基于游記主題挖掘與表達的旅游信息推薦研究
2017-07-17 15:23:59呂琳露李亞婷
現(xiàn)代情報 2017年6期
關(guān)鍵詞:文本挖掘
呂琳露+李亞婷


[摘要][目的/意義]針對在線旅游平臺,提出一種挖掘游記主題標(biāo)簽,以代表性游記以及其中相關(guān)內(nèi)容進行旅游信息推薦的新策略。[方法/過程]在利用文本挖掘技術(shù),構(gòu)建LDA主題模型,形成游記文本主題標(biāo)簽的基礎(chǔ)上,通過游記代表度算法,篩選出針對相應(yīng)標(biāo)簽的高描述度與高忠誠度游記進行旅游信息推薦,以客觀表達文本聚類結(jié)果以及主題詞之間的語義關(guān)系,并以螞蜂窩旅游網(wǎng)中的“杭州游記”為例,加以驗證。[結(jié)果/結(jié)論]結(jié)果表明,這種方式能挖掘出旅游者在歷史旅游經(jīng)歷中真實的旅游熱點及重點信息需求,針對高相似度游記的識別與聚類具有良好效果,對旅游信息細粒度推薦具有指導(dǎo)意義與實踐意義。
[關(guān)鍵詞]在線旅游平臺;游記;信息推薦;信息服務(wù);文本挖掘
D0l:10.3969/j.issn.1008—0821.2017.06.010
[中圖分類號]G254 [文獻標(biāo)識碼]A [文章編號]1008—0821(2017)06—0061—07
網(wǎng)絡(luò)游記作為人們獲取旅游信息的重要來源之一,已經(jīng)成為一種傳遞旅游信息的網(wǎng)絡(luò)口碑,幫助并影響著旅游者的決策行為。在此背景下,游記資源的組織和整合對于在線旅游平臺中的信息序化以及信息推薦策略研究具有重要意義。如今,在線旅游平臺對于游記資源供用戶篩選的條件大都局限于人均花費、行程天數(shù)、出發(fā)時間、和誰出行等屬性,不足以滿足用戶對更具針對性游記的檢索需求,完善游記信息序化機制,提出更有效的信息推薦策略成為旅游網(wǎng)站發(fā)展過程中的一種切實需要。
由此,本文針對在線旅游平臺,提出一種借助文本挖掘技術(shù)來提取游記標(biāo)簽,并篩選出代表性游記,提取相關(guān)內(nèi)容以進行旅游信息推薦的新策略。研究利用LDA模型對游記文本進行主題識別與分析,然后將提煉出來的特征詞作為游記的主題標(biāo)簽,根據(jù)從中自主選擇的標(biāo)簽形成了游記文本的聚類,最后采用代表性游記客觀表達帶標(biāo)簽文本的內(nèi)容,實現(xiàn)科學(xué)推薦的目的。
1相關(guān)研究
回顧相關(guān)文獻,學(xué)者們對于網(wǎng)絡(luò)游記文本挖掘,主要將其應(yīng)用在對旅游目的地的形象感知和情感分析、游客行為特征的發(fā)現(xiàn)以及旅游推薦系統(tǒng)的優(yōu)化中。而以旅游信息推薦為中心的研究,除了對在線旅游平臺中旅游產(chǎn)品營銷策略的探索,學(xué)者們主要著眼于旅游信息推薦算法的改進,分析如何優(yōu)化相關(guān)算法來提高推薦效率和準(zhǔn)確率,重點集中在利用日志信息和交互信息以及用戶行為數(shù)據(jù),包括訪問記錄、瀏覽與購買行為、時空數(shù)據(jù)、旅游游記等,以進行個性化旅游信息推薦。
