用Textpro的自定義替換功能載入該表,對源文本數(shù)據(jù)批量處理,規(guī)范化藥名,如表1所示。
對于“芎?”這類特殊字符構(gòu)成形式,在部分系統(tǒng)處理完畢后出現(xiàn)未能匹配成功替換情況,可使用單獨替換功能重新處理一遍。 此外,源數(shù)據(jù)中某些藥物與現(xiàn)代中藥存在差別,有一些藥名≥2個中藥合并起來的簡稱,為了統(tǒng)一藥名,需要將其拆分開來,如將蒼白術(shù)拆分為蒼術(shù)、白術(shù)。
源文本數(shù)據(jù)經(jīng)預處理后共得到有效記錄6913味藥,部分結(jié)果如圖4所示。
本研究表明,該預處理方法可成功地對源文本數(shù)據(jù)實施清洗,得到標準統(tǒng)一、無噪聲的數(shù)據(jù),因此是有效的。結(jié)果數(shù)據(jù)可導入書目信息共現(xiàn)挖掘系統(tǒng)(BICOMB)進行方劑名稱和中藥名詞的信息抽取,為進一步進行知識發(fā)現(xiàn)提供了有力的數(shù)據(jù)支撐。
小結(jié)
數(shù)據(jù)清洗就是通過各種措施,從準確性、一致性、無冗余、符合應用的需求等方面提高數(shù)據(jù)的質(zhì)量,實質(zhì)是消除數(shù)據(jù)中的錯誤和不一致。目前,中醫(yī)藥信息處理與分析中的數(shù)據(jù)預處理方法種類繁多,本文試用一種定制的以數(shù)據(jù)清洗為主的數(shù)據(jù)預處理方法對非規(guī)范的原始數(shù)據(jù)進行了有效的處理,是中醫(yī)藥數(shù)據(jù)挖掘和文本領域的一次有益嘗試,希望對后續(xù)研究起到拋磚引玉的作用,并推廣至其他中醫(yī)方劑類文本型數(shù)據(jù)庫數(shù)據(jù)挖掘的數(shù)據(jù)預處理中,為中醫(yī)方劑數(shù)據(jù)挖掘和文本挖掘研究提供新方法和技術(shù)手段。
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
課程教育研究·新教師教學(2016年15期)2017-04-12 14:11:06
電腦知識與技術(shù)(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術(shù)與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫(yī)藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學學報·自然科學版(2016年3期)2016-06-25 06:47:25
