前沿經濟理論視野下的數據要素研究進展
2021-12-10 02:45:26榮健欣王大中
南方經濟 2021年11期
關鍵詞:消費者
榮健欣 王大中
一、引言
數據一般指以“0-1”二進制形式為數字技術搜集、存儲、處理、傳輸的信息。進入21世紀以來,消費互聯網及其催生的互聯網平臺高速發展,產業互聯網方興未艾,人工智能、大數據等新興數字產業蓬勃推進。數據的處理、傳輸成本快速降低,數據在制造業數字化轉型、電子商務、平臺經濟等領域中發揮的作用日趨顯著,成為產業經濟和宏觀經濟不可忽視的重要投入因素。就數據在當今國民經濟中發揮的重要角色,以及經濟主體(互聯網平臺、政府部門等)對數據搜集、處理的巨大投入來看,可以將數據視為一種新興生產要素。
2019年10月31日,中共十九屆中央委員會第四次全體會議通過《中共中央關于堅持和完善中國特色社會主義制度推進國家治理體系和治理能力現代化若干重大問題的決定》。文件提出,“健全勞動、資本、土地、知識、技術、管理、數據等生產要素由市場評價貢獻、按貢獻決定報酬的機制”。 2020年3月30日,中共中央、國務院發布《關于構建更加完善的要素市場化配置體制機制的意見》,明確提出要加快培育數據要素市場,為進一步發揮數據生產要素的作用指明了方向。黨和政府對數據生產要素的重視,充分表明數據對于進入高質量發展階段的中國經濟的重要意義。然而,當前數據要素市場化無論在概念定義、統計度量、價值評估和市場化機制設計等方面都存在一系列實踐問題,需要經濟學理論提供解決思路。首先,相對于土地、資本、勞動等傳統生產要素,數據作為一種生產要素具有一定的特殊性,例如非競爭性(non-rivalry)、規模報酬遞增、隱私負外部性等。對數據要素經濟價值和要素市場化的討論離不開對這些特性的分析;其次,數據要素的市場化過程牽涉到數據產權歸屬、數據交易形式、數據交易機制等諸多前沿議題,需要經濟學理論對數據要素化的機制設計和福利效應做出探討;最后,經濟學理論需要探討數據作為一種生產要素,如何直接貢獻于產業市場和宏觀經濟,并通過統計實證檢驗和測算數據要素的實際經濟貢獻。
數據要素的研究呼喚經濟理論的創新。本文旨在梳理總結前沿經濟理論文獻研究數據要素的主要進展。這里所稱的“前沿經濟理論”,主要涵蓋微觀經濟理論中的機制設計、合約理論、信息設計、行為經濟學、產業組織理論,以及宏觀經濟增長理論中的內生增長理論等領域。這些領域的理論突破為數據要素的福利效應評估、產權歸屬設定、交易機制設計等重要議題提供了研究工具。當前,對于數據要素研究已有一些優秀的中英文綜述(Pei,2020; Bergemann and Bonatti,2019;Carriere-Swallow and Haksar,2019;蔡躍洲、馬文君,2021; 徐翔等,2021;熊巧琴,2020),這些綜述系統梳理了數據要素研究的主要議題和重要文獻。但現有綜述由于種種原因,往往對相關數據要素議題的具體研究思路,以及數據要素與經濟學前沿理論的貼合點缺乏深入介紹。本文將在這些綜述文獻的基礎上,深入挖掘文獻對數據要素相關議題的建模思路,以及與相關經濟理論的結合點,從而為數據要素在中國的研究提供新思路。
本文內容組織如下:首先,從隱私負外部性、報酬特征這兩方面入手,探討數據要素相對于傳統生產要素的特性;其次,從數據要素的產權歸屬和交易機制兩方面探討數據要素市場化機制,特別是分四個場景探討經濟學理論中對于數據要素交易機制的研究思路;再次,列舉文獻探討數據要素在現實經濟中創造經濟價值的主要路徑,并介紹對數據要素經濟價值的重要實證研究成果;最后,從研究方法和中國問題兩個角度展望未來的數據要素研究。
二、數據要素特性