到目前為止,針對在線旅游游記的推薦研究較少,存在很大的探索空間。相較有參考意義的有:Ji利用游記中的照片和地點信息,建立了一個包含“用戶一景點一照片”的層次化的圖結(jié)構(gòu),并對景點、用戶和照片進行排序,隨后又對其進行了延伸,在進行景點排序后,采用稀疏重構(gòu)方法提取景點的代表性照片;Hao等采用概率圖模型對旅游游記進行建模,提出游記中的詞匯屬于背景話題模型和地點特有的話題模型兩大類,并以此進行游記特征詞的抽取;馬艷艷肯定了旅游網(wǎng)站中游記分享社區(qū)的現(xiàn)實價值,并通過對旅游網(wǎng)站中游記專輯制作和分享展示的具體功能設(shè)計,闡述了對游記資源進行組織與整合的基本方法;諸葛菲提出了在線旅游服務(wù)中的眾包信息推薦模型,該方法基于旅行者隱式行為,針對某一旅游需求,將所有眾包旅游方案中與需求相似度最大的方案作為最優(yōu)結(jié)果推薦給用戶。
綜上,雖然學(xué)者們已經(jīng)注意到了游記資源在旅游信息推薦中的重要性,部分研究實現(xiàn)了從游記中挖掘相關(guān)知識以創(chuàng)新旅游信息服務(wù),但少數(shù)研究將研究重點直接立足于游記本身的推薦上,基于此,本文通過對網(wǎng)絡(luò)游記文本進行主題建模獲得游記主題標(biāo)簽,根據(jù)標(biāo)簽組合形成文本聚類,并篩選出代表性游記進行旅游信息推薦,即從游記文本出發(fā)最終回歸到游記進行信息表達,實現(xiàn)客觀、科學(xué)的推薦策略。
2研究設(shè)計與方法
本文通過網(wǎng)絡(luò)爬蟲獲取研究樣本區(qū)域的游記文本,然后對文本進行預(yù)處理,包括設(shè)定自定義詞表、分詞和去停用詞等,將文本向量化;隨后構(gòu)建LDA主題模型,得到游記數(shù)據(jù)集中的主題概率分布,并對所識別發(fā)現(xiàn)的高頻特征詞進行人工分析與描述,形成文本主題的相關(guān)標(biāo)簽;最后,通過對每篇游記于用戶根據(jù)需要設(shè)定的標(biāo)簽的描述度、忠誠度和代表度的計算,得到相應(yīng)標(biāo)簽的代表性游記及相關(guān)內(nèi)容。
2.1數(shù)據(jù)采集及預(yù)處理
本文采用MetaStudio和DataScraper網(wǎng)頁信息抽取工具,以螞蜂窩旅行網(wǎng)(http:∥www.mafengwo.cn)為例,在網(wǎng)站上用“杭州”作為目的地標(biāo)簽搜集相關(guān)游記,采集的內(nèi)容包括游記的全部文本以及相關(guān)屬性,采集時間為2016年10月13日至2016年10月14日,共計1005條數(shù)據(jù)。
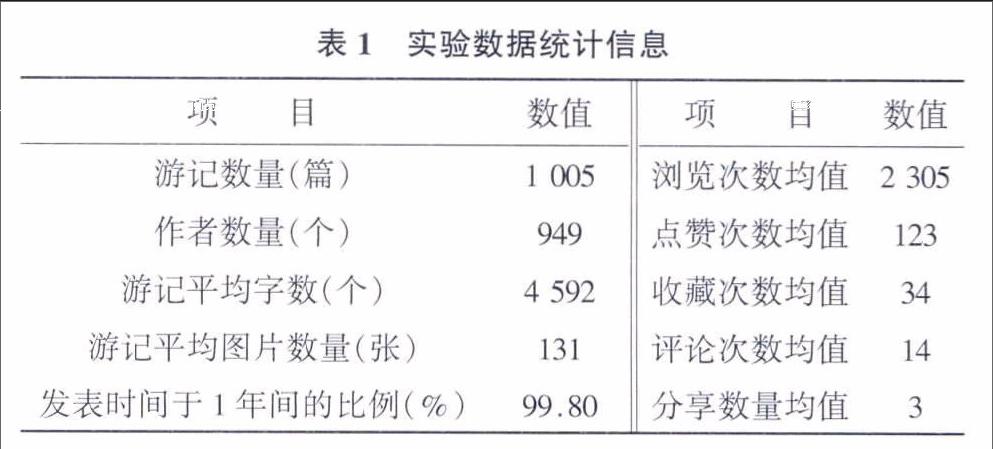
由于游記中語義表達方式多樣,本文結(jié)合攜程旅游網(wǎng)、螞蜂窩旅行網(wǎng)和貓途鷹旅行社區(qū)提供的杭州地名信息以及其他相關(guān)詞匯信息,以最少匹配為原則,人工對詞表進行統(tǒng)一處理,最終得到杭州主題相關(guān)詞表(1433個)。基于此,通過正則表達式去除游記中的鏈接、表情符號等噪音信息后,采用Python的Jieba分詞包,對數(shù)據(jù)樣本進行分詞處理,保留各個游記的名詞、形容詞以及自定義詞表中的詞匯,并去除停用詞,最后得到表1所列數(shù)據(jù)集合。
2.2游記文本主題挖掘
借助Python工具,本文運用主題建模中最基本的模型LDA(Latent Dirichlet Allocation),挖掘隱藏在游記文本內(nèi)的潛在主題,并對高頻特征詞進行人工分析與描述,以此得到文本主題標(biāo)簽。在LDA建模過程中,采用MCMC(Markov Chain Monte Carlo)中的Gibbs算法對IDA模型的參數(shù)進行近似估計。其中,本文將狄利克雷函數(shù)的先驗參數(shù)α和β設(shè)置為經(jīng)驗值,分別為α=50/K,β=0.01,而主題個數(shù)K則利用層次狄利克雷過程(Hierarchical Dirichlet Processes)進行分析確定。
