少數民族語言信息資源計算機輔助閱讀系統架構設計
2016-11-21 01:22:08趙生輝西藏民族大學管理學院
圖書館理論與實踐 2016年10期
趙生輝(西藏民族大學管理學院)
少數民族語言信息資源計算機輔助閱讀系統架構設計
趙生輝
(西藏民族大學管理學院)
利用信息技術消減語言文字的差異性所帶來的溝通障礙是民族地區信息資源管理迫切需要解決的問題。在機器翻譯技術之外,計算機輔助跨語言閱讀系統(CARS-IRMLC)是民族地區政府公共服務機構為只掌握了國家通用語言服務對象所特別設計的跨語言閱讀環境,該系統以“簡化通用語義代碼體系”作為多種少數民族語言同義語素的定位、關聯、檢索的邏輯基礎和語義信息轉換的邏輯中介。目前CARS-IRMLC在我國民族地區政府機關和圖書館、檔案館、博物館等公共文化機構具有廣泛的應用前景。
少數民族語言;信息資源共享;計算機輔助閱讀;跨語言信息檢索;機器翻譯
目前,我國正在使用的少數民族語言在80種以上,正在使用的少數民族文字在30種左右。[1]語言文字的多樣性,在造就中華民族文化豐富多彩特征的同時,也給不同民族人群之間的相互理解帶來了諸多不便。利用信息技術消減語言文字的差異性所帶來的溝通障礙,是民族學、語言學、計算機科學、信息管理等領域研究人員一直試圖解決的問題。
在少數民族語言文字信息處理技術領域,于洪志研發了藏漢雙語信息系統;[2]戴玉剛研發了以中文為核心的多語言基礎資源庫;[3]丁曉青研發了少數民族文字的統一識別平臺;[4]塔娜等構建了面向跨語言信息檢索的蒙漢語義詞典;[5]艾斯卡爾·艾木都拉開發了基于維吾爾語和漢語的雙語檔案信息管理系統;[6]由國內多家研究機構共同參與的國家科技支撐計劃項目“少數民族語言文字信息處理共性關鍵技術研究與示范應用”取得多項成果。[7]
在多民族語言信息資源共享技術方面,研究人員一直寄希望于少數民族語言文字機器翻譯(Machine Translation)技術的發展和成熟。然而,由于人類自然語言的復雜性,機器翻譯的效果與人們的期望和需求還有較大的差距。受到市場規模、語料庫規模、研究人員數量、經費支持力度等多種因素的制約,目前我國少數民族語言文字機器翻譯技術整體上還處在初級階段,研究成果也僅限于部分小型實驗系統,無法滿足廣泛應用的需要。在機器翻譯技術之外,發展面向讀者現實需求的計算機輔助跨語言閱讀體系就成為一種更為經濟和現實的選擇。
少數民族語言信息資源“計算機輔助跨語言閱讀”(Computer-Aided Cross-languages Reading,CACLR)系統是我國民族地區政府公共服務機構為只掌握了國家通用語言服務對象所特別設計的跨語言閱讀環境。在該環境中,用戶可以用自己熟悉的國家通用語言文字作為工具,檢索由各種少數民族語言文字生成的信息資源,閱讀和理解這些信息資源的主題和內容,并可以根據系統自動生成的閱讀建議,選擇進行人工高精度翻譯、概要瀏覽或者放棄閱讀等操作。少數民族語言信息資源計算機輔助跨語言閱讀系統在我國民族地區政府機關和圖書館、檔案館、博物館等公共文化機構具有廣泛的應用前景,也適用于互聯網少數民族語言信息資源的跨語言輔助閱讀,實施后對我國民族團結的戰略格局將產生深遠的影響。
1 需求分析
對于只掌握了國家通用語言文字的用戶而言,閱讀和理解少數民族語言信息資源會遇到各類困難和障礙,如:無法了解所看到的少數民族語言信息資源的主題和內容;無法搜集到盡可能全面的同一主題、多種語言文字的信息資源;無法判斷信息資源是否符合自己的信息需求等。這些困難和障礙是用戶基于自身知識儲備無法有效解決的,只能求助于專業的翻譯人員或相關領域專家;在沒有找到合適的翻譯人員或者領域專家時,只能暫時放棄對該信息資源的閱讀。計算機輔助閱讀則為用戶提供了一種新的選擇,改善用戶在閱讀少數民族語言信息資源時的無助感,獲得更好的閱讀體驗。一般而言,少數民族語言信息資源的跨語言閱讀需求主要有以下方面。
1.1少數民族語言信息資源的跨語言檢索需求
