大數據時代檔案信息資源共享平臺數據挖掘模型的研究與實現
2020-07-23 07:08:30卞咸杰
檔案管理 2020年4期
卞咸杰

摘? 要:隨著大數據時代技術的不斷發展以及檔案信息資源數據不斷積累,如何利用檔案信息資源大數據進一步提升檔案服務能力,促進檔案智能化管理能力提升,已經成為檔案部門的當務之急。在描述數據挖掘相關概念的基礎上,通過對數據挖掘技術在檔案信息資源共享平臺中應用的研究,從數據挖掘模型的確立、檔案信息資源數據選擇和檔案信息資源數據源創建等方面,論述平臺數據挖掘模型的建立,并在數據挖掘模型功能模塊、數據挖掘模型處理流程、數據挖掘模型樣本準備、預測模型創建和剖析模型集創建等方面進行實踐,驗證該模型的可行性,為實現檔案信息數字化全面發展的目標提供了更為有效的科學方案。
關鍵詞:大數據;檔案信息資源;共享平臺;數據挖掘;模型構建
Abstract:With the continuous development of technology in the era of big data and the continuous accumulation of archive information resource data, how to use archive information resource big data to further enhance archive service capabilities and promote the intelligent management of archives has become a top priority for archives departments. On the basis of describing the relevant concepts of data mining, through the research on the application of data mining technology in the archive information resource sharing platform, from the establishment of the data mining model, the selection of archive information resource data and the creation of archive information resource data sources, etc. The establishment of the data mining model, and practice in the data mining model function module, data mining model processing flow, data mining model sample preparation, prediction model creation and profiling model set creation, etc., to verify the feasibility of the model, in order to achieve archive information. The goal of comprehensive digital development provides a more effective scientific solution.
Keywords:Big data; Archive information resources; Sharing platform; Data mining; Model building
