結合主動學習和密度峰值聚類的協同訓練算法
2019-10-23 12:23:56龔彥鷺呂佳
計算機應用 2019年8期
關鍵詞:主動學習
龔彥鷺 呂佳

摘 要:針對協同訓練算法對模糊度高的樣本容易標記錯誤導致分類器精度降低和協同訓練在迭代時選擇加入的無標記樣本隱含有用信息不夠的問題,提出了一種結合主動學習和密度峰值聚類的協同訓練算法。在每次迭代之前,先選擇模糊度高的無標記樣本主動標記后加入有標記樣本集,然后利用密度峰值聚類對無標記樣本聚類得到每個無標記樣本的密度和相對距離。迭代時選擇具有較高密度和相對距離較遠的無標記樣本交由樸素貝葉斯(NB)分類,反復上述過程直到滿足終止條件。利用主動學習標記模糊度高的樣本能夠改善分類器誤標記識別問題,利用密度峰值聚類能夠選擇出較好表現數據空間結構的樣本。在UCI的8個數據集和Kaggle的pima數據集上的實驗表明,與SSLNBCA算法相比,所提算法的準確率最高提升6.7個百分點,平均提升1.46個百分點。
關鍵詞:協同訓練;主動學習;密度峰值;樸素貝葉斯;視圖
中圖分類號:?TP181
文獻標志碼:A
Co-training algorithm with combination of active learning and density peak clustering
GONG Yanlu1,2,LYU Jia1,2*
1.College of Computer and Information Sciences, Chongqing Normal University, Chongqing 401331, China;
2.Chongqing Center of Engineering Technology Research on Digital Agriculture Service, Chongqing Normal University, Chongqing 401331, China
Abstract:?High ambiguity samples are easy to be mislabeled by the co-training algorithm, which would decrease the classifier accuracy, and the useful information hidden in unlabeled data which were added in each iteration is not enough. To solve these problems, a co-training algorithm combined with active learning and density peak clustering was proposed. Before each iteration, the unlabeled samples with high ambiguity were selected and added to the labeled sample set after active labeling, then density peak clustering was used to cluster the unlabeled samples to obtain the density and relative distance of each unlabeled sample. During iteration, the unlabeled samples with higher density and further relative distance were selected to be trained by Naive Bayes (NB) classification algorithm. The processes were iteratively done until the termination condition was satisfied. Mislabeled data recognition problem could be improved by labeling samples with high ambiguity based on active learning algorithm, and the samples reflecting data space structure well could be selected by density peak clustering algorithm. Experimental results on 8 datasets of UCI and the pima dataset of Kaggle show that compared with SSLNBCA (Semi-Supervised Learning combining NB Co-training with Active learning) algorithm, the accuracy of the proposed algorithm is up to 6.67 percentage points, with an average improvement of 1.46 percentage points.