跨語言信息檢索(Cross-LanguageInformation Retrieval)是指用戶以自己熟悉的語言文字來構建和提交檢索提問式,系統據此檢索出符合用戶需求的多個語種的相關信息。跨語言信息檢索的出現,主要是為了應對互聯網多語言信息資源共存對信息查全性的要求,使得內容符合用戶需要的多個語種的信息資源都可以被檢索到。作為信息檢索非常重要的研究領域,跨語言信息檢索從20世紀90年代中期開始得到了廣泛的關注,一些商業公司已經可以提供英語等使用較為廣泛的語言文字的多語言信息檢索服務。在我國少數民族語言信息資源閱讀過程中,用戶同樣有著跨語言信息檢索需求,如要查詢我國少數民族節日相關信息,使用藏文、蒙古文、維吾爾文作為記錄文字的信息資源都應該被檢索到。在現實生活中,用戶有少數民族語言信息資源的閱讀需求時,找到可以翻譯單一語種信息資源的專業人員相對容易,但是要找到同時熟悉多種語言文字的翻譯人員就非常困難,更不要說找到同時可以看懂數十種少數民族語言文字的人了。因此,少數民族語言信息資源跨語言檢索正是發揮了計算機在信息檢索領域的優勢,使用戶通過一次檢索就可以得到盡可能全面的信息檢索結果。
1.2少數民族語言信息資源的語義提示需求
少數民族語言信息資源在閱讀過程中最大的閱讀障礙是用戶對少數民族語言文字符號的語義內涵無法識別和理解,如果計算機能夠提供相應的語義提示功能,則可以大幅度降低跨語言閱讀的難度。“語義提示”(Semantic Cue)與文本的精確翻譯有著很大的不同,“語義提示”一般只限定在詞匯和簡單句型層面,即可以讓用戶通過提示信息了解信息資源的主題和概要內容,很少涉及語法問題,其技術實現的難度因此要低一些。語義提示的方式有多種,如利用鼠標的懸停菜單進行語義提示,在信息文本當中進行語義混雜提示以及采用源語言和目標語言的雙語對照排列進行語義提示等。由于“語義提示”基本上相當于源語言和目標語言等價語素的直接翻譯,因此,語義提示信息的位置往往不符合語法規則,順序連讀往往不能準確反映源語言的真實語義,但作為一種計算機輔助閱讀的手段,這種方法基本能夠滿足瀏覽和判斷主題相關性的需求,因而也是一種可以接受的解決方案。
1.3少數民族語言信息資源的閱讀建議需求
用戶在進行少數民族語言信息資源跨語言閱讀時,只能進行語義信息的概要瀏覽,對于各類信息資源與用戶需求的符合程度往往不能做出精確判斷。計算機輔助閱讀則可以通過需求模型的方法有效解決這一問題。如,系統可以允許用戶輸入若干檢索詞并給出其權重,在檢索過程中系統可以計算每個信息資源中相關詞匯的詞頻信息,并根據需求模型計算出符合程度指數,從而可以對檢索到的所有結果按照與需求的符合程度進行排序。基于上述的需求符合程度指數,系統可以進一步為用戶自動生成閱讀建議。例如非常重要的信息資源,建議用戶找專業翻譯人員進行高精度翻譯工作,一般性信息資源則建議用戶進行全文瀏覽,低度相關的信息資源建議用戶瀏覽標題和元數據進行即可。為了減少用戶尋找專業翻譯人員的難度,系統同時可以通過網絡方式提供用戶與翻譯人員進行相關服務提交和執行的在線平臺。
1.4少數民族語言信息資源閱讀的文化支持需求
我國少數民族文化極其豐富多彩,傳統語言文字當中蘊含了大量體現本民族文化特征的詞匯,這些詞匯的國家通用語言詞義往往是根據少數民族詞匯的發音進行翻譯的,即使計算機閱讀系統提示了其國家通用語言的詞義,用戶還是無法準確理解其內涵。因此,少數民族語言信息資源的計算機輔助閱讀系統應該為用戶的這種需求提供一定程度的支持,如可以建立少數民族文化常用術語解釋列表,檢索結果當中提供與該術語的鏈接信息,從而幫助用戶進一步了解該術語所描述語義對象的準確信息。
1.5少數民族語言信息資源的移動輔助閱讀需求
隨著我國移動通信技術的飛速發展,移動互聯網已經成為用戶進行信息交互的重要方式,隨著時間的推移其發展空間還在日益擴大,可以預見未來基于移動通信設備的少數民族語言計算機輔助閱讀模式將成為一種新的潮流。在移動互聯網環境下,用戶的少數民族語言信息資源管理需求可以得到全方位的支持,如用戶在圖書館看到某語種少數民族語言文獻后,只要進行簡單設定,再拍照上傳,系統就可以識別該文獻的文字信息,并啟動語義提示功能給出該文獻詞匯的國家通用語言的語義提示信息。移動互聯網使得少數民族語言信息資源計算機輔助閱讀的應用范圍得到了拓展,用戶進行閱讀的時間地點不再是固定的某一機構,如用戶在我國民族地區看到一個使用少數民族文字記錄的地理標記或者在某景點看到一個少數民族文字牌匾,均可以將其拍照上傳以獲得國家通用語言文字的語義提示。
