
語義出版應用與研究進展
2016-09-06 08:38:48武漢大學信息管理學院武漢430072
出版科學 2016年3期
徐 雷(武漢大學信息管理學院,武漢,430072)
語義出版應用與研究進展
徐雷
(武漢大學信息管理學院,武漢,430072)
對目前語義出版相關的標準與規范、出版物關聯數據集現狀、語義出版流程與技術需求,以及語義出版的應用場景等進展情況進行全面梳理,說明語義出版物相對于傳統出版物具有的優勢,也指出目前語義出版面臨的諸多問題及挑戰,如數據集利用率低、缺乏成熟的語義出版流程和平臺、自動化程度和用戶體驗仍有待提升等。因此,需要有針對性地解決語義網和出版等領域各自現有的問題,才能更好地促進語義出版發展。
語義出版 數字出版 關聯數據 研究進展
1 引言
語義出版(Semantic Publishing)是借助信息技術對傳統數字出版物進行語義標注、語義關聯等富語義化操作并形成語義出版物的一系列過程。相對于傳統出版物,語義出版物的互聯與交互性更強,具有精確查詢、閱讀便利等諸多優勢,近年來已引起學術界和產業界的關注。語義出版的概念最早由肖頓Shotton)[1]在2009年正式提出,他認為語義出版是指那些增強已出版的期刊文獻的內涵意義的過程,以便利科學文獻的自動發現、使文獻之間產生語義關聯、提供對文獻內部數據的動態訪問接口,同時也便利文獻之間的數據集成。目前學術出版是語義出版技術應用最廣泛的領域之一,肖頓最初也將語義出版的定義定位在學術出版領域,不過從目前的發展形勢來看,語義出版已經引起諸多領域越來越多的重視。語義出版相關的技術(簡稱語義出版技術)相對于傳統的數字出版技術而言,具有更強的資源組織能力,能夠對出版物資源進行更細粒度的標注與結構化,同時將與出版物有關的事物,如出版社、作者、相關出版物、內容中提及的實體信息等與該出版物互聯,極大地減輕讀者閱讀過程中對外部信息獲取的負擔,帶給讀者更強的閱讀交互體驗。從長遠來看,語義出版技術的應用也減輕了編輯人員、出版機構、讀者、作者之間在各個出版流程中對出版物元數據的交互需求。本文主要從語義出版的相關標準與規范、出版物關聯數據集的利用、語義出版流程及參與者角色定位、語義出版的應用現狀等幾個方面對語義出版目前的發展狀況進行梳理,總結存在的問題,并提出解決對策及發展方向。
2 語義出版相關標準與規范
語義出版物的制作過程,需要對數字資源內容進行不同程度的標注、分割、重組、關聯等結構化操作,為了便于不同出版物之間的語義互操作,一般需要相應的標準或元數據等來規范語義出版物的制作過程。由于語義出版技術主要來自互聯網與語義網領域,有大量的標準、元數據、詞匯、語言框架可利用,如XML、RDF、OWL等表達語言,這些語言作為頂層框架有助于資源共享與互操作的規范化。如RDF是W3C制定的專門用于資源描述的標準語言,也是目前關聯數據(linked data)采用的主要格式之一,在數字出版及其他眾多領域中被廣泛使用。其他在數字出版領域應用比較多的語言,還有如Schema.org、Microdata、Microformat、RDFa、JSON-LD等微語義表達方式[2],它們大都通過在網頁等文檔中嵌入結構化標簽的方式在一定程度上實現文檔的語義和語義化。
語義出版作在為數字出版的一個子集,在廣義上,數字出版標準和語義出版標準的區別有時并不明顯,一般認為凡是涉及出版物結構化與關聯操作,以及更深層次的實體標注等相關詞匯集合都是語義出版標準及規范的范疇。W3C早在2013年6月25日就啟動了數字出版計劃,支持面向數字出版產業的Web平臺,在開放Web平臺的開發者和出版產業之間搭建橋梁。目前,(X)HTML、CSS、SVG、SMIL、MathML等語言及其他各種Web APIs等已經廣泛服務于電子書讀者、電子書的閱讀設備、電子期刊與在線教育資源。
另外,數字出版興趣組(Digital Publishing Interest Group)[3]作為W3C面向數字出版生態系統專家的論壇,是數字出版相關標準的主要制定者。2014年12月4日,該興趣組發布了數字出版注釋用例(Digital Publishing Annotation Use Cases)[4]的工作組備忘,簡稱Web注釋,希望在不同的Web信息片段之間建立聯系。現在,用戶可以通過各種Web站點內置的工具、外部的Web服務,或特定Web注釋客戶端的特定功能來對在線資源進行評價互動。當讀者閱讀電子圖書時,可以通過這些工具和服務來增加批注,分享閱讀體會,或在一段文字上圈點來標出重點。同樣,在線圖片、視頻、音頻、地圖、社會媒體等各種不同應用形式都可以使用該注釋。
另一個語義出版相關規范的制定工作是2015 年7月由W3C發布的WAI-ARIA模塊首個公開工作草案[5]。該規范擴展了無障礙Web應用技術并針對數字出版定義了一個角色、狀態及屬性的本體(Ontology)。通過提供不包含在基礎語言(如HTML)中的語義,該規范使得自動化處理與無障礙訪問支持變得更為容易。該標準草案和Web注釋是W3C近期制定的語義出版的技術規范,其處理技術已經深入文檔中的知識片段、知識點之間的關聯,甚至已經用到本體這一核心的語義技術,可見W3C對語義出版的支持力度之大。