Key words:?co-training; active learning; density peak; Naive Bayes (NB); view
0 引言
半監督學習(Semi-Supervised Learning, SSL)[1-2]包括自訓練、協同訓練、生成式模型、基于圖的半監督學習等,旨在利用少量的有標記樣本和大量的無標記樣本來訓練分類器。其中,協同訓練在多個視圖上訓練出多個分類器,通過分類器之間的協同作用得到無標記樣本的類標號。經典的協同訓練方法在兩個充分冗余且獨立的視圖上進行,然而現實生活中的數據很少能夠滿足充分冗余且獨立的條件,因此提出了其他假設的協同訓練方法來放松條件。文獻[3]中的研究表明,當數據集充分大時,在隨機劃分的特征集上進行協同訓練會具有很好的效果,但該算法不具有穩定性。Du等[4]提出了啟發式分割方法,將一個視圖分割為兩個視圖,但這種方法在有標記樣本數量很少時表現很差。tri-training[5]是一種新的具有協同訓練模式的算法,這種算法既不需要用足夠冗余的視圖表現數據空間,也沒有對監督學習算法提出任何約束,因此具有較強的適用性,但是在協同訓練的過程中,分類器易誤標記模糊度高的樣本導致錯誤累積,而如何從無標記樣本中選擇可靠的樣本加入訓練集,也是學者研究的熱點問題。
主動學習通過選擇最有用的無標記樣本交由專家標記來提高分類器的性能[6]。Sener等[7]將主動學習的問題定義為核心集的選擇,并將這種方法運用到卷積神經網絡中;Piroonsup等[8]通過聚類來實現主動學習,利用改進后的k-means聚類算法得到無標記種群的質心,再選擇離質心近的樣本進行主動標記;Wang等[9]研究表明,分類器輸出的具有較高模糊度的樣本意味著更大的錯誤分類風險,處理高模糊度的樣本是促進分類器性能的有效方法。
在協同訓練方法中,無標記樣本的有效選取也是提高分類器性能的重要步驟。Zhang等[10]根據高置信度和最近鄰兩個準則選擇最可靠的實例,以此來增強分類器的性能;但該算法在非小樣本數據集上性能表現不佳。考慮到無標記樣本隱含的空間結構信息,Gan等[11]用半監督模糊C均值聚類選取隱含有用信息量高的無標記樣本來輔助訓練分類器;但歐氏距離對于反映屬性之間的相關性效果很差,而且很難確定合適的參數。龔彥鷺等[12]考慮到無標記樣本隱含的空間結構信息和協同標記的一致性,提出了結合半監督聚類(Semi-supervised Metric-based fUzzy Clustering, SMUC)和加權KNN(K-Nearest Neighbor)的協同訓練方法,該方法能夠有效地選擇無標記樣本,但計算成本較高。Rodriguez等[13]提出了密度峰值聚類,這種方法將聚類中心定義為密度高且相對距離較大的點,實驗表明其具有不受數據集形狀影響的良好性能,基于此特性,密度峰值聚類在數據空間表現上得到了廣泛的應用。Wu等[14]利用密度峰值聚類發現數據空間結構,提出了一種自訓練半監督分類框架,將數據空間的結構融入自訓練迭代過程中,以此幫助訓練更好的分類器。羅云松等[15]將密度峰值聚類與模糊聚類結合起來,用密度峰值優化模糊聚類,并將改進后的方法用在自訓練中,提高了自訓練方法的泛化性。
基于以上考慮,本文提出了結合主動學習和密度峰值聚類的協同訓練方法,實驗結果表明,該方法相比改進前的方法具有更好的性能。
1 本文算法