上述需求中,跨語言檢索需求、語義提示需求、閱讀建議需求和文化支持需求屬于基本需求,是少數民族語言信息資源計算機輔助閱讀系統開發必須考慮的問題。基于移動通信設備的少數民族語言信息資源計算機閱讀輔助需求屬于高級階段的需求,要在滿足前四個基本需求情況下,相關技術和方法的發展成熟后才能完全實現,如少數民族語言文字自動識別技術,少數民族語言信息資源語義信息的自動檢索和標注技術等,因而可以認為是一種未來的目標模式。
2 技術原理
少數民族語言信息資源計算機輔助閱讀的關鍵任務是研究和開發“少數民族語言信息資源計算機輔助閱讀系統”(CARS-IRMLC),該系統實現信息資源跨語言檢索和少數民族語言國家通用語言語義提示的主要原理是基于專門構建的多民族語言“簡化通用語義代碼體系”(Simplified Universal Semantic Code System,SUSCS)。
2.1多語言語義轉換的主要方法
計算機輔助跨語言閱讀的關鍵是實現不同語種語言文字等價語素之間的語義轉換,目前在機器翻譯領域常用的技術手段主要有:機讀雙語詞典(Machine-Read Bilingual Dictionary)、雙語語料庫(Bilingual Corpus)、多語言敘詞表(Multilingual Thesauri)、多語言本體(Multilingual Ontology)等,這些方法主要是為實現語言文字的對等翻譯而設計的,需要有專門的語言學知識作為基礎,并且要經過長期的積累和優化才能最終投入應用。我國少數民族語言文字機器翻譯技術目前還處在初級階段,能夠支持機器翻譯的技術資源非常少,為了實現少數民族語言信息資源跨語言輔助閱讀需求,本文以各少數民族語言文字雙語詞典為基礎,提出了一種基于通用代碼體系實現多語種信息語義轉換的方法。
2.2通用語義代碼的概念與功能
“通用語義代碼”是對“通用語義空間”(Universal Semantic Space)的一種形式化表述方式。這里的“通用語義空間”,是指人類社會的各種自然語言所描述的語義對象及其關系所構成的虛擬空間,是客觀世界和思維活動各類語義對象的總和。“通用語義空間”與各種自然語言的“語義空間”之間是“表現”和“映射”關系:一方面,通用語義空間是一種觀念意義上的空間,它無法脫離自然語言空間而獨立存在,通用語義空間的語義對象必須通過某種具體的自然語言才能展現出來從而被人們所理解;另一方面,任何一種自然語言本質上是對“通用語義空間”進行映射的結果,相當于以某種具體的自然語言所展現的“通用語義空間”視圖。從“通用語義空間”視角看來,機器翻譯方法實際上是實現“通用語言空間”不同語種“自然語言視圖”的切換過程。那么,如果可以用代碼表達通用語義空間的語義對象,并基于這一代碼,實現多個自然語言視圖當中等價語素的語義關聯,則可以非常方便地實現這些等價語素不同語種語義之間的切換,可以大大降低不同語種語言文字等價語素轉換的難度和執行速度。綜上所述,“通用語義代碼”(Universal Semantic Code,USC)是一種為實現多語言信息交流而專門設計的人工編碼體系,該體系獨立于任何一種具體的自然語言,其存在主要是為多種自然語言同義語素的定位和關聯提供邏輯基礎,也是多種自然語言一體化信息檢索和語義共享的邏輯中介(見圖1)。
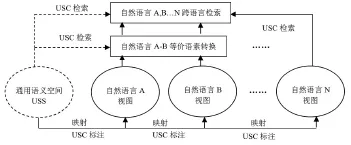
圖1 多語言通用語義代碼的技術原理
2.3多民族語言簡化通用語言代碼體系概述
“多民族語言通用語義代碼體系”是專門針對我國多民族語言信息資源共享需求而設計的代碼體系,是實現我國多民族語言信息資源語義轉換的核心技術和基礎資源。鑒于通用語義代碼設計工作的復雜性和長期性,在研究初期可以根據需求對通用語義代碼體系進行適度簡化,如,通用語義編碼主要針對等價詞匯和常用等價例句,原則上不對語法現象進行編碼,從而大大降低了編碼體系構建工作的難度。本文將這種經過了適度簡化的人工編碼體系稱為“多民族語言簡化通用語義代碼體系”(Simplified Universal Semantic Code System,SUSCS)。