隨著數據技術的進步,數據價值在互聯網時代吸引了越來越多的關注。行業大數據的研究應運而生,過去不同部門掌握的傳統數據往往呈現出煙囪式孤島效應,相互之間有著巨大的關聯價值卻不能得到充分利用[1],檔案信息資源方面尤為明顯,檔案行業的信息化建設快速發展,數字檔案資源極大豐富,檔案數據挖掘成為了學界和業界研究的新方向[2]。信息技術的發展與進步,對檔案信息、數據進行深度的挖掘,使得檔案信息管理的各個要素形成內在聯系,充分實現檔案信息資源的共享[3],用戶對檔案服務要求的不斷提升,相關高層級的共享平臺建設也逐漸完善,平臺投入應用之后,檔案信息資源數據也急劇增加。目前對檔案信息資源數據的應用主要集中在現有數據的維護與檢索方面,數據挖掘的過程不僅僅是表層對數據的數值分析,更是基于內容的深層語義知識發現[4]。如何將現有的檔案信息數據利用效率最大化,數據挖掘的作用會顯現出來,從數據流挖掘的角度來看,大數據檔案信息資源數據挖掘處理是一個巨大的挑戰[5],通過檔案信息數據研究,并找出有價值的信息成為大數據平臺建成后需要重點關注的方向。通過檔案信息資源數據挖掘模型建立與實現,可以給檔案信息資源共享平臺提供數據挖掘方案作參考。
1 數據挖掘相關的概念
檔案信息資源共享平臺中的數據可以是結構化的,如關系型數據庫中的數據,也可以是半結構化的,如文本、圖形和圖像數據,甚至是分布在網絡中的非結構化數據[6]。數據挖掘是指從大量的、不完全的、有噪聲的、模糊的、隨機的實際應用數據中,提取隱含在其中的、人們事先不知道的、潛在有用的信息和知識的過程[7]。數據挖掘技術包括統計分析、序列模式發現、數據挖掘等[8],對于檔案信息資源共享平臺數據挖掘,包含預測任務和描述任務兩大類任務[9]。首先需要根據現有的檔案信息資源數據特點,建立數據分類,該分類作為預測目標數據的參考,分類任務完成后,需要通過回歸方式,來預測連續的目標參考數據;其次需要將檔案信息數據中聯系的方式進行標準化描述,如趨勢、軌跡等,數據挖掘任務的細化通常是探查性的工作,一般需要經過后繼數據處理來驗證和解釋前期數據挖掘的結果。
1.1 數據分析
隨著信息技術的發展,數學與計算機科學相結合產生了數據分析分支。對于檔案信息資源數據分析是采用合適的統計分析方法對收集來的檔案信息資源數據進行自動化分析,將采集到的數據加以匯總并得出統計報告信息,以求最大化地利用現有的檔案信息大數據,發揮共享平臺大數據的作用。檔案信息資源數據分析是為了提取有用信息和形成結論而對數據加以詳細研究和概括總結的過程。傳統的Excel自帶的數據分析功能基本可以滿足數據統計與數據分析的要求,該工具最終可以產生直方圖、相關系數、協方差、各種概率分布、抽樣與動態模擬、總體均值判斷等內容。現代的數據分析一般借用數據庫強大的數據分析功能,Microsoft SQL Server、Oracle等中大型數據庫自帶的數據分析工具,同時還可以根據需要配置數據報告。
1.2 數據挖掘
隨著大數據技術及人工智能技術的成熟,對數據的利用需求日益增長,數據挖掘研究在此背景下成為熱門的方向。從大量數據中挖掘出有用的信息,大數據的出現對傳統的簡單的數據挖掘算法提出挑戰[10],檔案信息資源的數據挖掘成為了當下熱門的話題,所謂檔案信息資源數據挖掘是指從檔案信息共享平臺大數據中發掘未知且不確定的并有潛在價值的信息的創造性決策支持過程,該過程依賴于數據庫技術、人工智能技術、數理統計、模式識別、可視化技術等相關現代化科技[11]。在數據挖掘的過程中將由傳統的半自動化向高度全自動化地分析檔案信息資源數據,通過設定的策略進行推理,從中挖掘出潛在的有價值數據,幫助檔案服務部門做出前瞻性決策。數據挖掘的對象不限源頭數據類型,這對于多媒體化的檔案信息資源特別有利,傳統的檔案信息資源一般采用結構化存儲方式,因為其存在形式主要為文本格式。隨著硬件設備配置的提升以及現代互聯網技術的發展,檔案信息資源的存在形式是多種形態并存,它可以是文本,圖像、視頻或結構化記錄[12],如列表和表格,此類數據中也可以包含非結構化數據。
1.3 數據挖掘中常見的分析方法