這一部分中,我們將討論數據要素的特性。現有文獻已經列舉了數據要素的眾多特性,例如規模報酬遞增、非競爭性、隱私負外部性、超越地理距離的即時傳輸性等。本文不再詳細列舉數據要素的一般特性(讀者可參考其他文獻,如徐翔等,2021),而將集中探討數據要素的隱私負外部性,以及報酬遞增/遞減問題。這兩大特性深度嵌入數據要素市場化的成本投入和產出收益過程,直接關聯數據要素市場化的福利效應,因此對于數據要素的現實政策具有重要意義。此外,隱私負外部性與報酬遞增/遞減問題牽涉到數據要素的定義和度量,并且和文獻所述的數據要素其他特性(例如非競爭性)息息相關。探討文獻對隱私負外部性和報酬遞增/遞減問題的處理,可以了解經濟理論對數據要素的一般處理方法。
(一)隱私負外部性
現實中,不同數據集的信息普遍存在相關性,一個消費者的個人數據可能透露和該消費者有關聯的其他消費者的信息。因此,任何消費者與企業“以隱私換補貼”的數據要素市場化交易都面臨數據的隱私負外部性問題。但是隱私負外部性的刻畫需要完善對數據、隱私本身的度量。這里將介紹幾篇文獻對于消費者個人數據和隱私負外部性的建模處理。
Ichihashi(2021b)研究了一個企業從消費者手中購買數據的模型。假設有n個消費者,企業從消費者手中購買數據以學習世界狀態X∈χ, 每個消費者對于世界狀態有一個共同的先驗信念分布(common prior)。一次試驗μ:χ→Δ(S) 能更新行為主體的信念,<μ>∈Δ(Δ(χ))代表由初始信念和試驗μ決定的后驗信念。如果<μ>是<μ′>的均值保持展開式(mean preserving spread),則稱μ比μ′更有信息含量,表記為μμ′。經濟體中數據配置表現為n個試驗μ=(μ1,…,μn):χ→Δ(SN)。集合S是信號實現的集合。
為刻畫數據隱私外部性,作者定義了數據的替代性和互補性。
數據配置μ是完全替代的,如果?i∈N,<μ>=<μ-i>。
數據配置μ是完全互補的,如果?i∈N,<μ-i>=<μ?>,μ?是無信息含量的試驗。
直覺上講,如果數據配置是完全替代的,則邊際的個人數據價值為0,此時廠商光從其他消費者的數據就能推斷這個消費者的信息。完全互補的數據配置則是一個消費者的數據的邊際價值相當于整個數據集,即缺失了任何一個消費者信息的數據對于企業來說都是無用的。Ichihashi(2021b)用統計試驗引致的后驗信念分布定義數據配置,并以聯合后驗信念分布受到單個消費者數據影響的程度定義隱私負外部性。這一路徑較為嚴謹但過于抽象。
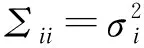
其中S表示包含所有用戶的個人數據Si的向量,pi是平臺對用戶的支付。消費者隱私偏好強度為vi,其總收益為:
即平臺總要更準確預測消費者類型,消費者總要避免被準確預測類型。由于存在數據隱私外部性,用戶i的總信息泄露為:
這是通過所有用戶的信息匯總后,對用戶i的類型預測的均方誤差(mean square error)的減少值。其中a={a1,…,an}代表所有用戶的數據分享決策,ai=1代表用戶i出讓數據。Sa代表aj=1,即選擇分享數據的所有用戶j的數據向量。在這一簡單的數據市場中,平臺決定對用戶的補償pi,用戶i決定是否出讓數據ai。作者還定義了“單調性”、“子模性”(submodulity)等概念來度量數據隱私外部性。
單調性:兩個行動組合a和a′滿足a≥a′, 則?i∈{1,…,n},Ji(a)≥Ji(a′)
經濟學含義為:分享信息的用戶集合增大后,信息泄露增大。
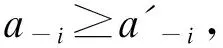
經濟學含義為:任何消費者個人透露信息所導致信息泄露的邊際增加隨著其他消費者透露信息量的增加而減少。
Acemoglu et al.(2021)側重使用統計指標(類型預測的均方誤差)度量消費者信息透露帶給其他用戶的隱私損失。優點在于度量方法較為客觀,缺陷在于隱私損失涉及消費者主觀信念,不一定和統計預測的均方誤差一致。