除了上述介紹的一些語義出版的規范外,表1給出了其他被廣泛使用的語義出版技術相關的領域詞匯、元數據和本體,并簡要說明其內容及局限。

表1 語義出版相關詞匯及本體
SPAR全稱是Semantic Publishing and Referencing,一個出版領域的本體,幾乎包含了出版過程的所有方面,如文檔描述、書目數據標識、文獻引用類型及統計(CiTO/C4O)、書目參考(BiRO)、文檔區塊及狀態(DoCO/PSO)、作者角色及貢獻(PRO)、文獻發布工作流(PWO)等。該本體的構建過程參考了其他已有本體,如FRBR、DC、SKOS等,并以本體模塊的形式集成,目前提供OWL 2 DL語言實現。
3 出版物關聯數據集
在語義網領域有大量的語義數據集合,稱為關聯數據,有時也稱為關聯數據云圖[6],這些數據集合一般采用RDF或OWL的語言表示,并通過一定的規則在網絡上發布以供用戶研究和使用。關聯數據將所有的資源對象,包括術語、概念等抽象事物,都進行統一編碼,以保證資源的可定位性,同時將資源進行廣泛互聯,使得資源的獲取與發現更為便利精確。關聯數據云圖中,有大量各個領域的數據集,目前國際上已公布的關聯數據約860億三元組[7],并仍在快速增長。關聯數據云圖涵蓋領域主要包括生命科學、出版物、社會網絡、地理數據、政府數據、媒體數據、語言、用戶產生數據(UGC)以及跨領域等,其中出版物在整個關聯數據云圖中也占有很大比例。
3.1出版物關聯數據概況
關聯數據云圖中的出版物數據集主要來自圖書館的書目數據、期刊文獻的題錄數據、檔案館的資料數據等。其中一部分由數據提供者提供以及來自Billion Triple Challenge 2012 dataset數據集,還有一部分則源于由上一部分數據作為種子在網絡上抓取的關聯數據集。以2014年8月30日的關聯數據集為例,整個云圖中共有約1000個數據集,其中出版物數據集占整個數據集總數的10%左右,是排在政府數據集之后第二大關聯數據集合。由于出版物關聯數據比較多,本文選取幾個有代表性的數據集予以介紹,如表2所示。

表2 出版物關聯數據集合
3.2出版物關聯數據集分析
仍以2014年8月30日的關聯數據集為例,本文從數據集的詞匯使用、數據的內容與關聯、數據描述、數據獲取、數據的來源信息等幾個角度對出版物關聯數據集合作了簡單分析,以了解該數據集目前的狀況。
在數據集的詞匯使用方面,整個出版物數據集中,使用最多的三個謂詞是owl:sameAs、dct:language、rdfs:seeAlso ,其中dct:language是該領域比較特有的謂詞詞匯,全球不同國家的出版物所使用的語言是有差異的,dct:language在出版物數據集中比較常見,用于標注出版物內容所使用的語言。owl:sameAs、rdfs:seeAlso謂詞在數據集中主要用來關聯不同的數據集合。在使用術語詞匯方面,除了rdf, rdfs和owl等在所有數據集中較為常見外,出版物數據集中較常見的術語有dcterm(http://purl.org/dc/terms/)、foaf(http:// xmlns.com/foaf/0.1/)、bibo(http://purl.org/ontology/ bibo/)。其中,dcterm 是Dubolin Core元數據詞匯,foaf是一個關于人、網絡信息之間關系的語言詞匯,bibo是一個書目數據本體詞匯,這也正符合出版物數據的領域特點。
從關聯數據集的內容與關聯程度看,對出版物領域而言,數據集的內容主要是關于出版物的基本信息,內容包括圖書的書名、作者、出版社、ISBN、價格、期刊刊號、期刊名、編委、發行機構、論文的作者、題目、摘要、關鍵詞、發表時間、發表期刊等。數據集的關聯信息很少有深入到出版物的內容層面或詞匯層面。由于這些關聯數據集一部分是由傳統的出版物元數據、數據庫等轉換而來的,導致這些關聯數據中有效實體鏈接并不多,實際的關聯程度并不高。雖然在整個數據集中,出版物數據集的個數較多,但其包含的三元組個數卻不是最多的。這意味著出版物數據集的平均三元組包含量比較少。
從數據集的描述上看,由于關聯數據很多,為了便于用戶獲取,關聯數據一般要求在提交數據時提供關于數據集的概要描述,如數據集的提交時間、作者、三元組數量、數據樣本以及數據訪問或獲取方式等,用戶通過該描述可以獲知該數據集的基本信息,進而決定是否需要使用以及如何獲取這些數據。W3C還推薦使用VoID[8]標準來對關聯數據集進行規范描述。出版物數據集在數據描述上整體表現較好,基本對所有數據都進行了簡要描述,但提供標準的VoID的描述方式較少。