傳統的協同訓練算法在選擇無標記樣本時未考慮到高模糊度樣本對分類器的影響,在迭代的過程中會造成分類器的錯誤累積問題。針對這種具有較高誤判風險的高模糊度樣本,如果能夠正確處理,不僅可以避免分類器的錯誤累積而且能夠利用高模糊度樣本的信息,從而提高分類器的性能。故采用主動學習的方法去標記高模糊度的樣本使分類器的性能得到提升。此外,考慮到無標記樣本中隱含的空間結構信息以及密度峰值聚類在任意數據集上良好的性能表現,采用密度峰值聚類計算每一個無標記樣本的密度和相對距離,以此來作為無標記樣本的選擇依據。因挑選的無標記樣本是具有代表性的密度較高且相對距離較遠的樣本,故分類器在訓練的過程中能夠利用這些有用信息來提高性能。
1.1 主動學習
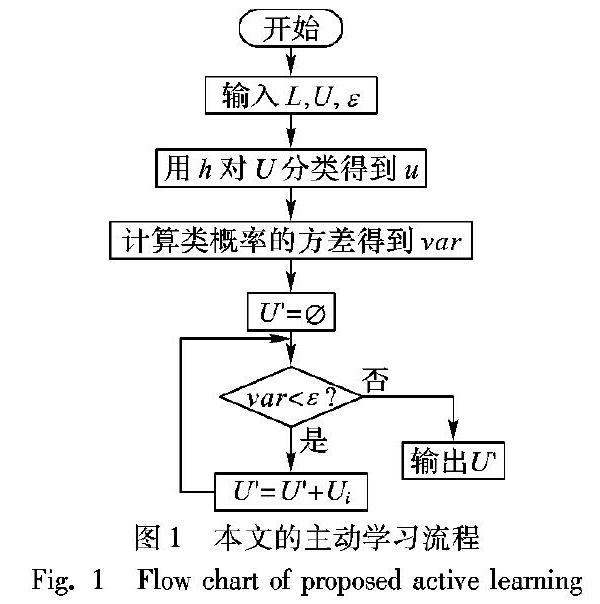
主動學習的思想是通過選擇一些有價值的樣本給專家主動標記從而獲得性能更好的分類器,降低領域專家的工作量。如何高效地選擇有價值的樣本是主動學習領域一直在探討的問題。本文將模糊度高的樣本定義為有價值的樣本,而對于模糊度的計算,先采用樸素貝葉斯(Naive Bayes, NB)對無標記樣本進行分類得到屬于每個類的概率,再用同一樣本的不同類別概率的方差來表示模糊度。同一樣本屬于不同類別概率的方差越小,表示該樣本的不確定性越大,模糊度越高,越有價值。本文主動學習算法的流程如圖1所示,其中,參數ε是控制主動學習標記的無標記樣本個數。
1.2 密度峰值聚類
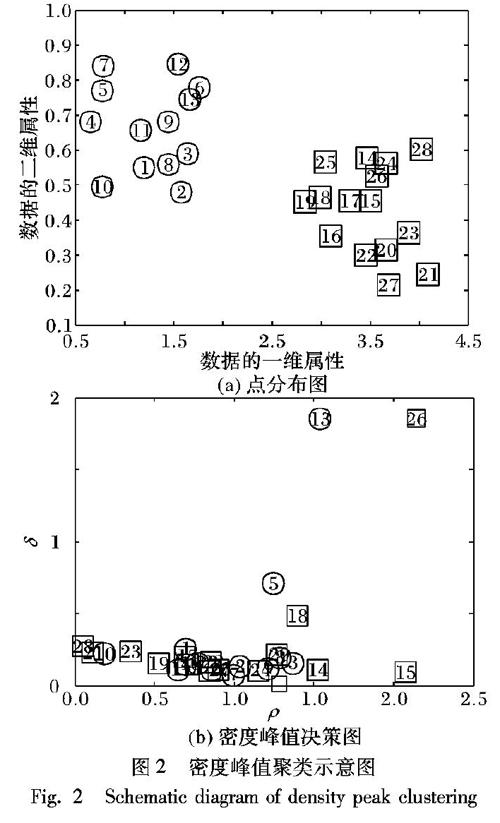
密度峰值聚類基于兩個簡單、直觀的假設:1)類簇中心點的密度大于周圍鄰居點的密度;2)類簇中心點與更高密度點之間的距離相對較大。根據這兩個假設,密度峰值聚類首先發現密度峰,將其標為聚類中心,然后將其他的點分類到相應的簇中,因此,該方法能自動發現數據集的聚類中心,實現任意形狀數據集的高效聚類。
在密度峰值聚類里,對于每一個樣本點,都需要計算局部密度ρ和相對距離δ。
局部密度ρ的計算公式如下:
ρi=∑ j≠i χ(dij-dc) (1)
其中dc是截斷距離。
dij=‖xi-xj‖2 (2)
χ(x)= 1,? x<00, 其他?? (3)
為了避免dc的影響,密度峰值聚類采用如下方式計算ρ:
ρi=∑ j≠i exp(-(dij/dc)2) (4)
相對距離δ的計算公式如下:
δi=min j:ρj>ρi (dij) (5)
對于具有局部密度最大的數據點,相對距離δ的計算公式如下:
δi=max j (dij) (6)
利用得到的局部密度ρ和相對距離δ,畫出ρ和δ的決策圖,然后手動選擇密度高且相對距離大的點作為聚類中心,并將其他的樣本點歸入局部密度大于自身且距離最近的樣本點所在的類簇中,完成對剩余樣本的分配。圖2是密度峰值聚類的一個例子,該例子表現了選擇聚類中心的過程,其中,圖2(a)表示二維空間中的28個樣本點,圖2(b)是利用密度峰值聚類得到的決策圖。
1.3 本文算法流程
考慮到分類器對高模糊度樣本有較高的誤判風險,本文先計算每個樣本屬于不同類別概率的方差,再選擇方差小的樣本作為高模糊度樣本,并將這些樣本交給專家主動標記后加入有標記樣本集。為了利用無標記樣本中的隱含信息,對無標記樣本進行密度峰值聚類得到每個樣本的密度和相對距離,而后迭代地選取密度較高且相對距離較遠的無標記樣本給分類器標記。具體算法流程如下所示。
輸入:有標記樣本集L,無標記樣本集U,模糊度參數ε,每次從U中挑選樣本的個數c,dc。
輸出:最終訓練好的分類器h1、h2。
步驟1? 在L上訓練得到樸素貝葉斯分類器h。
步驟2? 用h對U分類得到每個類的隸屬度u。
步驟3? 計算U中每個樣本隸屬度的方差得到var。
