
基于輕量化神經網絡的司機使用手機行為檢測
2020-02-22 06:52:26李欣旭
科技創新導報 2020年26期
關鍵詞:深度學習
李欣旭
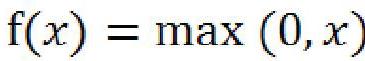
摘? 要:在司機駕駛車輛過程中,利用深度學習與神經網絡等方法對其使用手機的行為進行檢測,比使用傳統視覺檢測方法具備更高的精度與穩定性。本文基于MobileNet神經網絡搭建輕量化辨識模型。同時,本文還采集了司機駕駛圖像以構建數據集,并將數據集用于訓練模型。最后,構建檢測算法在測試集上進行驗證。此方法性能穩定,輕量化程度高,適用場景廣泛。
關鍵詞:司機狀態? 手機檢測? 深度學習? 輕量化
中圖分類號:TN219;TP183? ? ? ? ? ? ? ? ?文獻標識碼:A? ? ? ? ? ? ? ? ?文章編號:1674-098X(2020)09(b)-0111-04
Abstract: Deep learning and neural networks have higher accuracy and stability than traditional visual inspection methods in the field of image processing, such as detecting the driver's behavior of using mobile phone when the driver is driving a vehicle. Based on MobileNet, we build a lightweight neural network detecting model, collect driver driving images datasets for training the model, and develop an algorithm to verify this model.Our method has stable performance, a lightweight structure, and wide application prospects.
Key Words:Driver status; Mobile phone detection; Deep learning; Lightweight
汽車的出現使得人類出行更加便利,但是也帶來了交通事故從而威脅到了生命財產安全。因此,司機在行車時需要保持高度集中以進行符合規范的安全駕駛。但是隨著智能手機的發展,人們在日常生活中使用手機越來越頻繁,不少司機在駕駛過程中出現了使用手機的情況,這樣會大幅度降低司機的注意力,從而造成嚴重的交通事故。因此,研究一種全天候實時非接觸式的對司機駕駛過程中使用手機的監控安防措施尤為重要。