Choi et al.(2019)假定消費者使用一個壟斷在線平臺的服務必須同意出讓個人數據。消費者需要權衡出讓數據的隱私損失和在線平臺的服務。但同時,消費者出讓的個人數據也會透露關于用戶和非用戶(即不同意以出讓隱私為代價接受平臺服務的消費者)的信息,導致數據隱私外部性。具體來說,假設一個壟斷在線平臺提供內容服務,一單位連續統的消費者各自對平臺內容有隨機偏好u,u服從分布函數F。平臺可從用戶處通過征求同意搜集個人類型θ,θ服從分布函數G,每個消費者承受隱私凈損失為λ(θ,m),其中m代表平臺服務的消費者量。λ(θ,m)隨θ和m遞增,代表消費者類型越高,對隱私越敏感;且平臺擁有的用戶越多,對個體消費者的隱私侵犯越嚴重(數據隱私外部性)。數據除了對一般用戶造成隱私外部性損失,還會造成非用戶的隱私損失:對于每個θ類型消費者透露的數據,有α比例會產生非用戶的隱私損失。社會計劃者或者壟斷平臺選擇門檻類型θE和θN,類型在[0,θE]的消費者由于數據外部性而被動出讓隱私,類型在[0,θN]的消費者主動出售數據。即搜集的總數據為:
Choi et al.(2019)使用外生設定的函數來定義和度量隱私外部性和隱私損失。能較為靈活地適用于互聯網平臺服務換隱私的經濟場景。但可能存在函數形式設定的隨意性。
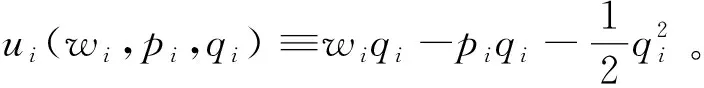
在上游數據市場,數據商在需求沖擊實現前從個體消費者手中購買關于需求信息的數據,并把個體數據加總或混淆后售予產品廠商。數據商可以對消費者有效承諾搜集個人信息的精度。具體來說,如果消費者i出售數據,數據商根據承諾能夠得到關于他支付意愿的一個私有信號:

其中aj代表消費者j是否出售數據的決策;數據商可以承諾+j的精度,即“混淆”原始數據以照顧消費者的隱私需求;數據商也可以調整αij這一參數以“加總”不同消費者的信息。同樣,數據商對下游產品廠商也能出售進一步加總和混淆加工后的原始數據。記數據商搜集消費者數據的政策wi→si為信息結構S:RN→ΔRN。
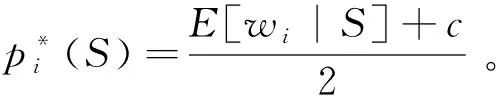
易知此時消費者的個人數據存在負外部性:即使一個消費者不透露自身數據,只要其他消費者透露了數據,則該消費者也要承擔個人隱私泄露的損失:Ui(?,S-i)-Ui(?)<0。
Bergemann et al.(2021a)的隱私負外部性度量聚焦于泄露隱私引發價格歧視對消費者福利的客觀傷害,是產業組織領域度量隱私負外部性的適當路徑。綜上所述,現有文獻對于隱私負外部性的處理直接關聯于所關心的具體場景和隱私的度量方式。采用純粹統計方法度量的隱私(例如Ichihashi(2021)的后驗信念分布函數的二階隨機占優性)較為客觀,但難以刻畫隱私泄露對消費者的主觀損失。在產業市場,可以通過客觀的價格歧視引致的消費者福利損失度量隱私負外部性。在其他領域,往往需要通過其他方式(例如問卷調查)度量數據要素的隱私負外部性。但文獻中也指出了“隱私悖論”(Privacy Paradox, 即問卷中表示更關心隱私的消費者現實中樂于分享數據,見Acquisti et al.(2016)以及Athey et al.(2017))的存在。因此,適用廣泛,客觀,同時符合消費者主觀偏好和實際行為的隱私負外部性度量仍需探索。
(二)報酬遞增抑或遞減?
傳統生產要素(例如資本、勞動)經常被納入Cobb-Douglas生產函數,以描述其規模報酬不變或邊際報酬遞減的特征。數據要素是否呈現邊際報酬遞減或規模報酬不變的特征?如果不是,其決定特征為何?這是文獻尚在爭論的問題。
1.數據要素的邊際報酬
