基于離散非策略Q-學習最優控制魯棒性研究
2020-11-06 13:54:56劉秋麗李金娜
現代信息科技 2020年12期
關鍵詞:學習
劉秋麗 李金娜


摘 ?要:針對離散系統魯棒非策略Q-學習算法的研究的必要性進行了分析和驗證。首先提出了最優控制問題,然后利用Q-學習算法設計了基于數據驅動的最優控制器,并重點分析了非策略Q-學習算法在不確定性離散系統的最優控制問題中是否有效。最后通過仿真實驗得出結論,在不確定環境下應該設計魯棒非策略Q-學習算法以保證系統的穩定性。
關鍵詞:最優控制;非策略Q-學習;離散系統;魯棒性
中圖分類號:TP181;TP13 ? ? ?文獻標識碼:A 文章編號:2096-4706(2020)12-0010-04
Abstract:The necessity of robust non-strategic Q-learning research for discrete systems is analyzed and verified. First,the optimal control problem is proposed,and then the optimal controller based on data driving is designed using Q-learning method,and the focus is on whether the non-strategic Q-learning algorithm is effective in the optimal control problem of uncertain discrete systems. Finally,it is concluded through simulation experiments that a robust non-strategic Q-learning algorithm should be designed in an uncertain environment to ensure the stability of the system.
Keywords:optimal control;non-strategic Q-learning;discrete systems;robustness
0 ?引 ?言
強化學習算法是一種通過與環境進行試錯交互尋找能夠帶來最大累積獎賞策略的學習方法[1]。目前強化學習的方法廣泛應用于控制領域中,以達到最優控制的效果。強化學習分為策略(On-policy)學習和非策略(Off-policy)學習。如果在學習過程中,動作選擇的行為策略和學習改進的目標策略一致,該方法就被稱為策略學習,否則被稱為非策略學習[2]。
Q-學習是強化學習算法的一種,又稱為動作相關啟發式動態規劃(ADHDP),是一種近似動態規劃(ADP)方案法,它結合了自適應批評理論[3,4]。Q-學習算法的優點之一是能夠在不了解環境的情況下評估效用和更新控制策略[2,5]。
