
網絡教育資源中的跨語言知識管理研究
2017-04-12 14:11:06徐昊李慧君秦玥
課程教育研究·新教師教學 2016年15期
關鍵詞:文本挖掘
徐昊+李慧君+秦玥
摘 要:近年來,隨著互聯網與教育的不斷融合,以MOOC為代表的網絡教育平臺在世界范圍內紛紛涌現。本文應用文本數據的獲取與挖掘的技術,對MOOC教育資源的跨語言知識管理方法進行研究,最后實現知識點的跨語言檢索和學習筆記的推薦功能,對基于開放數據的跨語言教育資源共享平臺的構建具有重要意義。
關鍵詞:跨語言;知識管理;MOOC;文本挖掘
G40-057
大型開放式網絡課程(MOOC)自2011年上線以來就倍受人們矚目,它在時間和空間上拓展了教育的范圍,教學形式較為新穎,對學習者來說,MOOC可以激發他們的求知欲、學習積極性和自主性[1]。MOOC的優勢在于便捷和開放,能提供課程的相關學習資源,如講義、筆記、學習小組、論壇等。還有一些英語課程配備了中文字幕,可以幫助中國學習者進行學習。這些在一定程度上提高了學習者的學習效率,促使學習者更快融入在線學習中,最后完成整個課程。
但是我們發現,在線學習也存在一些不完善的地方。以學習資源中的筆記為例,筆記通常按照記錄時間順序顯示,還存在著很多與課程內容無關的信息,這導致學習者不能查看某個知識點對應的筆記,還會被無關信息打擾。而且課程中的中英文知識點之間的關聯也不能體現。為了改進這些情況,讓MOOC平臺為學習者提供更好的用戶體驗,本文研究了如何通過文本挖掘技術和跨語言知識庫的構建,管理MOOC學習資源中的知識。
一、研究現狀和關鍵技術
1.跨語言知識管理
WordNet是由美國普林斯頓大學開發的大規模的匯總英語詞匯知識的在線資源庫。它是一個由普通的詞典內容與計算機科學、心理學成功結合的基于認知語言學的詞典,主要按照詞匯的意義而不是字母順序而組成的“詞匯網絡”[2]。經過20年的研究工作的進展,WordNet已經發展成為國際上非常有影響的英語詞匯知識庫,為知識管理做出了卓越的貢獻。近年來,隨著單一語言知識庫的飛速發展和各語言信息多樣性的增加,跨語言知識管理以及規模性跨語言知識庫的建設將成為必然的趨勢,具有研究價值。UKC (Universal Knowledge Core) 就是這樣一個典型例子。
UKC是一個由意大利特倫托大學開發的擴展的多語種版的WordNet,包括幾十萬個概念。UKC扮演的角色是世界上所有的自然語言的中心樞紐,對于每種語言,都存在一個獨立的LKC (Local Knowledge Core)。每個LKC都有一個源語言(目前為英文)和一個目標語言(世界上任何一種語言),可以獨立發展并且與UKC同步。事實上,LKC是一個本土化進程,通過UKC,所有LKC可以均衡協作、互相使用,多種語言可以得到匹配。
UKC的基本組成部分是詞語,義項,同義詞集和概念[3]。它們的含義如下:同義詞集是一組擁有一個共有的含義的詞語;概念是可以表示一個同義詞集含義的一句描述性質的話;義項是一個詞語的含義;注釋是一個同義詞集的簡短描述。此外,UKC中還有詞目和詞性這兩個
元素。