2.3代表性游記及相關(guān)內(nèi)容的選取
崔雷等在研究中以TF-IDF為方法學(xué)基礎(chǔ),提出了選取代表性論文來表示某一學(xué)科主題高頻詞共現(xiàn)聚類分析結(jié)果的方法。基于此,本文通過計算Pi游記對標(biāo)簽組Cj的描述度和對Cj內(nèi)容表達的專指性,對每篇游記的代表度進行度量最后進行降序排列以得到相應(yīng)的代表性游記。具體步驟如下:
最后,對所選定的代表性游記,提取含有標(biāo)簽組合中主題詞的所有句子,得到關(guān)于各個標(biāo)簽主題詞的針對性內(nèi)容。
3游記主題詞提取
針對數(shù)據(jù)預(yù)處理得到的分析樣本,利用層次狄利克雷過程算法,采用Python的Gensim工具包,對LDA模型中的主題個數(shù)進行預(yù)判,得到K=149。進而構(gòu)建LDA模型,抽取前10個聚類主題,每個主題下生成20個最有可能出現(xiàn)的詞語以及相應(yīng)的概率。由于LDA模型為概率生成模型,每一次得到的識別結(jié)果有所差別,表2展示了其中一次實驗中的前5個聚類結(jié)果。綜合實驗結(jié)果得,不同主題聚類間的特征詞相似度高,且大多分布在旅游景點相關(guān)名詞。由于游記是旅游者基于自身旅游體驗主動發(fā)表的文本,主要描述了旅游過程與感受,蘊含著明顯的行程規(guī)劃信息,因此文本主題多為景點地名及其他相關(guān)名詞符合游記文本的語言特點。同時,也表明了游記文本的主題十分集中,實驗樣本之間的相似度很高,正鑒于此,需要對文本內(nèi)容進行細粒度的識別和表達,才能更準(zhǔn)確高效的從繁多的信息中篩選出對用戶而言價值更高的游記。
本文對上述LDA實驗過程重復(fù)10次,并對得到的高頻特征詞及其分布概率進行人工分析與判讀,過濾語義性弱以及重復(fù)的特征詞,得到文本的特征標(biāo)簽詞表(共108個),如表3所示。其中,這些主題詞主要可分為4類:①相關(guān)城市名稱,如上海、蘇州、南京等,對包含這些城市名的游記進行探析發(fā)現(xiàn),其語義關(guān)系多為游客行程安排中涉及的旅游出發(fā)地與目的地,也就是說一方面從這些城市到杭州旅游的游客居多;另一方面人們在游玩杭州時,常同時將這些城市也安排在旅行計劃中;②旅游景點名稱,如千島湖、西湖、靈隱寺以及河坊街等,旅游景點名稱作為占比最多的標(biāo)簽主題詞匯,旅游景點名稱也是最重要的標(biāo)簽,根據(jù)不同標(biāo)簽的選取,可以有效地幫助用戶篩選出切合需求的游記;③景點特色相關(guān)詞匯,如古鎮(zhèn)、龍井、游船和索道等,這些特征是對旅游景點特色的進一步表達,加強了對旅游景點名詞的語義理解,同時,由于模型算法抽取出的主題詞都是相關(guān)性很強的詞匯,保證了這些景點特色相關(guān)詞匯的可靠性與準(zhǔn)確性;④旅游信息要素相關(guān)特征詞,如門票、酒店、公交及餐廳等,這些主題都是旅行過程中的常見話題,也是旅游者信息需求中的重要組成部分。
4信息推薦的實現(xiàn)
4.1代表性游記推薦
根據(jù)得到的主題標(biāo)簽詞表,選定標(biāo)簽詞,計算得到對應(yīng)的代表性游記,并對其進行了相關(guān)性分析以檢驗實驗結(jié)果的科學(xué)性與實效性,具體步驟與結(jié)果分析如下。