決策樹分析法。在檔案信息資源數據歸類與預測上有著極強的能力,該方法是以一連串的問題表示出來,經由不斷詢問問題,在該過程中不斷優化流程,最終能引導出預定的數據信息。
神經網絡分析法。該方法將一串待學習的檔案信息資源數據提交給神經網絡,使其歸納出有一定區分度的格式。若得到的是新的檔案信息資源數據,神經網絡即可以利用過去學習的成果并進行智能歸納后,推導出有價值的數據參考,自動學習推理的技能屬于人工智能領域的一個分支,通過不斷的數據學習,未來可以根據新提交的檔案信息資源數據自動給出預測結果。
連接分析法。該方法是以數學領域中的圖形理論為基礎,由不同數據的關系發展出一個模式。該方法的核心是數據關系,由人與人、物與物或是人與物的關系可以發展出相當多的智能化應用,未來可以做出對檔案服務能力提升更多的挖掘研究。
2 檔案信息資源共享平臺數據挖掘模型的建立
2.1 數據挖掘模型的確立
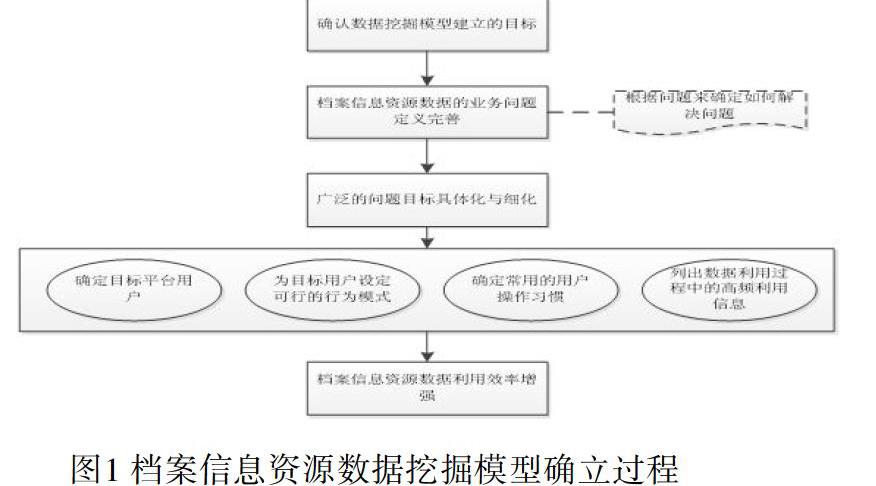
為了充分發揮檔案信息資源共享平臺的優勢,要結合用戶的實際需求建立完整的處理框架體系[13]。在實際做數據挖掘之前,首先需要確認數據挖掘模型建立的目標,在共享平臺數據挖掘模型建立之前,將檔案服務中涉及到檔案信息資源數據的業務問題定義完善,然后根據問題來確定如何解決問題,將廣泛的問題目標具體化與細化。在檔案信息資源數據挖掘模型建立過程中,可以按照確定目標平臺用戶、為目標用戶設定可行的行為模式、確定常用的用戶操作習慣、列出數據利用過程中的高頻利用信息、分析高頻數據訪問特點、為特定檔案信息資源數據建立特殊訪問通道,加強數據利用效率。具體確立流程如圖1所示:
在此過程中通過中間模型來翻譯輸入數據變量與目標變量的關系,這一步非常重要,對數據挖掘對象和任務的理解程度需要正確且深入。如果這個問題沒有被準確理解就無法把檔案信息資源數據轉化為挖掘任務。在實施數據挖掘任務之前,還需要明確如何使用檔案信息資源數據挖掘結果以及確定交付結果的方式。
2.2 檔案信息資源數據選擇
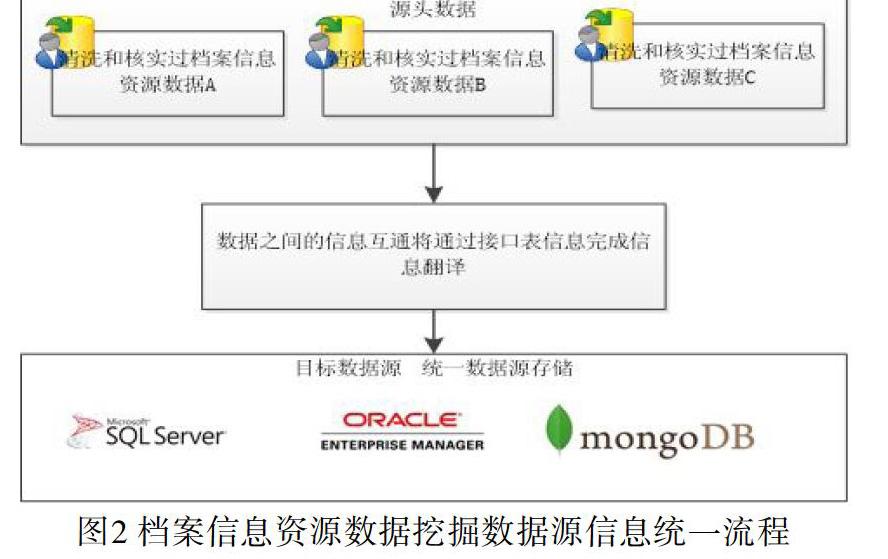
檔案信息資源數據存儲點首先在共享平臺所關聯的大數據平臺上,平臺數據的大幅增加對平臺自身來說是一項具有挑戰性的任務[14],存儲在倉庫中的檔案信息資源大數據在進入系統之前已經被清洗和核實過,共享平臺會通過數據整合技術將不同的數據資源進行整合。數據在實際的整合過程中,會遇到相同的信息點名稱但是表示不同的含義,這中間有一個數據遷移的過程,通過建立數據交互接口表,數據之間的信息互通將通過接口表信息完成信息翻譯。數據選擇與整理流程如圖2所示:
在建模構建期間,需要準備足夠的檔案信息資源數據并注意數據庫之間的平衡,這樣對于數據研究更加便捷。特定數據在數據集合中的存在會產生更大的價值。數據挖掘的本質是使用過去的數據預測未來的趨勢,針對檔案信息資源的數據挖掘,歷史上較新的信息對數據挖掘更加有價值,歷史太過靠前的數據,由于其信息本身的附加屬性信息較少,需要對這部分數據進行深加工,這樣才能發揮更久歷史的檔案信息資源數據的價值。
2.3 檔案信息資源數據源創建
在數據用于構建模型之前,數據探索方面需要得到足夠的重視,不能等后繼使用時才發現檔案信息資源的數據質量問題,在具體的數據源創建過重中,可以遵循以下步驟執行:
檢查檔案信息資源數據分布情況,在數據庫的初步探索階段,可以借助可視化工具。現存的可視化工具如Excel對待挖掘的檔案信息數據提供了強大的匯總分析支持。取得檔案信息資源數據源中的數據文件后,需要對其中的內容進行剖析,剖析的過程中可能會產生不一致問題或定義問題的警告,需要對問題數據進行分析并解決警告,這樣可以避免后繼分析產生不必要的麻煩。