“通用語義代碼”本身并沒有任何特殊含義,其建構必須以某種具體的自然語言作為語義參照對象,結合我國語言文字工作的總體規劃,多民族語言通用語義代碼體系的構建應當以國家通用的漢語和規范漢字作為參照語言文字。因此,對少數民族語言信息資源進行“簡化通用語義代碼體系”(SUSCS)的標注,本質上是參照國家通用語言文字進行語義映射的過程,因而也是以國家通用語言文字為核心的多民族語言信息資源共享體系的實現方式。
根據現實需求,我國多民族語言“簡化通用語義代碼體系”擬采用開放式結構設計,初期主要進行國家通用語言文字和蒙古語、藏語、維吾爾語、哈薩克語、柯爾克孜語、壯語、傣語、朝鮮語等使用人口較多,具有較大社會影響力的少數民族語言文字(少數民族語言的古代文字暫不在研究范疇)的統一編碼,今后根據實際需要可以繼續補充其他語種的少數民族語言文字。
基于通用語義代碼的語義轉換是一種新的視角和方法,為了驗證這種方法的可行性,筆者進行了小規模的探索性實驗。選取國家通用語言100個詞匯按照數字1~100進行語義編碼,對藏文和蒙古文的同義詞進行關聯;分別用藏文和蒙古文的上述詞匯組成簡單句子,再進行語義編碼標注,最后采用國家通用語言文字關鍵詞進行檢索,相同語義不同語言的多個文檔均可檢索到。實驗結果表明,采用簡化通用語義代碼體系進行跨語言信息檢索在原理上是可行的。
3 架構設計
根據少數民族語言信息資源計算機輔助閱讀的需求結構和技術原理,少數民族語言信息資源計算機輔助閱讀系統(CARS-IRMLC)的體系架構見圖2。在圖2當中,CARS-IRMLC系統主要分為基礎代碼、預處理、閱讀輔助、信息輸出等環節,每個環節又細分為多個模塊,主要研究內容如下。
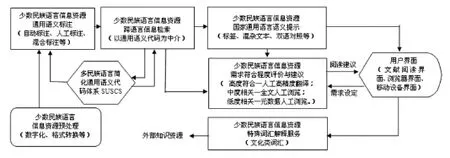
圖2 CARS-IRMLC系統總體架構
3.1基礎代碼體系
SUCSC是少數民族語言信息資源計算機輔助閱讀系統建設的關鍵,決定了整個體系建設的成敗。鑒于通用語義代碼設計工作的復雜性和長期性,本項目擬根據研究需求對通用語義代碼體系進行適度簡化,設計依據主要是國家通用語言與各語種少數民族語言的雙語詞典。參照國家通用語言文字詞典建立基本代碼體系,各少數民族語言的同義語素根據雙語詞典與通用語義代碼進行關聯,形成以國家通用語言為參照的多語言同義詞表,同時選取部分常用同義句進行統一編碼,原則上不對各類語言文字語法規則進行編碼。需要說明的是,實驗過程中所使用的“簡化通用語義代碼體系”是根據各類語言的高頻詞匯和句例制作的原型系統,目的是驗證技術原理的可行性,在應用和推廣之前還需要進行大規模補充完善和持續進化。
3.2預處理功能
預處理是實現少數民族語言信息資源計算機輔助閱讀的前提,主要包括技術預處理和語義標注等工作。技術性預處理主要包括:①對以紙質文檔存在的少數民族語言信息資源進行數字化加工,結合文字識別技術和人工轉錄方法,將其轉換為計算機可以處理的少數民族語言文本文件;②為了保證多語種少數民族語言文字的正常顯示,需要將各語種信息資源按照GB18030信息編碼標準進行轉換,以保證其兼容性;③為了便于進行信息處理,需要將各種應用軟件產生的文本格式統一轉換為TXT格式。通用語義代碼標注是實現計算機輔助閱讀的基礎工作,主要通過三種方式完成:①自動標注,由程序調用多語言通用語義代碼體系完成自動標注,工作精度較低;②人工標注,在標注程序輔助下由人工完成對語義的精確標注,工作速度較慢;③混合標注,由程序完成基礎標注,人工方式進行確認和修改。
3.3閱讀輔助功能
閱讀輔助功能是系統的主要建設目標,包括跨語言檢索、語義提示、用戶建議、文化支持等部分。
(1)少數民族語言信息資源跨語言信息檢索算法及實現。主要基于多民族語言簡化通用語義代碼體系,實現跨語言信息資源檢索。如,以國家通用語言文字為檢索詞,程序首先查找該檢索詞的SUSCS編碼,然后在系統中查找所有標注為該編碼的信息資源,而不論其采用的是何種語言文字。