筆者研究了一些用強化學習算法求解線性DT系統的線性二次調節問題,如貪婪HDP迭代算法[6]和非線性DT系統的迭代自適應動態規劃(ADP)[7],還有具有時滯的非線性系統啟發式動態規劃(HDP)[8]和線性系統的輸入和輸出數據的策略迭代(PI)和值迭代(VI)[9]算法。然而,上述文獻并沒有分析和驗證魯棒強化學習算法研究的必要性,理論上非策略Q-學習算法需要考慮系統的魯棒性,否則絕大多數控制器很難維持系統的穩定性。這是本文研究魯棒非策略Q-學習問題的動機。
1 ?最優控制問題闡述
以下是對線性二次調節問題的非策略Q-學習的闡述。
研究目標:尋找一種最優控制率,能夠使式(2)中性能指標xk+1越小,并保證式(1)中系統J能夠在不確定的環境下保持穩定。若不考慮不確定性,對于標準型式(3),可以參考現有文獻[10]來分析非策略Q-學習算法在不確定性離散系統的最優控制問題中是否有效。
2 ?非策略Q-學習算法設計
以下是對非策略Q-學習算法的設計。根據Q-函數與值函數之間的關系,基于非策略Q-函數的Bellman方程,得到一種非策略Q-函數學習算法。
然后實現非策略Q-學習算法1,經過30次迭代后算法收斂,得到最優Q-函數矩陣H*和最優控制器增益K*,結果同式(16)(17)。
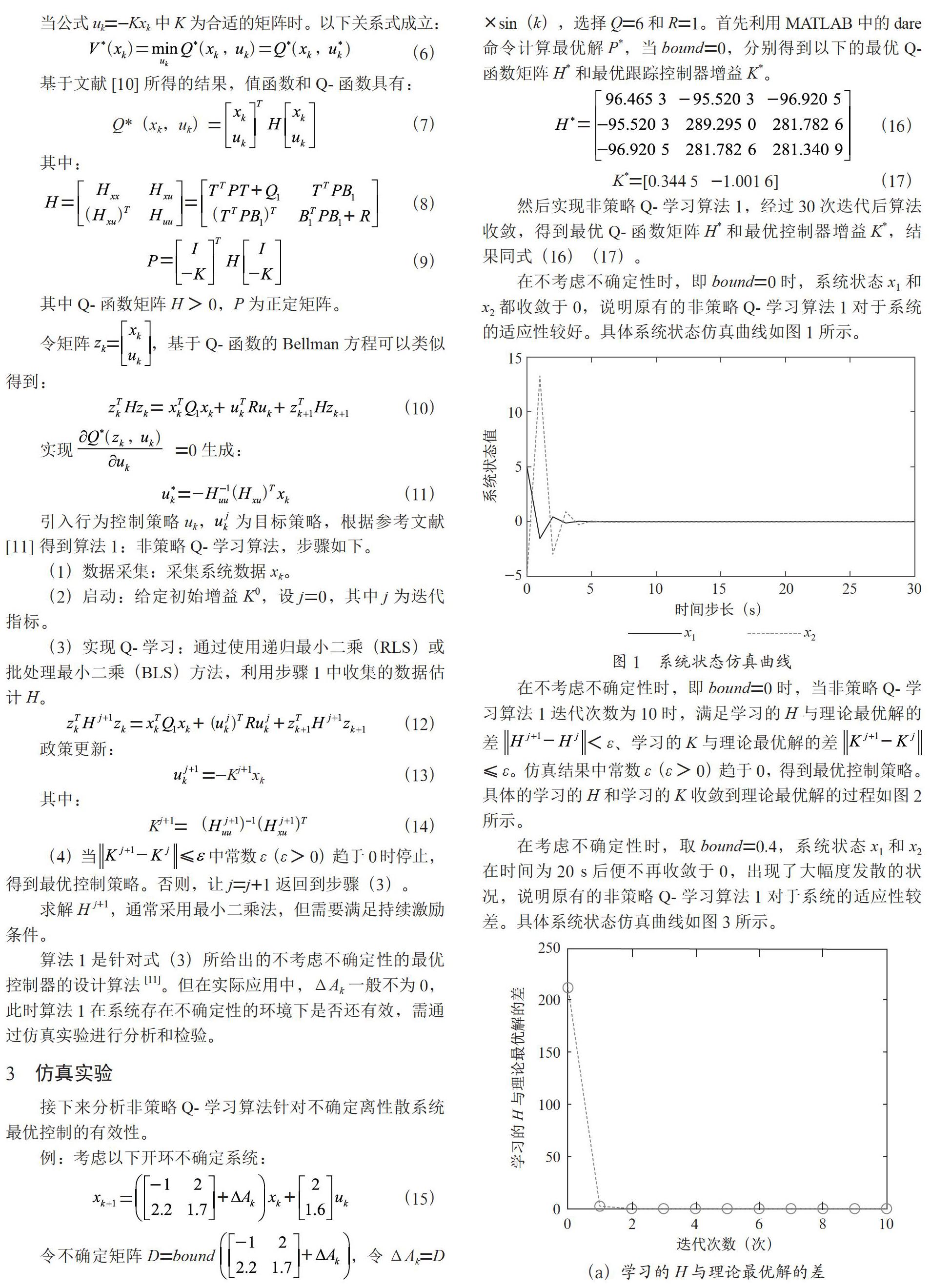
在不考慮不確定性時,即bound=0時,系統狀態x1和x2都收斂于0,說明原有的非策略Q-學習算法1對于系統的適應性較好。具體系統狀態仿真曲線如圖1所示。
在不考慮不確定性時,即bound=0時,當非策略Q-學習算法1迭代次數為10時,滿足學習的H與理論最優解的差 <ε、學習的K與理論最優解的差 ≤ε。仿真結果中常數ε(ε>0)趨于0,得到最優控制策略。具體的學習的H和學習的K收斂到理論最優解的過程如圖2所示。
在考慮不確定性時,取bound=0.4,系統狀態x1和x2在時間為20 s后便不再收斂于0,出現了大幅度發散的狀況,說明原有的非策略Q-學習算法1對于系統的適應性較差。具體系統狀態仿真曲線如圖3所示。
在考慮不確定性時,取bound=0.4,當非策略Q-學習算法1迭代次數為20時,學習的H與理論最優解的差 和學習的K與理論最優解的差 ?的結果不再收斂于0,得到的最優控制策略將不能夠使系統保持穩定狀態。具體的學習的H和學習的K收斂到理論最優解的過程如圖4所示。
分析得到:在bound≠0時,非策略Q-學習算法1考慮了系統的不確定性,并且隨著不確定性ΔAk的增加,系統狀態穩定性受到了一定程度的影響,可見算法1對不確定性ΔAk的容忍范圍是有限的;如果不確定性ΔAk過大,系統的穩定性將無法得到保障。
4 ?結 ?論
針對系統模型參數未知的離散系統,本文重點分析和驗證了魯棒非策略Q-算法研究的必要性,提出了最優控制問題,并且在非策略Q-學習算法設計過程中考慮了不確定性。文章通過仿真實驗得出結論,在研究不確定環境下的離散控制系統時,應該設計魯棒非策略Q-學習算法以保證系統的穩定性。
參考文獻:
[1] 劉全,傅啟明,龔聲蓉,等.最小狀態變元平均獎賞的強化學習方法 [J].通信學報,2011,32(1):66-71.