步驟4? 選擇滿足var<ε的無標記樣本U′。
步驟5? 將U′交給專家標識,得到類別號l′。
步驟6? L=L+(U′+l′),U=U-U′。
步驟7? 對U進行密度峰值聚類,得到每個樣本的密度ρ和相對距離δ。
步驟8? 按照ρ+δ從大到小的順序對U排序。
步驟9? 選擇U中前c個樣本構造樣本集R。
步驟10? 如果U中樣本數不足c個,則U=R。
步驟11? 在采用屬性集合互補方式產生的兩個不同視圖上,利用L分別訓練出兩個分類器h1和h2,用訓練得到的分類器對R分類。
步驟12? 若h1和h2對R中的樣本分類一致,則將該樣本加入到L中;否則,用加權K最近鄰對該樣本分類得到類標號,然后再將其加入到L。
步驟13? U=U-R,若U集不為空,返回步驟9。
2 實驗結果與分析
為了說明本文算法的有效性,選擇NB協同訓練(NB Co-Training, NBCT)算法、結合SMUC的NB協同訓練(NB Co-Training combined SMUC, NBCTSMUC)算法、結合主動學習的NB協同訓練(NB Co-Training combined Active Learning,NBCTAL)算法和基于文獻[10]的NB協同訓練(Semi-Supervised Learning combining Co-training with Active learning, SSLNBCA)算法與本文算法進行對比實驗。實驗數據集來源于UCI中的8個數據集和Kaggle數據集中的pima數據集,數據集描述如表1所示。
為了保證實驗準確性,實驗采用十折交叉驗證,將數據集隨機劃分為10折,其中訓練集由其中的9折組成,測試集由剩下的1折組成。實驗參數設置如下:dc=2,c為主動學習后無標記樣本數的10%。實驗中,在訓練集中隨機選取10%的樣本作為初始有標記樣本,其余樣本去除類標記作為無標記樣本。
2.1 實驗一
為了分析參數ε的變化對本文提出算法的影響,實驗一在有標記樣本占比為15%時,得到了在9個數據集上當ε=0,0.01,0.03,0.05,0.07,0.09時本文算法的準確率,實驗結果如圖3所示。為表示方便,圖3中數據集名稱用縮寫表示。
從圖3可以看出,當ε=0.01時,本文算法在9個數據集上的準確率比ε=0時高。隨著參數ε的增加,雖然在多數情況下準確率比ε=0時高,但是對比ε=0.01,準確率并沒有表現出明顯穩定上升。在分類器的性能表現方面,ε=0.01和ε=0.09時要更優,考慮到利用主動學習標記無標記樣本的成本,選擇ε=0.01。
2.2 實驗二
為了說明本文算法在時間成本上低于NBCTSMUC,實驗二在數據集wine計算了當十折交叉驗證運行次數為1、2、3、4、5時,本文算法與NBCTSMUC需要的時間,實驗結果如圖4所示。
圖4表明,本文算法在時間消耗方面要遠低于文獻[12]中提出的利用SMUC選擇無標記樣本的方法,因此對比SMUC,密度峰值聚類明顯具有更低的計算成本。
2.3 實驗三
為了說明本文算法的有效性,表2給出了5種算法在9個數據集上兩個視圖平均分類正確率的實驗結果。
如表2所示,當有標記樣本比例為10%時,除了數據集ionosphere和banknote authentication,本文算法在其他7個數據集上性能均優于對比算法。在數據集Ecoli、Iris、seeds上的準確率分別提升了3.8個百分點、5.3個百分點、4.29個百分點。這是因為算法在迭代之前選擇模糊度高的樣本主動標記,避免了樣本錯誤的類標簽造成的分類器錯誤累積問題,對于在迭代過程中加入的無標記樣本,本文算法在此之前按照密度和相對距離對這些樣本進行了排序,保證了每次給分類
