基于相似性的外賣—人群深層神經網絡分類模型
2019-03-19 12:46:04遼寧省沈陽市二中邢城祎
數學大世界 2019年2期
遼寧省沈陽市二中 邢城祎
在訂外賣的人群中,不同的人群所訂外賣的數量有著很大差別。本文把外賣垃圾數量—人群特點的關系和某地區月平均降水量—該地氣候類型的分類方式相類比,通過實地采集,得到外賣垃圾數量的第一手資料,并且查詢所需位置的降水量數據,經過數據清洗后,得到較為充分準確的數據。同時,在分類方法上進行深入研究,采用深層神經網絡模型訓練對應的降水量—氣候類型數據。通過不斷的模型設計與超參數調節,使模型在降水量—氣候類型和外賣數量—人群種類兩個數據集上均達到較高的分類正確率。保存訓練后的模型作為之后的預測,達到使用時無需訓練,僅需輸入該地外賣垃圾數量,就能夠以較高的正確率推測該地人群特點的目的。此模型在實際應用上可以通過外賣數量推測人群特點,從而研究更有效、更有針對性的垃圾處理方案。
一、問題背景
2016年,全國生活垃圾年清運量已經高達20362萬噸,而其中外賣垃圾所占的比例正逐年上升。根據外賣類平臺“餓了嗎”發布的數據,外賣服務業每天至少會產生2000萬份廢棄的一次性包裝盒、塑料袋和一次性餐具。垃圾已嚴重影響環境和人民的生活。
二、分類標準
通過調查得出以下帶有一定普適性的分類標準:
1.外賣固體廢棄物

類別舉例塑料 塑料餐具,塑料盒,塑料袋等紙紙袋,紙巾等紙皮 紙盒,宣傳單,紙杯等木頭 木制筷子等食品殘余物 各種食物殘渣
2.人群種類與所處區域

所處區域 人群種類醫院 病人,醫護人員等研究所 科研人員等寫字間 小型創業者等住宅區 普通居民等中學補課班 學生,老師等
三、外賣固體廢棄物數據采集
1.采集方式
為了獲取準確的第一手資料,收集數據采用實地采集的方法。因為在垃圾收集處,外賣垃圾與其他各種垃圾混合在一起,很難準確測量出僅屬于外賣的垃圾質量。所以,我們采用單位騎手的外賣垃圾質量乘以外賣騎手數量作為外賣質量的估計值。對于單位騎手外賣垃圾質量,我們將通過模擬預定外賣來測量每位騎手所帶來的外賣垃圾質量。
2.各人群種類所在地區外賣固體廢棄物采集方法