1? 基于MobileNet的司機使用手機狀態檢測方法
隨著深度學習的發展,卷積神經網絡的應用變得越來越普遍。深度神經網絡因為具有自學習的特性,所以擁有更大的機會去提取獲得數據中的有效信息。通常,使用更深更復雜的神經網絡可以提高檢測的精度,但是這種神經網絡模型在存儲空間的占用以及對運行資源的消耗上都不太樂觀。此外,也存在一些使用輕量化神經網絡模型工程化應用的案例,例如MobileNet[1]、ShuffleNet[2]、GoogleNet[3]等,在提升運算速度的同時,盡可能維持較好檢測效果。
本文所針對是在司機駕駛過程中檢測其是否使用手機的場景,該場景通常被期望作為一個功能模塊被集成進司機監控系統中。這種系統一般采用嵌入式平臺,其硬件資源有限,因此需要盡可能降低算法對硬件資源的消耗,故而本文使用輕量化神經網絡MobileNet解決上述問題。
1.1 神經網絡模型結構
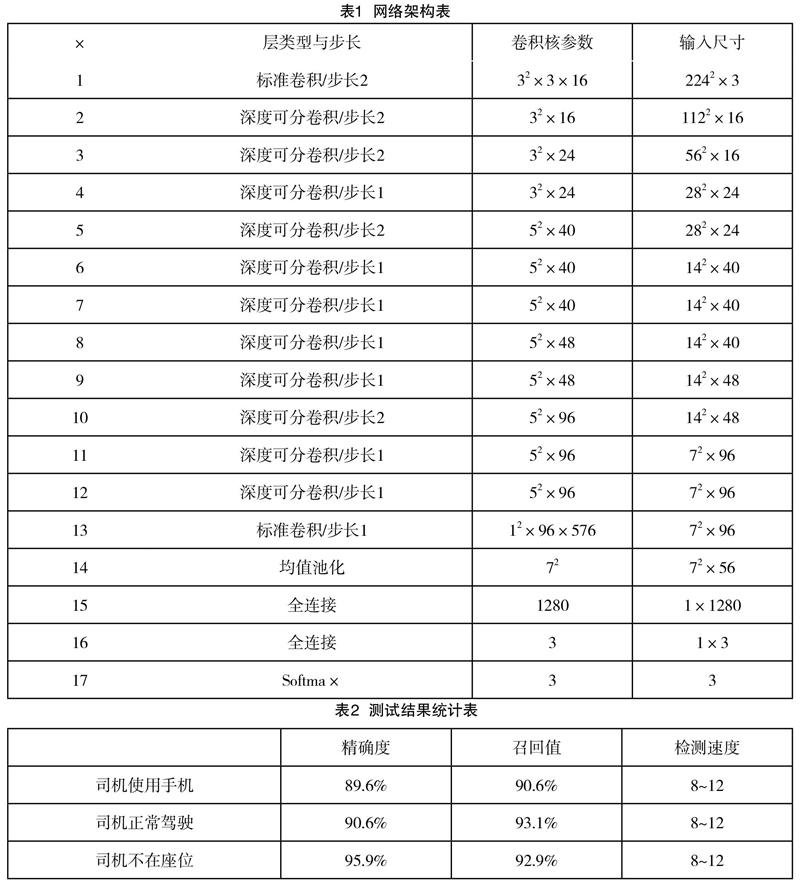
MobileNet與傳統神經網絡的區別在于卷積過程的不同。對于一個典型的標準卷積,通常采用若干個3×3的卷積核對輸入的多通道圖像/特征圖進行卷積。其中,每個卷積核都會對所有通道上的圖像/特征圖進行卷積,從而生成一張新的特征圖。但是MobileNet采用的是深度可分卷積。對于深度可分卷積分,首先使用給定的卷積核尺寸對每個通道分別卷積并將結果組合,該部分被稱為深度卷積。隨后,深度可分卷積使用單位卷積核進行標準卷積并輸出特征圖,該部分被稱為逐點卷積。如圖1所示,深度可分卷積首先采用深度卷積對不同的輸入通道分別進行卷積,然后采用逐點卷積將上面的輸出結果進行整合。
卷積過程中也會進行“批規范化”操作和“激活”操作,批規范化能夠使得輸出結果的各個維度的均值為0,方差為1。激活函數則一般采用ReLU,其函數表達式如下式所示:
一個深層可分卷積過程和一個標準卷積過程輸出的結果相差不明顯,對于以3×3為卷積核的標準卷積,除去“批規范化”計算和“激活”計算過程,深度可分卷積的計算量約為標準卷積權重數的10%~25%。
本文所用神經網絡結構如表1所示。首先是一個3×3的標準卷積,后面則是深層可分卷積與標準卷積的堆疊與組合。網絡尾部設置了兩個全連接層,輸出數量根據預測類別數量決定,最后是一個Softmax函數。按照MobileNet-Smal版結構搭建模型以進一步減少了網絡層數,以期望在保持檢測效果的同時,進一步降低計算資源消耗。
1.2 模型訓練過程
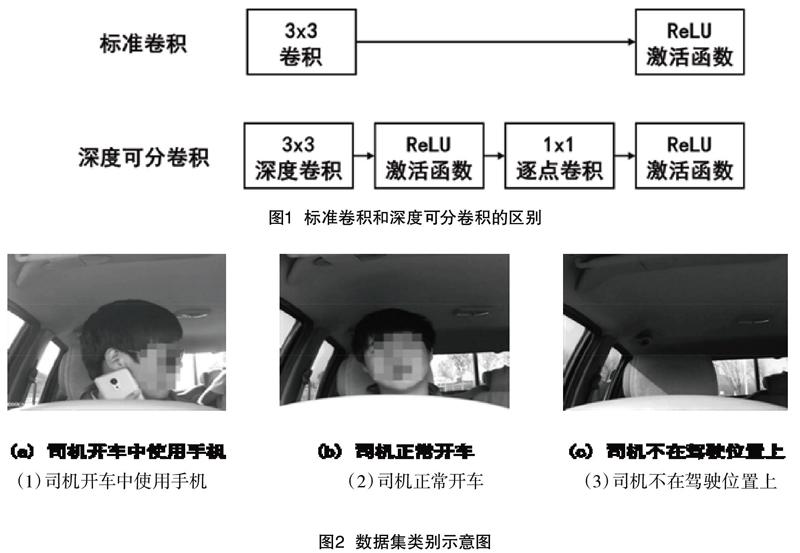
本文將攝像頭放置于汽車方向盤位置附近,采集如圖2所示視角的司機駕駛圖像,從而構建數據集。數據集中包含三類情況:(1)司機在開車中使用手機;(2)司機正常開車;(3)司機不在駕駛位置上。并使用這些數據集訓練上述神經網絡模型。