2.關鍵技術
近半個世紀以來,隨著計算機技術的成熟與發展,人們的生活中大量產生著社交媒體中的文本數據、通訊數據、GPS位置信息、傳感器數據甚至還有圖片和視頻,信息的種類和數量有了爆炸式的增加。但是人們目前面臨的嚴峻的問題是數據豐富而信息貧乏,只是把海量數據存儲起來并不會帶來任何價值,還需要對其進行分析,并從中獲得有用的信息[10]。數據分析基本上都經歷了數據獲取、預處理(清洗)、選擇分析算法、展示結果、評估這一流程。本文的研究基于文本數據的處理與分析,包括文本數據的獲取、清洗、信息挖掘和數據可視化。
獲取數據是數據挖掘的初始步驟。對分析者而言,外部數據比內部數據更容易獲取,獲取外部數據可以通過搜索引擎、開放數據、在聚合數據平臺上購買或下載專業數據集、網絡爬蟲、調查問卷等方式。目前應用較多的外部數據的采集方式的主要有兩種:商業化工具與網絡爬蟲,我們的研究就基于Python爬蟲程序來獲取網絡課程的筆記。
文本挖掘是數據挖掘的一個分支,也是一個由機器學習、統計學、數學、自然語言處理等多種學科交叉而成的領域。顧名思義,就是從大量文本數據中抽取隱含的、未知、可能有用的信息,并對這些數據進行分析,挖掘其中潛在的知識信息[4]。文本挖掘的數據主要是指非結構化文檔和郵件、網頁內容等半結構化數據,常見的算法有關聯規則算法,聚類算法 和分類算法。
數據可視化是指將身居分析的結果以圖形或表格的形式展現出來,以便進一步分析和報告數據的特征以及數據之間的關系。它的首要任務是準確地展示和傳達數據所包含的信息,并用直觀、容易理解和操縱的方式呈現出來。它的基本流程是:將信息映射成可視形式,選擇合適的圖表,刪去不突出的對象或屬性,最終呈現出關鍵屬性的明顯特征。
二、跨語言知識管理的應用
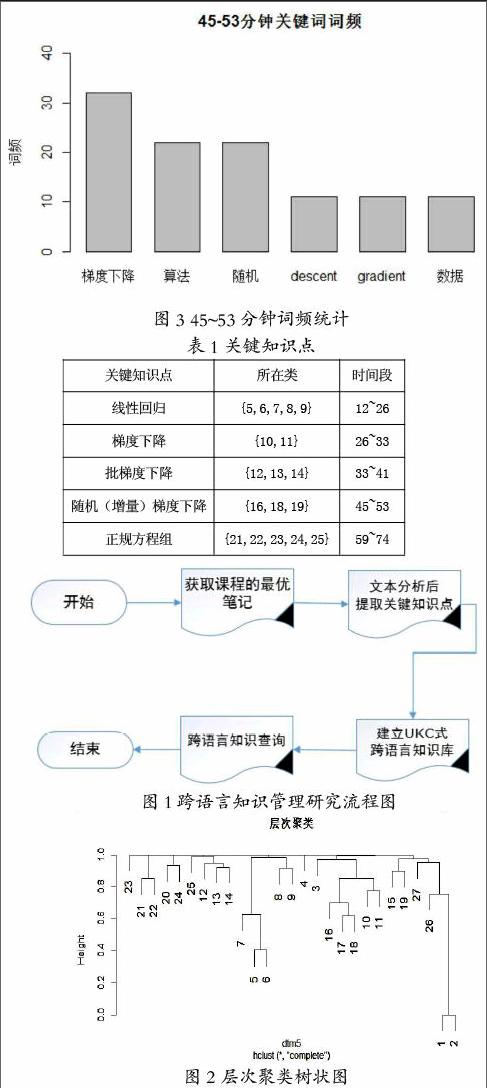
我們研究的數據來自網易公開課中斯坦福大學開設的計算機系課程《機器學習》。首先使用Python爬蟲程序獲取最優筆記內容作為實驗數據,然后用R語言分析文本數據、提取關鍵詞,模仿UKC構建跨語言知識庫,最后實現學習課程時對感興趣的知識點的查詢功能。跨語言知識管理研究的流程如圖1所示。
數據獲取與關鍵知識點提取
首先,利用編寫的Python爬蟲程序從網易公開課的課程頁面獲取前30頁最優筆記,獲得的數據保存成文本格式。
關鍵知識點提取是研究的核心部分,是文本分析算法的具體實現部分,此部分使用R語言完成,步驟如下:
第一步:讀入待處理的文件,對數據進行清理和格式轉換之后,經過排序,得到了共380條可用的筆記;
第二步:由于課程講授是具有連續性的,而且為了方便統計,這里人為地將筆記按每3分鐘為一段進行分段統計。然后對文本進行分詞,然后全部去除文本中包含的標點、數字、多余的空格和停用詞,生成語料庫;
猜你喜歡
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
語文教學之友(2016年5期)2016-06-15 12:15:44
電腦知識與技術(2016年5期)2016-04-14 13:51:02