經過檔案信息資源數據存儲的值與描述進行比較與二次確認,并對檔案信息資源大數據進行觀察,將它們與現有文件中的變量描述進行比較,可以發現有問題的數據描述。確定檔案信息資源存儲的數據與所要描述的數據一致性是非常重要的,每條記錄的字段定義信息要明確,這樣才不會導致后繼數據挖掘過程中的數據源頭不一致錯誤。對存在問題的檔案信息資源數據進行討論研究,檔案信息資源數據不同于普通業務系統的數據,其真實性與準確性要求非常高,如果存儲系統中的數據看上去有存疑,需要記錄下來。待問題數據積累到一定數量后進行溝通討論,研究出問題源頭,在今后的數據創建過程中避免問題的產生,這項工作需要耐心和細心,對檔案信息數據挖掘的成果尤為重要[15]。
3 檔案信息資源共享平臺數據挖掘模型的實現
3.1 數據挖掘模型功能模塊
檔案信息資源數據挖掘模型功能模塊主要由檔案信息資源數據采集模塊、存儲模塊、數據分類模塊、數據分析模塊等組成。數據采集模塊包含后臺管理數據采集與用戶行為數據采集,數據共享后會定期從公共接口進行數據交互,新產生的數據會收集到檔案信息資源共享平臺中。存儲模塊會定期將存儲到平臺的檔案信息資源數據進行備份,并自動處理歷史數據與當前操作數據分離,以提升數據挖掘模塊的數據操作性能。數據分類模塊通過利用檔案信息資源共享平臺獲取的原始數據,采用智能策略對檔案信息資源數據進行歸納與分離,該模塊是待挖掘源頭數據的最終達到預定目標的關鍵,良好的分類可以更好地發現有價值的結果。數據分析模塊是對分好類的數據進行智能化提取價值關鍵詞,該模塊是檔案信息資源數據挖掘的價值所在,該模塊通過減少對非關鍵數據的分析來提升數據挖掘效率。具體的功能模塊如圖3所示:
3.2 數據挖掘模型處理流程
檔案信息資源數據挖掘模型處理流程包括數據準備、數據預處理、數據挖掘、評價等幾個過程[16],數據準備階段是按用戶需求從檔案信息資源共享平臺上獲取基礎信息。數據預處理階段是將第一階段收集的大量不完善、模糊和冗余的數據進行預處理并轉換成準確有效的數據,在此流程中與數據挖掘相關的數據和屬性才可以被使用,該流程中使用了數據挖掘算法,為數據挖掘奠定了基礎。數據挖掘階段可分為三個部分,即確定挖掘及其知識類型、確定算法,根據算法進行數據的實際挖掘。評價階段主要時間預測結果驗證,不合格結果可按以上三步重新挖掘,直到預測結果符合要求,同時應刪除挖掘結果中的多余知識。檔案信息資源共享平臺數據挖掘模型的詳細處理流程如圖4所示:
3.3 數據挖掘模型樣本準備
不同于以往的標準統計分析,需要將超出正常范圍的數據舍棄以便于數據統計,在檔案信息數據挖掘的過程中,以往的非正常范圍數據可能正是數據挖掘的關鍵,在數據挖掘的樣本準備過程中,需要重視這部分數據并對其進行研究。知識發現算法需通過檔案信息資源原始數據來進行學習,如果沒有足夠數量的檔案信息資源大數據模型的例子,數據挖掘模型是無法得出期望的預測模型。在這種情況下,利用邊緣樣本來豐富樣本模型集,提高特定預測結果的成功率。檔案信息資源數據挖掘模型的建立需要一個較長的時序,基于較短時間建立的模型存在風險,最終得到的數據學習知識不能真實反映數據趨勢信息。在實際的時序應用中需要結合模型集中的多個時序信息以消除因時間推進帶來的趨勢分析影響。
3.4 預測模型創建
檔案信息資源數據挖掘模型用來預測時,需要明確模型集所占用的時間長度,同時需要將具體的時間段明確下來,預測模型就是要利用過去設定的模型,用來解釋最近的輸出。預測模型部署到正式環境后,能夠通過自我學習,運用不斷更新的數據預測未來。數據預測模型創建是動態的,通過模型預測的短期信息是不能作為未來預測模型的基礎數據輸入,如果在遠期數據預測中需要用到近期的預測信息,可行的方案是在模型集合中跳過近期預測數據輸入。
3.5 剖析模型集創建
檔案信息資源數據模型集與預測模型較為相似,不同點在于剖析模型集目標的時間幀與輸入的時間幀是重疊的。該差別對建模工作有非常大的影響,因為輸入可能使目標模式出現偏差,嚴格選擇剖析模型的輸入才能避免該問題的產生。當目標變量的時間幀與輸入變量的時間幀一致時,該模型即是一個剖析模型。剖析模型輸入變量可能會引入無固定的挖掘模式,而這些模式可能會混淆數據挖掘技術。