通過網絡及實地調查,選取有代表性的人群種類所在地區,確定所在地區能使外賣騎手進入的大門數量,記錄7:30~19:30每一個小時內各門外賣騎手的進入數量,準確測得數據后進行統一的數據匯總。
四、假設
1.假設外賣固體廢棄物僅分為如上類別,忽略其余垃圾種類。
2.假設人群種類僅分為如上類別,忽略其他人群種類。
3.假設所采集數據的地方具有強代表性,可以代表其他類似場所。
4.假設所調查的地方每日所產生的外賣固體廢棄物質量相同。
5.假設模擬預定的外賣固體廢棄物質量經過平均計算,可以代表每位騎手所帶來的外 賣固體廢棄物質量。
五、估算每位騎手所帶來的外賣固體廢棄物質量
為估計每位騎手所帶來的外賣垃圾質量,我們訂了不同種類的外賣,分別稱量種類不同的固體廢棄物的質量,經多次稱量,得出如下數據(單位:g):
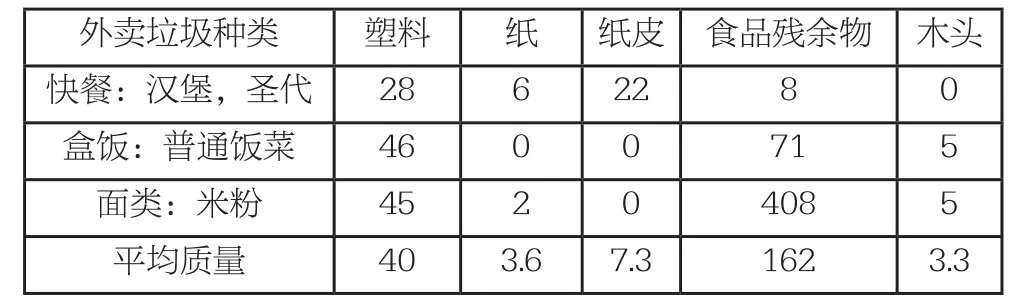
外賣垃圾種類 塑料 紙 紙皮 食品殘余物 木頭快餐:漢堡,圣代 28 6 22 8 0盒飯:普通飯菜 46 0 0 71 5面類:米粉 45 2 0 408 5平均質量 40 3.6 7.3 162 3.3
六、基于相似性的外賣—人群深層神經網絡分類模型建立
1.數據采集
通過既定的方法,選取中國人民解放軍沈陽軍區總醫院、中國科學院金屬研究所、沈陽市華潤大廈、豐澤花園與某補課班實地采集數據如下(單位:輛):
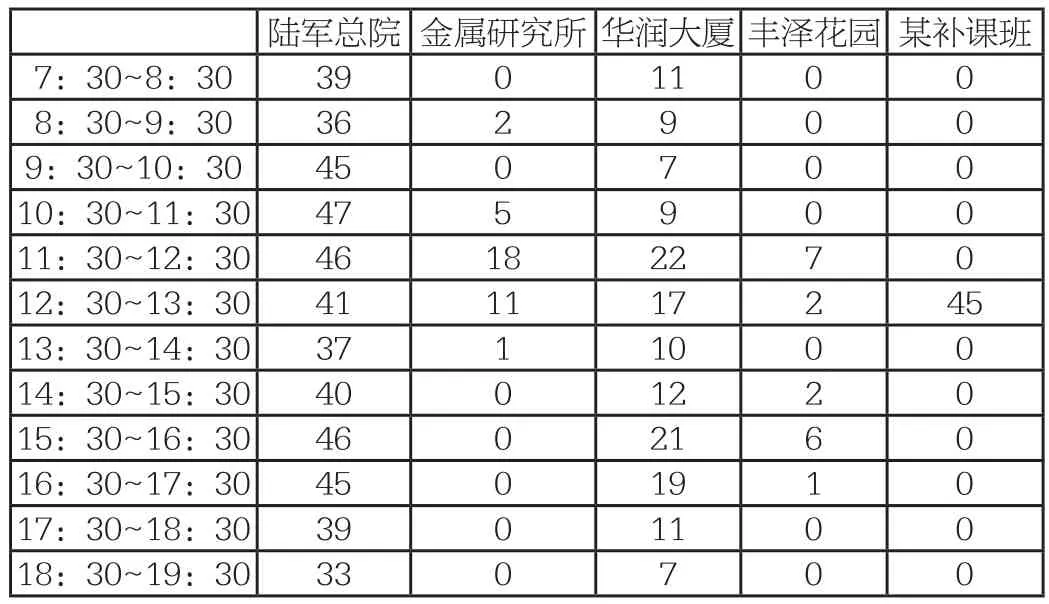
陸軍總院 金屬研究所 華潤大廈豐澤花園 某補課班7:30~8:30 39 0 11 0 0 8:30~9:30 36 2 9 0 0 9:30~10:30 45 0 7 0 0 10:30~11:30 47 5 9 0 0 11:30~12:30 46 18 22 7 0 12:30~13:30 41 11 17 2 45 13:30~14:30 37 1 10 0 0 14:30~15:30 40 0 12 2 0 15:30~16:30 46 0 21 6 0 16:30~17:30 45 0 19 1 0 17:30~18:30 39 0 11 0 0 18:30~19:30 33 0 7 0 0
