基于Matlab的共詞矩陣構造
2017-05-12 23:59:30陳道蘭趙恒軍
合作經濟與科技 2017年9期
陳道蘭+趙恒軍
[提要] 共詞分析在文獻研究中被廣泛采用,共詞分析方法最關鍵的環節是共詞矩陣的構造。本文詳細介紹基于中國知網數據庫的關鍵詞原始數據采集具體過程,利用Excel的分列功能和數據透視表功能進行關鍵詞的分離和詞頻的統計,以及高頻關鍵詞提取的預處理技巧,給出共詞矩陣構造的算法及其Matlab程序。算例表明:文中所給共詞矩陣的構造實施方便快捷、簡單易行。
關鍵詞:共詞矩陣;構造;高頻關鍵詞;預處理;Matlab
基金項目:重慶市教委科研項目:“基于曲率的無參考圖像清晰度評價研究”(項目編號:KJ1401127);重慶文理學院科研項目:“共詞矩陣的構造及其在文獻聚類分析方法中的應用”(項目編號:Z2016TS72)
中圖分類號:G350 文獻標識碼:A
收錄日期:2017年3月3日
一、引言
文獻計量學是采取定量手段來分析知識載體的交叉科學,關鍵詞共詞分析作為通用的文獻計量法,主要是通過統計兩個關鍵詞在同一篇文獻中共同出現的次數,并以此進行聚類進而分析預測特定學科的研究熱點。關鍵詞共詞一般可分為以下幾個環節:采集原始數據→統計關鍵詞詞頻→提取高頻關鍵詞→構造共詞矩陣→構造相異矩陣→關鍵詞聚類→結果分析。在整個分析過程中,最后一步至關重要,它體現了研究的結論和價值,而最關鍵的一步則是共詞矩陣的構造。共詞矩陣會直接影響到相異矩陣的構造進而影響聚類的結果,對研究的結論起著不可忽視的作用。
國內學者對關鍵詞聚類分析主要表現在利用共詞矩陣對所研究的主題進行預測,而對共詞矩陣如何構造,大多數文獻只是略微提及。鑒于此,儲節旺等提出了利用Excel進行共詞矩陣的構造,他提出的方法在關鍵詞詞頻的統計、高頻關鍵詞的提取方面有較好的便利,但在共詞矩陣的具體構造這一環節,由于只是單純用Excel軟件處理,在清除低頻關鍵詞、關鍵詞組對等環節需要人工操作,導致數據統計容易出錯。因此,簡化關鍵詞的預處理和共詞矩陣構造的過程是值得研究的課題。
Matlab是由美國Mathworks公司發布的數學軟件。考慮到Matlab軟件在數值計算方面的強大功能,本文提出以Matlab為編程軟件,編寫構造共詞矩陣的Matlab文件。通過Matlab程序的編寫,簡省了低頻關鍵詞的清除過程和高頻關鍵詞的組對過程,降低了關鍵詞預處理的難度,簡化了共詞矩陣的構造過程。Matlab算例表明編寫的Matlab程序對共詞矩陣構造實施方便快捷,簡單易行。
二、數據的采集與處理方法
(一)數據的采集
第一步:選擇文獻。在中國知網搜索頁面下,按照一定的數據采集標準進行搜索得到檢索的文獻,然后在所顯示的第一頁頁面中勾選所顯示的文獻,點擊“下一頁”,再勾選第二頁顯示的文獻,直到勾選完所有文獻。
第二步:數據輸出準備。在勾選文獻的最后一頁點擊“導出/參考文獻”按鈕,在彈出的頁面中再次勾選剛才選擇的所有文獻,再次點擊“導出/參考文獻”按鈕(很重要),然后出現標題為“文獻管理中心_文獻輸出”頁面。在該頁面的左下方有“CAJ-CD”、“查新”、“CNKI-E-Study”等按鈕。點擊不同的按鈕,在頁面的右下方會顯示不同的結果,也可以點擊“自定義”按鈕,此時在頁面的右上方會顯示可供選擇的輸出字段,然后可以勾選所需要選擇輸出的字段即可。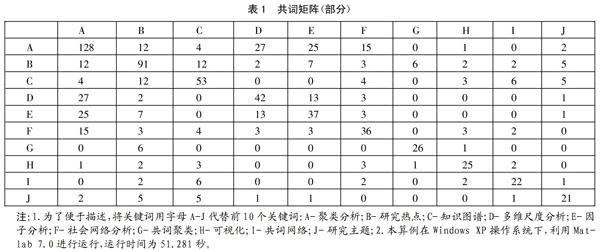
第三步:數據輸出。在“文獻管理中心_文獻輸出”頁面中點擊按鈕“XLS”,在彈出的“文件下載”對話框中點擊“保存”按鈕后,在“另存為”對話框中選擇所需要保存的路徑和文件名,得到原始數據Excel表格。