器分類的樣本都比下一次的更具代表性;而在數據集
ionosphere和banknote authentication上,本文算法的性能表現得比對比算法弱,這可能是因為按密度峰值選擇無標記樣本進行標記這種方式并不適合該樣本集,而NBCTAL的準確率高于NBCT,這表明利用主動學習擴充訓練集的方式是可行性。在數據集wine上,NBCTAL的準確率略低于NBCT,這可能是因為wine數據集本身并不具有模糊度高的較難分的樣本,故利用主動學習去標記模糊度高的樣本可能并不適用此數據集。
2.4 實驗四
為了說明5種算法在9個數據集上的分類準確率與有標 記樣本比率的關系,圖5給出了當初始有標記樣本比例分別為10%、20%、30%、40%、50%時5種算法在9個數據集上的分類準確率。
從圖5可以看出,在數據集pima、Ecoli、Breast Cancer Wisconsin (Original)、Iris、wine上,本文算法的性能均高于對比算法。在數據集abalone和數據集banknote authentication,隨著有標記比例的增加,本文算法的性能弱于對比算法,這可能是因為當有標記比例增加后,未標記樣本中的模糊數據變少,利用主動學習標記模糊數據方法的效果變差。在數據集ionosphere上,雖然當有標記比例為10%和20%時,本文算法在性能上表現得比對比算法差;但隨著有標記樣本數的增加,當有標記比例為30%、40%和50%時,本文算法分類性能要高于對比算法。這可能是因為在數據集ionosphere上,過少的初始有標記樣本導致分類器學習的效果不好。
2.5 時間復雜度分析
表3給出了5種算法的時間復雜度,其中n為數據集樣本個數,m為NBCTSMUC迭代過程中每次選擇無標記樣本的個數。從表3可以看出,除NBCTSMUC外,其他算法的時間復雜度皆為O(n2)。
本文算法的時間復雜度由主動學習、密度峰值聚類和樸素貝葉斯協同訓練三個部分組成,各部分的時間復雜度都為O(n2),故本文算法總的時間復雜度為O(n2);NBCT迭代計算每一個樣本的概率,時間復雜度為O(n2);NBCTAL的時間復雜度由主動學習和樸素貝葉斯協同訓練兩部分組成,其時間復雜度分別為O(n)和O(n2),所以NBCTAL總的時間復雜度為O(n2);SSLNBCA的時間復雜度為O(n2),由樣本選取、主動標記和樸素貝葉斯協同訓練三部分組成;NBCTSMUC在n/m次迭代中計算每個樣本的每個類別的馬氏距離,時間復雜度為O(n5/m)。
3 結語
針對協同訓練方法對模糊度高的樣本容易誤標記和在迭代過程中加入的無標記樣本所含有用信息量不高的問題,本文提出了一種結合主動學習和密度峰值聚類的協同訓練方法。該方法在每次迭代之前,先選擇出模糊度高的無標記樣本主動標記后加入有標記樣本集,然后用密度峰值聚類對訓練集進行聚類,迭代地選取密度較高且相對距離較遠的無標記樣本給NB分類,最后在UCI數據集上驗證了算法的有效性。在后續的工作中,將討論最優參數以及如何判別噪聲點和如何減少噪聲點對算法的影響。
參考文獻
[1]?GOUTTE C, CANCEDDA N, DYMETMAN M, et al. Semi-supervised learning for machine translation[J]. Journal of the Royal Statistical Society, 2017, 172(2): 530-530.