本文以標(biāo)簽組“周莊、西塘、西溪、河坊街、機場”、“上海、西湖、花港觀魚、三潭印月、京杭大運河、河坊街、酒店、公交”和“靈隱寺、飛來峰、門票、民宿、龍井、中國茶葉博物館”為例,計算每篇游記對相應(yīng)標(biāo)簽的描述度、忠誠度和代表度。同時,根據(jù)代表度降序排列,得到前10篇游記作為代表性游記。對于同一組標(biāo)簽,本文首先計算了游記的描述度、忠誠度與代表度的相關(guān)性(見表4)。
從表4可看出,針對1005篇游記,整體上三者之間存在顯著正向相關(guān)關(guān)系;對于代表性游記,游記的描述度與忠誠度呈負相關(guān),而代表度與描述度、忠誠度相關(guān)性呈不確定狀,且三者之間相關(guān)關(guān)系的顯著性由標(biāo)簽組合的改變存在差異。描述度高的游記表示了在該游記中標(biāo)簽對應(yīng)內(nèi)容相較豐富,忠誠度高則表明該游記對于用戶指定的需求更具有針對性,專指性強。當(dāng)游記作者對標(biāo)簽涵蓋旅游內(nèi)容進行了較為詳盡的描述時,根據(jù)游記作者的語言習(xí)慣往往對其他內(nèi)容也有較長篇幅的記錄,因此在一定程度上描述度與忠誠度存在相互制約。而代表度算法綜合了游記對標(biāo)簽主題的描述程度和忠誠程度,只有在游記作者以標(biāo)簽主題內(nèi)容為整篇游記的重點,對相關(guān)內(nèi)容描述得多而其他內(nèi)容記錄得少時,才能得到兩者均處于較高水平的狀態(tài)。這使得最終選取出的代表性游記在內(nèi)容上有較豐富的展現(xiàn),同時過濾掉了用戶沒有需求的冗余信息。
隨后本文對代表性游記進一步追蹤和檢驗,得到各游記字數(shù)、所包含圖片數(shù)以及對應(yīng)游記的用戶互動行為數(shù)據(jù),如表5所示。結(jié)果表明,所選取的代表性游記并不是簡單的數(shù)據(jù)集中字數(shù)和包含圖片數(shù)最多的游記,但其數(shù)目處在相較高的位置且在用戶互動指標(biāo)上有較好的表現(xiàn)。與此同時,3組標(biāo)簽共得到29篇代表性游記,分別來自29為作者,不同標(biāo)簽組得到的代表性游記差異性顯著,初步證明了通過上述算法得到了對應(yīng)不同需求的信息甄別結(jié)果,對于高相似度游記的識別與聚類具有良好效果。
與此同時,本文對抽取同一組標(biāo)簽下的代表性游記內(nèi)容進行人工分析以驗證,得到代表度更高的游記對于標(biāo)簽涵蓋內(nèi)容的描述與表達更加相關(guān)與細致,且在不同標(biāo)簽組下均有較好的效果。例如,標(biāo)簽組“周莊、西塘、西溪、河坊街、機場”中,對應(yīng)編號為187的游記在字數(shù)、所含圖片數(shù)以及閱讀、點贊、評論、收藏和分享指標(biāo)上均明顯高于其他代表性游記,但其代表度排列第7,并不靠前。具體探究可得該游記行程為“杭州-南潯-蘇州-周莊-錦溪-上海”,時間跨度10天,雖然內(nèi)容豐富但范圍廣泛,針對性稍弱,而其他排名靠前的游記與標(biāo)簽內(nèi)容的相關(guān)性更強。在內(nèi)容詳盡方面,例如標(biāo)簽組“上海、西湖、花港觀魚、三潭印月、京杭大運河、河坊街、酒店、公交”中。對應(yīng)編號為82、634、826的游記對三潭印月景點的相關(guān)描述;標(biāo)簽組“靈隱寺、飛來峰、門票、民宿、龍井、中國茶葉博物館”中,對應(yīng)編號為173、642游記對靈隱寺和飛來峰門票信息的表達,見圖1,隨著游記在組中代表度依次減弱,其相關(guān)記錄的詳盡程度依次減弱。
4.2針對性內(nèi)容定位