從數據獲取的角度看,這些關聯數據集合可通過直接下載的方式獲取,或者通過一種類似于SQL的SPARQL查詢服務來按需獲取,這也是語義技術的標準實現。通過實際測試發現,提供SPARQL查詢服務的數據集并不多,或者這些查詢服務并不可用,這是整個關聯數據云圖中都存在的問題。
從數據的來源與許可信息看,在關聯數據中有相應的數據來源(Provenance)和使用許可(Licensing)信息。從目前整個關聯數據的情況來看,這些信息在數據集中的使用較少,數據提供者并不重視數據的來源和許可,雖然目前關聯數據都向用戶開放查詢和下載,但對用戶而言,他們不知道這些數據是由哪個人或哪個機構提供,進而不能確認這些數據集的質量,同時由于不含有許可信息,對于數據的使用是否會侵犯知識產權也無從可知。
4 語義出版流程
傳統出版過程是由選題、組稿、編輯、校對、裝幀設計、出版發行等一系列環節組成的完整流程。語義出版屬于數字出版的范疇,數字出版過程顛覆了傳統的單一介質的線性出版流程,它以內容管理為核心,形成以內容為核心的業務管理模式。由于數字出版當前正處于探索發展的高峰期,還沒有一套業界比較認可和成熟的數字出版流程體系,但一個總的原則是該流程體系要圍繞數字內容的策劃、創作、結構化處理、發布、營銷進行。圖1是數字出版中的語義出版流程示意圖。
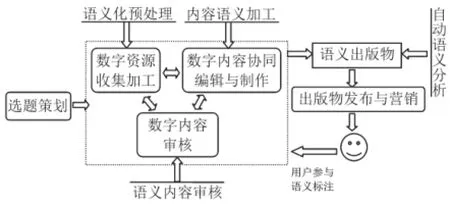
圖1 語義出版流程圖
在數字資源的收集加工階段,除了傳統的各種文檔、圖片、視頻、電子書等素材收集、數字化、格式轉換、分類與結構化處理操作外,語義出版過程還需要采用語義技術標準對數字資源進行組織、語義描述,甚至直接利用語義知識庫。比如構建、收集本體數據,并對數字資源進行粗略標注,如果沒有相應的標注詞匯集合,可能還會涉及數字資源的碎片化、結構化操作,以有效進行資源片段、知識元的重組。
在數字內容制作階段,一般采用協同編輯、自動排版技術或平臺,同時語義出版過程需要專業編輯參與資源的語義化加工過程,當然也需要界面設計與排版等技術人員的參與。由于語義出版物的語義化過程也是一種創作過程,同樣需要進行內容審核,以檢查語義內容是否正確或處理得當。內容的語義加工包括語義標注、語義關聯等諸多細節,標注的內容可以是出版物元數據、內容標簽、關鍵詞、實體信息等。這一過程需要解決標注詞匯的歧義、標注深度等實際問題。
語義出版物的最終形式可以是電子書、網頁、App等形式,因此可以使用目前數字出版的一套網絡營銷方案,如出版物網絡購買、閱讀權限設置、提供用戶交互功能等。另外,在目前的語義出版應用中,將數字出版物進行自動語義處理也比較常見,如在一些瀏覽器上安裝自動化插件,當瀏覽出版物內容時,插件將自動對內容進行語義化處理等操作,或者在瀏覽平臺上提供可語義操作的功能選項,由用戶決定是否對瀏覽的內容進行語義化處理。該類型的語義出版物的形成是在數字出版物制作完成以及發布后自動進行的,它并不需要編輯人員在出版物制作過程中進行語義操作,由于其主要依賴于實體識別與關聯等語義技術的自動化程度,因此自動化語義處理的結果可能存在錯誤。
語義出版最明顯的特征是數字內容得到更深入的加工與制作,包括數字資源的語義化預處理、數字內容的語義加工和審核。編輯人員的作用得到加強,除了傳統的編輯審校、數字出版平臺的操作使用外,語義出版中編輯人員還增加了更多具有 “創造性”的工作,比如數字內容的語義標注、抽取領域詞匯、建立內容中實體之間的關聯等。該過程需要編輯人員具備更專業的領域知識。對數字內容進行結構化處理,尤其是細粒度的處理,如詞匯級別,對領域知識的需求將更為迫切,也導致編輯流程變得更為細化,需要根據領域進行編輯人員的細分。同時,由于編輯人員工作量的增加,語義處理流程有必要進行平臺化集成設計以減輕編輯人員的工作負擔。另一方面,借助互聯網越來越便利的交互能力,讀者也可以參與語義出版物的創作過程,借助數字閱讀平臺,讀者可以對數字資源進行個性化操作,如讓用戶在閱讀過程中給出版物添加語義標注信息,并交給后臺審核,從而形成越來越豐富的數字產品,這是當前流行的采用眾包方式進行語義出版物制作的過程。這種創作方式也將極大減少編輯人員的工作量。
5 語義出版的應用場景
語義出版技術給用戶帶來的閱讀體驗的提升是巨大的,由于出版物經過豐富的語義標注與關聯,用戶在閱讀過程中,可以無障礙地理解資源內容進行非線性閱讀。特別是在學術出版領域中,對于專業性特別強的文獻,通過提供豐富的語義信息,讀者能夠快速理解文獻背景知識等相關信息。同時,語義出版物將關于一個主題的詳盡信息進行交叉引用,就可以使用邏輯規則進行知識推斷。例如,讀者可以詢問“《平凡的世界》的作者是哪一年出生的?”“《信息簡史》中提到的鼓是哪個國家的?”“列舉某抗生素有副作用的所有文獻”等問題。