說明:當采集的數據超過500篇文獻時,需要在完成前三步后,清除所勾選的文獻,然后再選擇余下的文獻,重復上述三個步驟,直到采集完所有文獻為止。
(二)數據的預處理
第一步:提取數據。復制關鍵詞所在列,將其拷貝到一張新的空白Excel文件中,將文件命名為”keywords.xls”。
第二步:分離關鍵詞。選擇文件keywords.xls的第一列所有的數據,利用查找替換功能將關鍵詞的分隔符統一用單個分號進行分隔。再次選中所有數據,利用數據的分列功能將關鍵詞進行分離到單一單元格中。
第三步:刪除單一關鍵詞。將分列得到的工作表按第二列進行降序排列,將單一關鍵詞所在的行下移到了末尾,刪去這些單一關鍵詞所在的行,然后保存文件”keywords.xls”,得到關鍵詞表。
第四步:提取高頻關鍵詞。將關鍵詞表“Keywords.xls”的內容復制到一個新的Excel文件中,文件命名為高頻關鍵詞統計表“Hfkw_count.xls”。在“Hfkw_count.xls”中,將所有單元格的內容復制到第一列,然后進行降序排列,將所有的空白單元格刪去。
在第一行前插入一行,在新的第一行依次輸入“關鍵詞”,“頻數”。從第二列的第二行起,每個單元格中輸入數字“1”。利用Excel數據透視表功能統計關鍵詞出現的頻數。將得到的數據透視表的第二列按降序排列,此時第二列數值較大的單元格所對應的第一列的關鍵詞即為高頻關鍵詞。保存文件“Hfkw_count.xls”。
將頻數較高的關鍵詞復制,利用“選擇性粘貼——轉置”,粘貼到一個新的Excel文件中的第一行,將文件命名為高頻關鍵詞表“Hfkw.xls”。
三、共詞矩陣的Matlab程序實現
(一)共詞矩陣的算法。共詞矩陣主要是統計兩個關鍵詞在同一篇文章中出現的篇數。將關鍵詞錄入Excel表格后,同一篇文獻的關鍵詞出現在同一行。但Excel表格中的數據不能直接作為Matlab的數組,因此應先將Excel數據導入到Matlab文件變為Matlab數組。從而統計兩個關鍵詞在同一篇文章中出現的篇數就變為了統計兩個關鍵詞在數組中同一行出現的次數。在高頻關鍵詞數組中任意抽取兩個關鍵詞,逐行統計兩個關鍵詞同行的次數,將結果保存在共詞數組中,再將所得結果輸出到Excel表格中。
基于以上分析,共詞矩陣的算法可表述如下:第一步:讀取關鍵詞和高頻關鍵詞Excel數據,并保存到OriginalData和TargetSet變量中;第二步:設置共詞矩陣大小,初值默認為零矩陣;第三步:構造關鍵詞同行次數計數函數countMatrix(Number1,Number2,Matrix)。從高頻關鍵詞TargetSet數組中任意抽取第i個和第j個元素,統計它們在關鍵詞OriginalData數組中同一行出現的次數Output(i,j)。具體方案為:使用函數ismember(a,Vector)對每一行都進行判斷,如果a出現在Vector中,返回結果為1;否則為0。如果兩個關鍵詞的ismember結果都為1,則表示這兩個關鍵詞同時出現在這一行中,因此同行次數增加1;第四步:將關鍵詞同行的次數保存在共詞矩陣中,并將所得結果輸出到Excel表格中進行顯示。
(二)共詞矩陣的Matlab程序。根據前述關于共詞矩陣的算法,利用Matlab 7.0軟件,編制構造共詞矩陣的Matlab代碼如下:
將上述代碼錄入到Matlab M-File窗口,然后以Cowordmatrix.m為文件名進行保存。