2.模型建立思路
實地采集各地外賣騎手數量,發現各區域的每小時外賣騎手數量分布特點與一些氣候類型所對應的每月平均降水量分布特點極為相似,故以相似為基礎,將各個人群特點所處區域一一映射至如下的氣候類型:
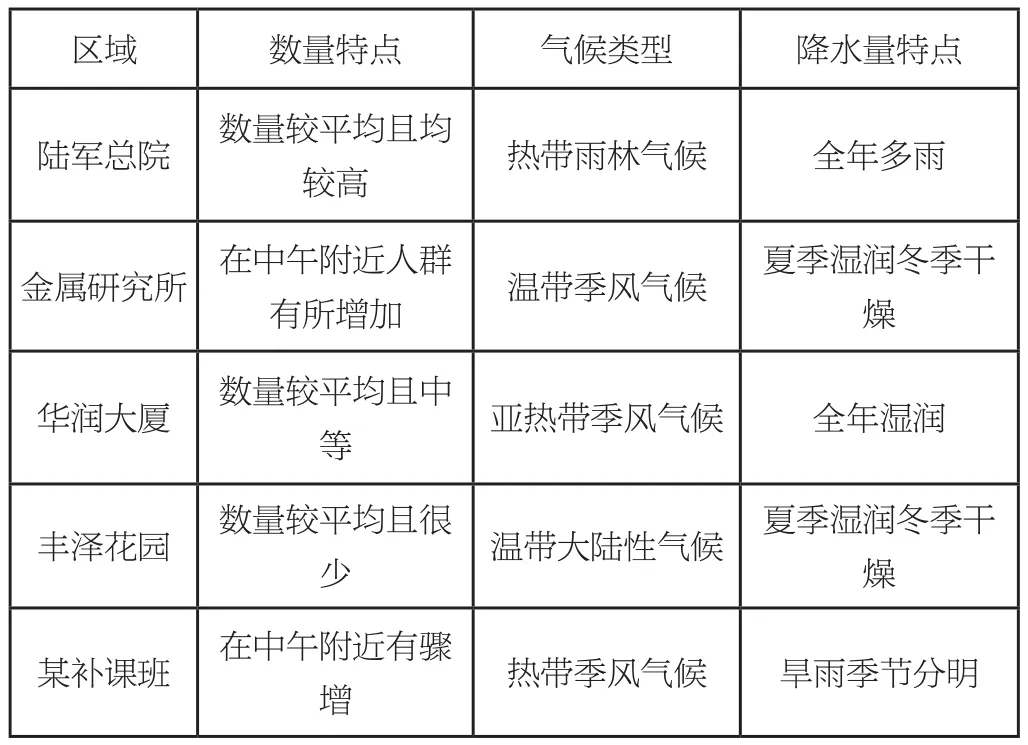
區域 數量特點 氣候類型 降水量特點陸軍總院 數量較平均且均較高 熱帶雨林氣候 全年多雨金屬研究所 在中午附近人群有所增加 溫帶季風氣候 夏季濕潤冬季干燥華潤大廈 數量較平均且中等亞熱帶季風氣候 全年濕潤豐澤花園 數量較平均且很少溫帶大陸性氣候 夏季濕潤冬季干燥某補課班 在中午附近有驟增熱帶季風氣候 旱雨季節分明
選取典型氣候類型地區:新加坡、哈爾濱、南京、烏魯木齊、新德里。收集歷史平均月降水量數據如下(單位:mm):
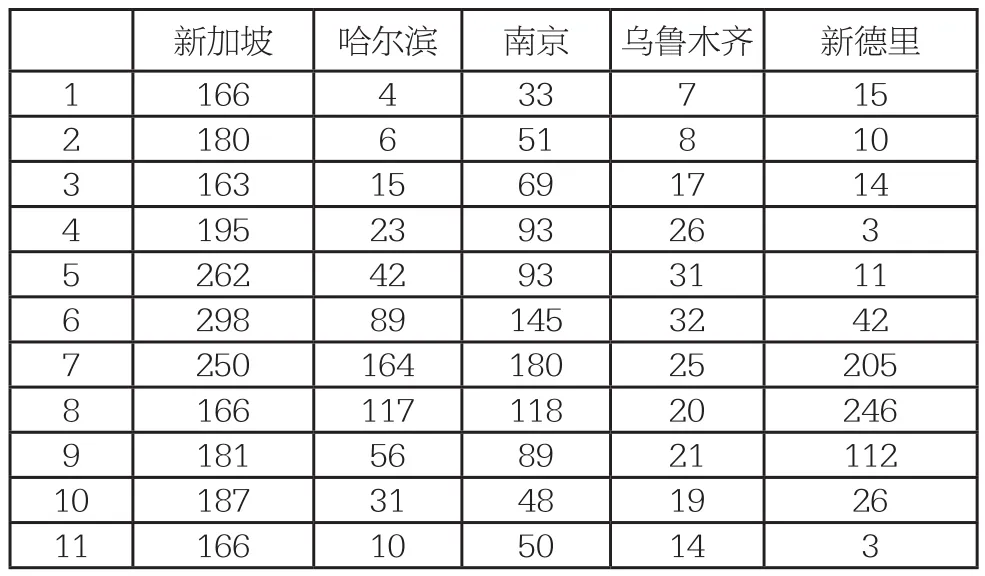
新加坡 哈爾濱 南京 烏魯木齊 新德里1 166 4 33 7 15 2 180 6 51 8 10 3 163 15 69 17 14 4 195 23 93 26 3 5 262 42 93 31 11 6 298 89 145 32 42 7 250 164 180 25 205 8 166 117 118 20 246 9 181 56 89 21 112 10 187 31 48 19 26 11 166 10 50 14 3
由此可見,區域外賣騎手數量分布與與其相對應的地區降水量分布十分相似,故以此為基礎建立模型。
3.模型目的
通過訓練,模型能夠接受一組從7:30~19:30每隔一小時的外賣騎手數量,輸出五種人群特點的可信度。
4.數據收集及前期處理
(1)數據收集
從GHCN數據庫、環境云和Global Weather Data for SWAT上收集上述地區歷年的降水量數據作為訓練數據,選取一小部分數據作為降水量—氣候類型驗證數據,將區域外賣騎手數量作為外賣騎手數量—人群特點驗證數據。
(2)數據前期處理