訓練時使用交叉熵損失函數,公式如下式所示:
訓練過程中,使用小批量梯度下降方法,取128個樣本為一個批量,學習率開始設為0.01。每學習完100次全部樣本后,學習率降為原來的1/10。每訓練一個批量的樣本后,網絡的權重都會被反向更新, 當損失值變化隨訓練過程趨于穩定之后,則停止訓練,輸出神經網絡模型。
2? 狀態檢測功能算法實現
在算法實現上,本文使用python語言與PyTorch庫實現神經網絡模型的搭建與訓練工作,并在以上基礎上建立了流程為:“讀取圖片-輸入網絡-計算結果-統計結果”的測試算法,并對結果進行了統計與評估。
在檢測精度方面,本文使用精確度與召回值來評估。精確度與召回值的值都在0~1之間。召回率的值越高表示算法的漏檢越低,精確度的值越高表示算法的誤檢越低。在檢測速度方面,本文將算法部署在英偉達Nano上,并將大小為1920×1080的圖片作為輸入,然后統計算法每秒能夠處理的圖片數量作為檢測速度。最終在測試集上得到檢測精度和速度結果如表2所示。
3? 結語
本文主要針對司機駕駛過程中使用手機的行為檢測場景,通過分析實拍采集的真實視頻數據,采用輕量化深度神經網絡模型提取數據特征、識別行為結果。本文算法識別精度較高,并且是“輸入-輸出”的端對端結構,易于使用,占用計算資源較少,具有工程化應用潛力。
本文算法通過增加數據集的數量,有望進一步提高識別精度。此外,如果將以PyTorch構建的神經網絡模型轉化為針對嵌入式設備的定制化模型(例如TensorRT、TVM、ONNX模型等),則可以進一步提升識別速度。
參考文獻
[1] 王傲然,劉瑋.TensorFlow平臺上基于MobileNet模型的商品識別[J].信息通信,2018(12):49-50.
[2] 陳明,李利軍,范戈.一種新型的ShuffleNet多跳等效時分復用網絡[J].光通信研究,2004(6):30-32.
[3] 白陽,萬洪林,白成杰.基于GoogLeNet的靜態圖像中人體行為分類研究[J].電腦知識與技術,2017,13(18):186-188.
[4] 馬秀梅,唐春暉,尹征,等.靜態圖像中的人體行為分類研究[J].信息技術,2015(4):98-101.
[5] 鄒佳悅.人體行為識別算法研究[D].秦皇島:燕山大學,2017.
[6] 楊紅菊,馮進麗,郭倩.基于多核學習的靜態圖像人體行為識別方法[J].數據采集與處理,2016,31(5):958-964.
[7] 劉照邦,袁明輝.基于深度神經網絡的貨架商品識別方法[J].包裝工程,2020,41(1):149-155.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