(2)少數民族語言信息資源通用語義提示功能的實現。國家通用語言語義提示是實現少數民族語言信息資源計算機輔助閱讀的主要方式,基于查詢SUSCS編碼表當中的多語言同義語素關聯表來實現,語義提示主要基于三種模式:①標簽提示模式。閱讀過程中鼠標滑過的文字以標簽形式現實其國家通用語言文字語義;②混雜文本模式。文本當中的少數民族語言詞語之后括號內顯示其國家通用語言文字語義;③雙語對照模式。以段或篇為單位,分別顯示少數民族語言文字和國家通用語言文字語義。
(3)少數民族語言信息資源用戶需求符合程度評價與建議功能實現。CARS-IRMLC系統允許用戶輸入多個國家通用語言文字的關鍵詞并設定其詞頻閥值,在進行跨語言檢索過程中,自動計算上述數據,根據結果為用戶提供閱讀建議。系統可以提供的閱讀決策主要有三類:①高度符合。說明該信息資源對用戶非常重要,建議用戶將文本提交給專業的人工翻譯人員進行高精度人工翻譯。②中度相關。說明該信息資源與用戶需求有一定關聯,但是需求強度還不足以達到閥值,建議用戶逐一進行全文瀏覽以判斷相關資源的取舍。③低度相關。說明該信息資源主題與用戶需求可能有一些聯系,建議用戶進行標題等元數據項的快速瀏覽以判斷其取舍。
(4)少數民族語言信息資源輔助閱讀文化支持功能的實現。文化支持功能是屬于在用戶了解少數民族語言信息資源通用語義提示信息的基礎上,為了幫助其準確理解相關文化類詞匯的含義而提供的延伸性服務,其實現方式主要是建立各少數民族語言文字特殊術語詞匯的解釋性列表,提供該詞匯與外部知識資源之間的鏈接,從而使其閱讀時可以進行參考,幫助其理解這些術語的內涵和性質。
3.4用戶界面
少數民族語言信息資源計算機輔助閱讀系統用戶界面設計,系統根據用戶使用系統的不同情境設計三種種類的用戶界面。①文獻閱讀器界面。主要適用于圖書館、檔案館、博物館等文獻信息資源數量較多的機構提供少數民族語言信息資源服務時使用。②網絡瀏覽器界面。即少數民族語言網絡信息資源閱讀器插件,用戶使用Internet Explore等網絡瀏覽軟件訪問少數民族語言文字網頁的時候,只要加載該插件即可進行國家通用語言語義提示,并給出網頁的閱讀建議。③移動設備閱讀器界面。根據移動通信設備顯示信息的特點,設計符合用戶使用習慣的輔助閱讀界面,使用戶可以遠程接受公共信息機構的輔助閱讀服務。
CARS-IRMLC系統主要是針對少數民族語言信息資源跨語言輔助閱讀基本需求,基于計算機網絡環境而設計的。在系統各項關鍵技術取得突破并基本成熟之后,筆者擬基于這些技術探索基于個人移動通信設備的少數民族語言信息資源輔助閱讀系統,用戶的移動通信設備裝載了該系統,可以隨時隨地將看到的少數民族語言信息資源拍照并上傳到系統,系統根據文字識別等技術進行預處理并基于SUSCS進行閱讀輔助,給用戶反饋通過國家通用語言文字語義提示并提供閱讀建議。由于該系統可以實現中國多民族語言文字的語義共享,暫定名為“中文通”。
[1]中華人民共和國國務院新聞辦公室.中國的民族政策與各民族共同繁榮發展[M].北京:人民出版社,2009,32.
[2]于洪志,王曉軍.藏漢雙語信息處理系統概述[J].西北民族學院學報(自然科學版),1998(1):1-4.
[3]戴玉剛,何向真.通用藏文模板設計[J].西北民族學院學報,2005(3):29-34.
[4]清華大學新聞網.統一平臺少數民族文字識別系統在清華大學研制成功[EB/OL].[2015-02- 08].http://news.tsinghua.edu.cn/new/news.php?id=14 712.
[5]塔娜,等.面向跨語言信息檢索的蒙漢語義詞典構建[C]//第三屆全國少數民族青年自然語言信息處理學術研討會論文集.北京:中央民族大學出版社,2002:12-15.
[6]劉登峰,艾斯卡爾·艾木都拉.維、漢多語種檔案信息管理系統[J].計算機工程,2008(20): 263-268.
[7]中華人民共和國科技部網站.信息技術領域“以中文為核心的多語言處理技術”重點項目[EB/OL].[2015-02-08].http://www.most.gov.cn/tztg/t2006 1001_36442.htm.