*2017年國家社科基金年度項目《大數據時代智慧檔案信息服務平臺構建與創新研究》(項目批準號:17BTQ074)階段性成果之一。
參考文獻:
[1]羅俊,于水,楊維,孔華鋒.實時大數據挖掘系統的設計與實現[J].計算機應用與軟件,2020(3):57-60+122.
[2]譚美琴,鄭川.檔案數據挖掘文獻統計分析[J].資源信息與工程,2019(4):166-168.
[3]倪一君.大數據技術與檔案數據挖掘分析[J].辦公室業務,2019(5):21+24.
[4]王萍,牟冬梅,石琳琚,沅紅.領域知識融合驅動下的數據挖掘模型構建與優化[J].情報理論與實踐,2018(9):114-117+153.
[5]Sonia Jaramillo Valbuena,Sergio Augusto Cardona,Alejandro Fernández.Minería de datos sobre streams de redes sociales,una herramienta al servicio de la Bibliotecología[J].Información,cultura y Sociedad,2015,33:63-74.
[6]楊尊琦.大數據導論[M].北京:機械工業出版社,2018.
[7]王競秋.數字·數據·知識:檔案資源開發利用形式的拓展與整合[D].南昌:南昌大學,2019.
[8]Rehab Duwairi,Ammari Hadeel.An enhanced CBAR algorithm for improving recommendation systems accuracy[J].Simulation Modelling Practice and Theory,2016,60:54-68.
[9]欒立娟,盧健,劉佳.數據挖掘技術在檔案管理系統中的應用[J].計算機光盤軟件與應用,2015(1):35-36.
[10]謝光.基于Map Reduce 的云數據挖掘模型的設計與實現[J].網絡安全技術與應用,2017(6):62-63+71.
[11]鄭斐,郭彥宏,郝俊勤,劉娜.數據挖掘技術如何在圖書館建設中體現價值[J].圖書情報工作,2013(S13):263-264+212.
[12]Hanane Ezzikouri,Mohamed Fakir,Cherki Daoui,Mohamed Erritali.Extracting knowledge from web data[J].Journal of Information Technology Research,2014,7(4):27-41.
[13]劉斌.檔案信息管理系統中的計算機數據挖掘技術探討[J].信息與電腦(理論版) ,2018(3):138-139+142.
[14]Hemant Kumar Singh,Brijendra Singh.A classification algorithm to improve the design of websites[J].Journal of Software Engineering and Applications,2012,5:492-499.
[15]王萍,牟冬梅,石琳,琚沅紅.領域知識融合驅動下的數據挖掘模型構建與優化[J].情報理論與實踐,2018(9):114-117+153.
[16]Cuiyuan Yu,Jie Shan.The application of web data mining technology in e-commerce[J].Advanced Materials Research.2014,1044:1503-1506.
(作者單位:鹽城師范學院? 來稿日期:2020-04-20)
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