由于降水量數據與外賣騎手數量量級并不相同。對于人眼,在觀測折線統計圖時,主要觀測的是數據之間的相對大小關系以及數據(y)隨時間或者月份(x)的變化趨勢。因此,為統一數據量級,防止深層神經網絡模型出現學習方向的錯誤,將每個數據除以12個單位時間或者月份(x),五種氣候類型或者人群特點的總共60個數據的和,使降水量數據與騎手數據量級相似使大部分數據在0~1之間。
5.模型建立
此模型總共有六層,分別是:批規范層(Batch Normalization),全連接層,丟棄層(Dropout),全連接層,全連接層,批規范層。
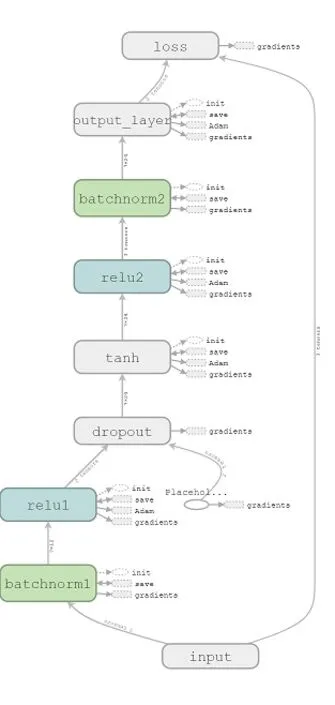
6.模型訓練
(1)訓練參數
經過多次實驗比對,此模型采用全部數據以每10個為一批(Batch)輸入至網絡,訓練時將全部數據完整地訓練100次(epoch=100)的方法。將模型誤差、降水量驗證結果與外賣騎手數量驗證結果輸出。
(2)訓練結果
訓練后,保存訓練日志。使用可視化工具TensorBoard查看模型誤差,并且使用TensorBoard畫出降水量驗證結果與外賣騎手數量驗證結果折線圖。
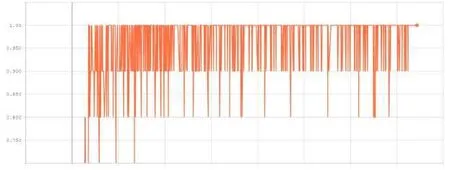
降水量分類正確率如下(Smoothing=0):
外賣騎手數量分類正確率如下(Smoothing=0.9):
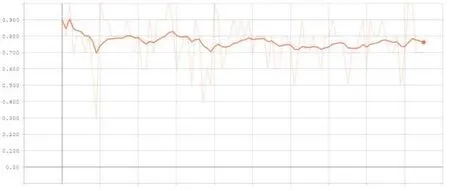
從圖像中得出,經過100輪(epoch)的訓練,降水量模型的訓練誤差在0和0.2之間,降水量的分類正確率幾乎達到了100%,外賣騎手數量的分類正確率在75%到80%之間。
(7)模型結論
基于所處地人群特點與氣候類型,所處地12個小時外賣數量與特定氣候類型月平均降水量的相似性,建立深層神經網絡模型,通過不斷調整超參數,得出較為完善的模型,并進行訓練,使得此模型滿足模型目的,即,輸入12個小時的外賣騎手數量,可以得出一個正確率在75%到80%的人群特點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