[2]?ZHU S, SUN X, JIN D. Multi-view semi-supervised learning for image classification [J]. Neurocomputing, 2016, 208(10): 136-142.
[3]?XU C, TAO D, XU C. Large-margin multi-view information bottleneck[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(8): 1559-1572.
[4]?DU J, LING C X, ZHOU Z H. When does cotraining work in real data?[J]. IEEE Transactions on Knowledge and Data Engineering, 2011, 23(5): 788-799.
[5]?QIAN T, LIU B, CHEN L, et al. Tri-training for authorship attribution with limited training data: a comprehensive study[J]. Neurocomputing, 2016, 171(1): 798-806.
[6]?DEKEL O, GENTILE C, SRIDHARAN K. Selective sampling and active learning from single and multiple teachers[J]. Journal of Machine Learning Research, 2016, 13(1): 2655-2697.
[7]?SENER O, SAVARESE S. Active learning for convolutional neural networks: a core-set approach[J]. arXiv E-print, 2017: arXiv:1708.00489.
[8]?PIROONSUP N, SINRHUPINVO S. Analysis of training data using clustering to improve semi-supervised self-training[J]. Knowledge-Based Systems, 2018, 143(2): 65-80.
[9]?WANG X Z, ASHFAG R A R, FU A M. Fuzziness based sample categorization for classifier performance improvement[J]. Journal of Intelligent and Fuzzy Systems, 2015, 29(3): 1185-1196.
[10]?ZHANG Y, WEN J, WANG X, et al. Semi-supervised learning combining co-training with active learning[J]. Expert Systems with Applications, 2014, 41(5): 2372-2378.
[11]?GAN H, SANG N, HUANG R, et al. Using clustering analysis to improve semi-supervised classification[J]. Neurocomputing, 2013, 25(3): 290-298.
[12]?龔彥鷺,呂佳.結合半監督聚類和加權KNN的協同訓練方法[J/OL].計算機工程與應用,2019:1-9[2018-12-28]. http://kns.cnki.net/kcms/detail/11.2127.TP.20181218.1748.032.html. (GONG Y L, LYU J. Co-training method combined semi-supervised clustering and weighted K nearest neighbor[J/OL]. Computer Engineering and Applications,2019: 1-9[2018-12-28]. http://kns.cnki.net/kcms/detail/11.2127.TP.20181218.1748.032.html.)
[13]?RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492-1496.
[14]?WU D, SHANG M S, LUO X, et al. Self-training semi-supervised classification based on density peaks of data[J]. Neurocomputing, 2018, 275(1): 180-191.
[15]?羅云松,呂佳.結合密度峰值優化模糊聚類的自訓練方法[J].重慶師范大學學報(自然科學版),2019,36(2):74-80. (LUO Y S, LYU J. Self-training algorithm combined with density peak optimization fuzzy clustering[J]. Journal of Chongqing Normal University (Natural Science), 2019, 36(2): 74-80.)
猜你喜歡
文藝生活·中旬刊(2016年11期)2016-12-13 23:52:18
成才之路(2016年36期)2016-12-12 14:17:24
文藝生活·下旬刊(2016年11期)2016-12-12 09:49:36
新教育時代·教師版(2016年27期)2016-12-06 16:03:32
新課程·中旬(2016年9期)2016-12-01 11:51:59
中學課程輔導·教師教育(上、下)(2016年20期)2016-12-01 01:40:53
東方教育(2016年16期)2016-11-25 03:06:31
化學教與學(2016年10期)2016-11-16 13:29:16
人間(2016年28期)2016-11-10 22:12:11
計算機教育(2016年7期)2016-11-10 08:44:58