The Architecture Design of the Computer-assisted Reading System of Minority Language Information Resources
Zhao Sheng-hui
It is an urgent need to remove the communication barriers dues to language difference with the application of information technologies in information resources management in ethnic minority residence regions of China.Besides Machine Translation technology,Computer-assisted Cross-Language Reading System(CARS-IRMLC)refers to the specially designed cross-language reading environment which public service institutions of minority residence regions provided for their customers who only master national common language.CARS-IRMLC takes Simplified Semantic Code System as the logic medium for positioning,linking and retrieval of synonyms morphemes of multiple minority languages of China,as well as logic intermediary for semantic information transformation.CARS-IRMLC can be widely used in government offices,libraries,archives,museums and other public cultural institutions in minority residence regions of China.
Minority Languages of China;Information Resources Sharing;Computer-assisted Reading;Cross-language Information Retrieval;Machine Translation
G250.78
A
1005-8214(2016)10-0072-05
本文系國家社科基金項目“多民族語言信息資源跨語種共享策略研究”(項目編號:14BTQ008),中國博士后科學基金項目“多民族語言信息共享域的架構模型與規劃方法研究”(項目編號:2014M561634),中國博士后科學基金特別資助項目“多民族語言信息資源輔助閱讀系統原型設計與開發研究”(項目編號:2015T80539)的階段性成果。
趙生輝(1977-),男,陜西寶雞人,西藏民族大學管理學院公共管理系副教授,研究方向:民族信息學、數字人文、電子政務等。
2016-02-03[責任編輯]菊秋芳
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
新世紀智能(語文備考)(2021年9期)2021-12-06 03:25:24
新世紀智能(語文備考)(2021年4期)2021-08-06 09:01:10
新世紀智能(語文備考)(2021年4期)2021-08-06 09:01:08
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