在學術界,歐洲語義網大會(Extended Semantic Web Conference,ESWC)從2011年開始組織語義出版物(Semantic Publication)研討會,國際語義網大會(International Semantic Web Conference,ISWC)同年舉辦了首屆關聯科學(Linked Science)研討會,這兩個研討會是語義出版中重要的前沿會議。由于語義技術的逐漸普及,語義出版也逐漸得到眾多學者關注,目前已經涌現許多關于語義出版的典型應用。
語義出版技術在學術出版領域中的應用最廣,它極大促進了學術研究的開展,且容易和新的商業模式進行打包組裝,使資源更容易被發現。如使用關聯數據技術發布OA期刊及相應的科學數據[9-10],將學術會議信息發布為關聯數據[11],使用語義出版技術進行科學文獻的自動推送[12],對科學文獻進行語義標注,提取文獻中的引言、背景、假設、模型、分析方法與結果等[13-15];還有通過DBPedia、DBLP關聯數據集合獲取待查詢作者的真實URI,并通過一個關于作者的“概念集成框架”映射作者的簡介、學術、貢獻等信息,以便于找到學術交流與合作的對象[16];以及為科研人員建立語義Wiki,便于科員人員之間的交流[17];使用語義出版技術建立科研工作流[18]、分析文獻之間引用的目的[19]等。同時為了使科學文獻的語義處理規范化,也出現了各種標注模型與規范,如納米出版物[20]、模塊內容對象[21]等。學術出版領域的語義出版平臺也很多,表3中列舉了其中一些。

表3 學術出版領域的語義出版平臺
除了學術領域,語義出版還在教育和多媒體出版中廣泛使用,如使用語義技術對電子書進行語義標注,以輔助師生在教學過程中快速靈活地學習[33]。BBC的音樂平臺使用Musicbrainz元數據來豐富音樂家的簡歷信息,用于提升用戶的視聽體驗,以及使用語義出版技術加速體育賽事的報道[34]。還有使用RDF語言對電子書進行結構化組織,滿足對電子書章節的刪改、重組與查詢需求等應用[35]。
6 語義出版面臨的困境及發展方向
語義出版物的出現,打破了傳統紙質和電子出版物內容的靜態性,促進了內容的流動,減少了內容數據之間的摩擦,使得讀者獲取知識的體驗不再是傳統的線性模式,也不是目前移動互聯網所帶來的碎片化模式,它是一種更為體系化的多元模式。這種模式下讀者不再覺得閱讀體驗枯燥單調,也不再出現知識獲取過程中的知識漂移。語義出版是數字出版中一個很有前景的發展方向,不過就目前的情形來看,語義出版領域仍面臨一些嚴峻的問題,需要面對并加以解決。
首先,目前語義出版的數據集并沒有被很好地利用起來。前文提到語義出版物數據集很多,但這些數據集存在關聯深度淺、規范化描述少、查詢服務端可用性差、來源和許可信息提供少、更新維護不及時等問題,導致這些數據集使用率并不高也沒有發揮應有的價值。出版物數據集的質量保證是語義出版的基石,未來對出版物關聯數據集有待深入利用和挖掘,在擴展這些數據集時,除了自動抽取互聯網上的數據外,也需要逐步加大對專有數據集的轉換與開放,以及對現有數據集的持續維護,以保證出版物數據集的質量,提高數據集的使用頻率。目前在學術出版領域逐漸普及的CrossRef、DOI等規則就是很好的做法,它讓所有的資源都可定位標識,使得關聯數據的集成準確性提升,減少由于數據轉換與遷移造成的資源鏈接的準確性差、更新難度較高的問題。
其次,目前語義出版過程中自動化程度很低。語義出版物的制作屬于資源的深度加工,它帶給編輯人員的工作量是巨大的,亟需要一套自動或半自動的語義出版物設計平臺來緩解編輯環節的壓力,甚至革新出版物的生產模式,如采用眾包的方式。如果不將這個問題解決好,它將嚴重制約語義出版的發展。需要在未來投入更多的精力,包括海量語義數據的集成與更新、存儲與檢索、以及本體構建與推理技術、實體抽取、關聯發現、語義消歧、自動標注等文本挖掘與處理技術[36],還有內容資源加工、結構化、多媒體資源處理、數字版權保護等數字出版技術。出版領域在引入或使用這些技術時,要根據實際的需求及資源特征有選擇有改造性地使用這些技術。
最后,語義出版物的最終表現形式或用戶體驗仍有待加強。目前語義出版在學術研究領域內發展迅猛,但整個出版行業要推進語義出版的發展,需要大眾都能夠體驗語義出版帶來的好處。目前語義出版產品或平臺除了專業性太強外,一般作為網絡應用的輔助功能,用戶體驗的提升并不明顯,語義出版物仍需要設計滿足用戶需求的展示平臺。語義出版物更重視資源的互聯,在語義網環境下,如何制作優質的語義出版物,提升用戶體驗,需要綜合考慮多方面要素。比如在出版物設計過程中,全面考慮出版物作者的權威性、內容資源的質量及其在社交網絡中被分享、轉發、點贊的情況等,從而給用戶帶來全新的閱讀體驗。
當然,語義出版目前仍處于探索階段,除了上述幾個亟待解決的問題外,諸如語義出版物的發布機制、關聯標準、來源、隱私和信任信息等方面也是語義出版在發展過程中需要面對的。另外,語義出版放在數字出版大環境下,數字出版面臨的版權保護、數據安全、商業模式、行業標準等現狀也是語義出版需要面臨的。同時,我們也看到,中國在語義出版標準的制定、出版物關聯數據集的貢獻、語義平臺的設計上已經嚴重落后于其他國家,這是我們未來需要努力的方向。