[2] KIUMARSI B,LEWIS F L,MODARES H,et al. Reinforcement Q -learning for optimal tracking control of linear discrete-time systems with unknown dynamics [J]. Automatica,2014,50(4):1167-1175.
[3] WATKINS C J C H. Learning from delayed rewards [D]. Cambridge:University of Cambridge,1989.
[4] MILLER W T,SUTTON R S,WERBOS P J. A Menu of Designs for Reinforcement Learning Over Time [J]. Neural networks for control,1995(3):67-95.
[5] AL-TAMIMI A,LEWIS F L,ABU-KHALAF M. Model-free Q -learning designs for linear discrete-time zero-sum games with application to H-infinity control [J]. Automatica,2006,43(3):473-481.
[6] ZHANG H G,WEI Q L,LUO Y H. A novel infinite-time optimal tracking control scheme for a class of discrete-time nonlinear systems via the greedy HDP iteration algorithm [J]. IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2008,38(4):937-942.
[7] WANG D,LIU D,WEI Q. Adaptive dynamic programming for finite-horizon optimal tracking control of a class of nonlinear systems [C]//中國自動化學會控制理論專業委員會.中國自動化學會控制理論專業委員會B卷.2011:2450-2455.
[8] ZHANG H G,SONG R Z,WEI Q L,et al. Optimal tracking control for a class of nonlinear discrete-time systems with time delays based on heuristic dynamic programming [J]. IEEE transactions on neural networks,2011,22(12):1851-1862.
[9] KIUMARSI B,LEWIS F L,NAGHIBI-SISTANI M,et al. Optimal Tracking Control of Unknown Discrete-Time Linear Systems Using Input-Output Measured Data [J]. IEEE transactions on cybernetics,2015,45(12):2770-2779.
[10] 李金娜,尹子軒.基于非策略Q-學習的網絡控制系統最優跟蹤控制 [J].控制與決策,2019,34(11):2343-2349.
[11] LI J N,YUAN D C,DING Z T. Optimal tracking control for discrete-time systems by model-free off-policy Q-learning approach [C]. 2017 11th Asian Control Conference(ASCC),2017:7-12.
作者簡介:劉秋麗(1997—),女,漢族,河南鄲城人,本科,研究方向:自動化;李金娜(1977—),女,漢族,山東單縣人,教授,碩士生導師,博士,研究方向:數據驅動控制、運行優化控制、強化學習、網絡控制。
猜你喜歡
校園英語·上旬(2016年10期)2016-11-16 18:34:24
校園英語·上旬(2016年10期)2016-11-16 18:09:12
讀寫算·素質教育論壇(2016年21期)2016-11-14 05:53:56
文理導航(2016年30期)2016-11-12 15:23:38
人間(2016年28期)2016-11-10 22:12:11
戲劇之家(2016年20期)2016-11-09 23:55:31
農業與技術(2016年15期)2016-11-09 17:45:14
人間(2016年26期)2016-11-03 18:25:32
啟迪與智慧·教育版(2016年8期)2016-10-20 16:00:16
啟迪與智慧·教育版(2016年8期)2016-10-20 15:31:51