(三)Matlab程序的運行。假設Matlab安裝在電腦的如下目錄:d:\Program Files\MATLAB7,則將前面按照關鍵詞數據的采集和預處理方法得到兩個Excel文件“Keywords.xls”和“Hfkw.xls”,以及前述的共詞矩陣構造的Matlab文件Cowordmatrix.m一起復制到d:\Program Files\MATLAB7\work目錄下。
打開Matlab程序,在Matlab命令窗口Command window中鍵入Cowordmatrix,回車,等待數分鐘后就會在d:\Program Files\MATLAB7\work目錄下出現共詞矩陣Excel文件Output.xls,打開該文件所顯示的內容即為共詞矩陣。
四、共詞矩陣的Matlab算例
下面以中國知網數據庫為數據源,對國內的共詞分析的研究進行共詞矩陣的構造。以篇名為“共詞”進行搜索,檢索時間為2016年8月26日,共搜索到553篇文獻,按前述方法提取它們的關鍵詞,分列并刪去單一關鍵詞后得到關鍵詞表“Keywords.xls”。然后使用Excel表格的數據透視功能統計關鍵詞的頻次,得到高頻關鍵詞表“Hfkw.xls”。本文選取詞頻大于等于10的關鍵詞列表(其中剔除了“共詞分析法”、“共詞分析”、“共詞”等三個關鍵詞),具體頻次為:聚類分析(128)、社會網絡分析(36)、共詞聚類分析(20)、文獻計量(16)、研究熱點(91)、共詞聚類(26)、關鍵詞(19)、文獻計量學(16)、知識圖譜(53)、可視化(25)、 戰略坐標(19)、共詞矩陣(14)、多維尺度分析(42)、共詞網絡(22)、詞頻分析(17)、共詞可視化(13)、因子分析(37)、研究主題(21)、SPSS(16)、知識管理(10)。
將得到的兩個Excel文件“Keywords.xls”、“Hfkw.xls”以及編程得到的Matlab文件Cowordmatrix.m復制到Matlab工作目錄d:\Program Files\MATLAB7\work目錄下。打開Matlab,在Maltab命令窗口輸入Matlab命令:Cowordmatrix,回車,出現的共詞矩陣結果(左上10×10部分)見表1。(表1)
五、結語
通過上述編寫的Matlab程序,研究者只需要對所研究的主題進行關鍵詞原始數據的采集和預處理,形成兩個Excel文件即可,大大簡化了原始數據的預處理和共詞矩陣的構造過程,輸出的Excel顯示結果直觀。算例表明本文所編寫的Matlab程序對共詞矩陣的構造實施方便快捷,簡單易行。
主要參考文獻:
[1]鄒美辰.基于共詞分析和社會網絡分析的國內外關聯數據研究探析[J].現代情報,2016.3.
[2]陸慧雯.基于共詞分析的我國近十年行業與戰略情報研究[J].情報科學,2016.5.
[3]周麗英,冷伏海,左文革.引文耦合增強的共詞分析方法改進研究——以ESI農業科學研究主題劃分為例[J].情報理論與實踐,2015.11.
[4]俞仙子,高英蓮,馬春霞等.提取核心特征詞的懲罰性矩陣分解方法——以共詞分析為例[J].現代圖書情報技術,2014.3.
[5]王玉林,王忠義.細粒度語義共詞分析方法研究[J].圖書情報工作,2014.21.
[6]儲節旺,郭春俠.共詞分析法的基本原理及EXCEL實現[J].情報科學,2011.6.
[7]張圣勤.MATLAB 7.0實用教程[M].北京:機械工業出版社,2015.
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