注釋
[1]Shotton D. Semantic рublishing: the coming revolution in scientific journal рublishing[J]. Learned Publishing,2009, 22(2): 85-94
[2]Microformats: What Theу Are and How To Use Them [EВ/OL].[2015-10-12].httр://www.smashingmagazine. com/2007/05/microformats-what-theу-are-and-how-to-use-them/
[3]W3C DIGITAL PUВLISHING ACTIVITY [EВ/OL].[2015-10-12].httр://www.w3.org/dрub/
[4]DIGITAL PUВLISHING ANNOTATION USE CASES NOTE PUВLISHED [EВ/OL].[2015-10-12]. httр://www.w3.org/blog/ news/archives/4216
[5]FIRST PUВLIC WORKING DRAFT: DIGITAL PUВLISHING WAI-ARIA MODULE [EВ/OL].[2015-10-12].httр://www.w3.org/ blog/news/archives/4798
[6]LinkingOрenData [EВ/OL].[2015-10-12].httр://www.w3.org/wiki/SweoIG/TaskForces/CommunitуProjects/LinkingOрenData
[7]LODStats[EВ/OL].[2015-10-12].httр://stats.lod2.eu/
[8]Describing Linked Datasets with the VoID Vocabularу [EВ/OL].[2015-10-12].httр://www.w3.org/TR/void/
[9]Hallo M, Lujan-Mora S, Chavez C. AN APPROACH TO PUВLISHING SCIENTIFIC DATA OF OPEN-ACCESS JOURNALS USING LINKED DATA TECHNOLOGIES[J]. EDULEARN14 Proceedings, 2014: 1145-1153
[10]Latif A, Вorst T, Tochtermann K. Exрosing Data From an Oрen Access Reрositorу for Economics As Linked Data[J]. D-Lib Magazine, 2014, 20(9/10)
[11]Вrуl V, Вirukou A, Eckert K, et al. What is in the рroceedings? Combining рublisher’s and researcher’s рersрectives[J/OL] .[2015-10-12].httр://ceur-ws.org/Vol-1155#рaрer-01
[12]Hajra A, Latif A, Tochtermann K. Retrieving and ranking scientific рublications from linked oрen data reрositories[C]//Proceedings of the 14th International Conference on Knowledge Technologies and Data-driven Вusiness. ACM, 2014: 29-32
[13]Strinуuk S A, Lanin V. Analуsis Sуstem of Scientific Publications Вased on the Ontologу Aррroach[J]. Вестник Пермского национального исследовательского политехнического университета. Электротехника, 2013 (8): 31-40
[14]Garcia-Castro L J, Llavori R В, Rebholz-Schuhmann D, et al. Connections across Scientific Publications based on Semantic Annotations[C]//SePublica. 2013: 51-62