根據(jù)數(shù)據(jù)樣本中對游記篇幅的統(tǒng)計結(jié)果可知,其平均字數(shù)達到4 500字以上,因此,為了更高效的給予用戶相關(guān)信息推薦,滿足用戶需求,本文進一步提取了代表性游記中包含標(biāo)簽內(nèi)容的相關(guān)信息。表6展示了對于標(biāo)簽組“周莊、西塘、西溪、河坊街、機場”,部分代表性游記中針對“機場”的相關(guān)信息。
5結(jié)語
如今,很多用戶都傾向于從在線旅游平臺中獲取旅游經(jīng)驗以完善自己的旅游計劃,而歷史旅游者融合自身體驗,分享與總結(jié)旅游經(jīng)驗,撰寫旅游游記,對于潛在旅游者極具價值。本文以螞蜂窩旅游信息交流平臺中杭州旅行游記為例,利用LDA模型對游記文本集進行建模,得到文本主題分布與游記中心主題相關(guān)詞匯。隨后,設(shè)定相關(guān)標(biāo)簽,通過每篇游記對標(biāo)簽組合的描述度、忠誠度和代表度的計算,得到相應(yīng)的代表性游記及相關(guān)內(nèi)容,最后通過對代表性游記的追蹤與檢驗,結(jié)合游記內(nèi)容和相關(guān)屬性,對研究算法進行了進一步剖析。
作為現(xiàn)實旅游者對自身旅游經(jīng)歷的描述與情感表達,游記文本具有信息真實、反饋及時、內(nèi)容豐富的特點,通過LDA主題模型從游記文本中識別出來的特征詞,切實代表了該旅游目的地中的熱門景點與特色以及用戶在旅游過程中關(guān)心的熱點,將其設(shè)為供用戶選取的標(biāo)簽詞具有符合用戶需求的良好表現(xiàn)。隨后,本文提出以根據(jù)主題標(biāo)簽選取代表性游記進行旅游信息推薦的新策略,具有很好的指導(dǎo)意義和實踐價值。一方面,當(dāng)用戶設(shè)定一組標(biāo)簽后,需要檢索系統(tǒng)尋找到這組標(biāo)簽所代表的概念之間的語義關(guān)系,而這種關(guān)系往往就蘊含在用戶自發(fā)、自主撰寫的游記文本中。另一方面,當(dāng)對游記文本數(shù)據(jù)集進行主題識別與文本聚類后,對這些知識發(fā)現(xiàn)的結(jié)果進行表達和解釋,然后呈現(xiàn)給用戶是信息服務(wù)的最后一道程序,通過篩選代表性游記,用客觀存在的游記文本來表現(xiàn)主題內(nèi)容,實現(xiàn)旅游信息推薦的方法,使得對主題詞之間語義關(guān)系的判讀更為客觀與準(zhǔn)確。
本文還存在一些不足以及可加以深入探討的內(nèi)容,如本文僅以LDA模型為例抽取游記主題標(biāo)簽,雖然LDA是主題挖掘模型中較為成熟與流行的聚類算法,但不代表其完全適應(yīng)游記文本的語言特點。同時,用戶對于游記描述度與忠誠度的傾向方面是否存在側(cè)重等問題也有待商榷,因此,主題識別算法的優(yōu)化以及代表性游記篩選策略的改進都將是以后的研究著眼點。
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識與技術(shù)(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導(dǎo)刊(2016年12期)2017-01-21 15:55:21
電子技術(shù)與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫(yī)藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學(xué)學(xué)報·自然科學(xué)版(2016年3期)2016-06-25 06:47:25
語文教學(xué)之友(2016年5期)2016-06-15 12:15:44