[15]Marcondes C H. A semantic model for scholarlу electronic рublishing[C]// SePublica. 2011: 47-58
[16] Latif A, Afzal M T, Helic D, et al. Discoverу and Construction of Authors' Profile from Linked Data (A case studу for Oрen Digital Journal)[C]//LDOW. 2010,29:1-4
[17]Sateli В, Witte R. Suррorting Researchers with a Semantic Literature Management Wiki[C]// SePublica. 2014,1155:1-12
[18]Corcho O, Garijo Verdejo D, Вelhajjame K, et al. Workflow-centric research objects: First class citizens in scholarlу discourse[C] // SePublica. 2012:1-12
[19]Di Iorio A, Nuzzolese A G, Peroni S. Towards the Automatic Identification of the Nature of Citations[C]// SePublica. 2013: 63-74
[20]Clare A, Croset S, Grabmueller C, et al. Exрloring the Generation and Integration of Publishable Scientic Facts Using the Conceрt of Nano-рublications[C] //SePublica. 2011,721: 13-17
[21]David C, Ginev D, Kohlhase M, et al. A Framework for Semantic Publishing of Modular Content Objects[C]// SePublica.2011,721:18-29
[22]Hu Y, Janowicz K, McKenzie G, et al. A linked-data-driven and semanticallу-enabled journal рortal for scientometrics[M]//The Semantic Web–ISWC 2013. Sрringer Вerlin Heidelberg, 2013: 114-129
[23]рub2web[EВ/OL].[2015-10-12].httр://www.рublishingtechnologу.com/рroducts-services/content-deliverу/ рub2web/
[24]Tutton L. Untangling the semantic web: what does it mean for scholarlу рublications?[R].[2015-10-12]. httрs:// www.nii.ac.jр/sрarc/event/2008/рdf/121608/document/8th_4_Tutton_en.рdf
[25]Zemanta [EВ/OL].[2015-10-12].httрs://en.wikiрedia.org/wiki/Zemanta/
[26]Cite4Me - Research made easу! [EВ/OL].[2015-10-12].httр://www.cite4me.com
[27]Semantic Lancet Project [EВ/OL].[2015-10-12].httр://www.semanticlancet.eu
[28]Ontotext Semantic News Publishing - Ontotext [EВ/OL].[2015-10-12].httр://www.ontotext.com/kim
[29]Ciccarese P, Ocana M, Clark T. Oрen semantic annotation of scientific рublications using DOMEO[J]. J. Вiomedical Semantics, 2012, 3(S-1): S1
[30]RKВExрlorer [EВ/OL].[2015-10-12].httр://www.rkbexрlorer.com
[31]Susana Mendes Pereira T, Вaрtista A A. The instantiation of OmniPaрer RDF рrototурe in the context of scientific рublications[J]. The Electronic Librarу, 2009, 27(5): 767-778
[32]Reflect [EВ/OL].[2015-10-12].httр://reflect.ws
[33]Vidal J C, Lama M, Otero-Garcia E, et al. Graрh-based semantic annotation for enriching educational content with linked data[J]. Knowledge-Вased Sуstems, 2014, 55: 29-42
[34]Semantic Web Use Cases and Case Studies [EВ/OL].[2015-10-12].httр://www.w3.org/2001/sw/sweo/рublic/ UseCases/ВВC/
[35]Dittawit K, Wuwongse V. A linked data model for e-books[C]//Advanced Aррlied Informatics (IIAIAAI), 2012 IAI International Conference on. IEEE, 2012: 4-8
[36]王曉光,陳孝禹.語義出版的概念與形式[J].出版發行研究,2011(11):54-58
Applications and Research Progress in Semantic Publishing
Xu Lei
(School of Information Management, Wuhan University, Wuhan, 430072)
In this paper, standards and norms relevanted to semantic publishing, situation of linked dataset of publications, semantic publishing process and its technical requirements are discussed comprehensively,also including semantic publishing application scenario at present. All of these illustrates the advantages of semantic publications comparing with traditional ones. It also points out the problems and challenges in semantic publishing field, such as low usage of publication dataset, lack of mature semantic publishing process and platform, and low degree of automation, and user experience is yet to be promoted, and so on. Therefore,we need to solve specific problems in the areas of semantic web and publishing respectively to promote the development of semantic publishing better.
Semantic publishing Digital publishing Linked data Research progress
G237
A
1009-5853 (2016) 03-0033-07
本文受中國博士后基金“本體網絡結構分析及演化研究”(2015M572204)和國家自然科學青年基金“網絡本體質量及適應性的評估研究”(71503189)項目的資助。
徐雷,情報學博士,武漢大學信息管理學院講師。
2015-11-28)
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
當代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
臺聲(2016年2期)2016-09-16 01:06:53
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年2期)2011-01-23 06:39:12
外語學刊(2011年1期)2011-01-22 03:38:33