Varian(2018)討論了人工智能行業的數據要素邊際報酬。他認為機器學習中的數據要素,和傳統生產要素一樣,呈現邊際報酬遞減。用直觀的圖像展示,Varian(2018)顯示機器學習隨著訓練圖片的增加,平均識別準確率的增速遞減。也有實證文獻檢驗了數據投入的邊際報酬。Bajari et al.(2020)使用亞馬遜周度零售價格數據檢驗數據量對零售價格預測系統的預測準確度的影響。作者發現數據跨度越長,系統價格預測越準確,盡管存在邊際收益遞減。同時,橫向數據規模越大(即同時期不同零售商的價格數據越多)不影響系統預測精度,即邊際收益降為零。Dosis and Sand-Zantman(2020)認為在標準的貝葉斯信息更新框架下,數據的邊際報酬遞減是成立的,原因是較早收到的信號比較晚收到的信號更能改變決策。
Posner and Weyl(2018)看法相反。他們認為,以機器學習為主要技術的人工智能與傳統統計學習技術有較大區別。機器學習能完成傳統統計學習難以實現的復雜功能,例如識別人臉、實現高水平圍棋對弈等。而這些復雜功能必須經由較大規模的數據投入才能實現。因此,機器學習的數據要素投入呈現階段性、波浪形的“邊際報酬遞增-邊際報酬遞減”形式。
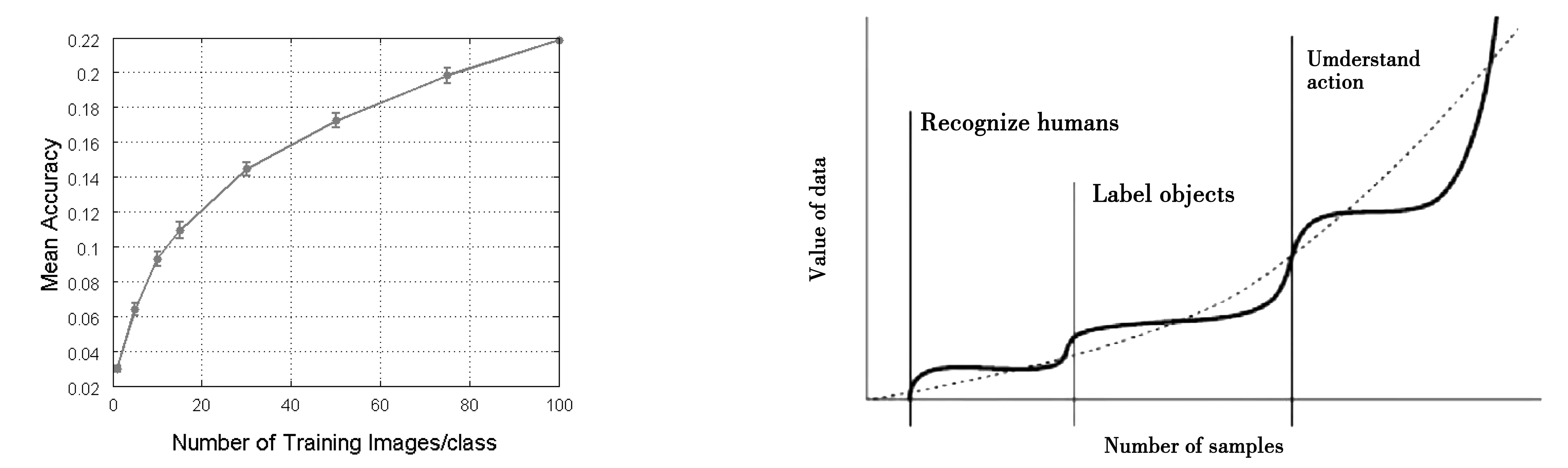
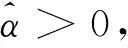
圖1 機器學習樣本量與平均準確度 圖片來源:Varian(2018)。圖2 機器學習樣本量與數據價值圖片來源:Posner and Weyl(2018)。
Varian(2018)和Posner and Weyl(2018)各自揭示了數據要素邊際報酬的一個側面。現實中,數據要素隨規模不同,可能在不同階段呈現邊際報酬遞增或邊際報酬遞減。因此,對數據要素邊際報酬的討論離不開微觀層面技術經濟特性的具體實證研究。
2.微觀層面的規模報酬遞增與網絡效應
微觀層面,要素的規模報酬指要素投入同比例變化引起的產出變化。眾多實證文獻指出數據要素可能存在規模報酬遞增性,導致現實中大型廠商相比小型廠商不成比例地受益于數據要素。Begenau et al.(2018)就發現金融業數據要素強化大小企業的分化。然而,微觀層面數據要素的規模報酬遞增性來源何處,如何研究?Varian(2018)提出了微觀層面數據要素規模報酬遞增的三種來源。
(1)供給側的固定成本效應。廠商為實現數據的處理、加工、分析,需要投入巨大的固定成本購買設備、開發軟件。而數據本身的搜集、復制是自動化的過程,可變成本較低。因此,數據要素投入所耗費的總成本中固定成本占比較高。由此,更大規模的數據要素投入可以分攤較大比例的固定成本,從而降低平均成本,呈現數據要素的規模報酬遞增性。Varian(2018)也指出,雖然軟件的開發成本很高,但維護更新成本也不可忽視。未來能自主學習的智能軟硬件,其可變成本的變化更需要關注。
(2)需求側的網絡效應。相當多的數據要素由互聯網平臺搜集。這些互聯網數字平臺的運營無可置疑呈現較強的網絡效應。包括直接網絡效應:對于微信等社交軟件,消費者天然選擇用戶已經較多的產品;以及間接網絡效應:對于操作系統等行業標準基礎設施,用戶較多、配套應用軟件較豐富的系統容易吸引更多用戶。直接和間接網絡效應的存在,使得擁有數據規模更大的互聯網平臺能夠通過吸引更多用戶來搜集更多的潛在數據。需要指出,這種“數據網絡效應”更多的是刻畫和解釋現實中互聯網產品市場結構的特殊現象,和數據要素本身的普遍特性無關。
(3)“干中學”與累積效應。Varian(2018)認為,處理大數據的經驗、技能本身比數據要素更稀缺。而且大數據的處理本身是信息科技的前沿,需要摸索經驗。因此對數據要素的處理呈現較強的“干中學”效應。隨著數據處理規模的增大,處理新增數據的成本投入相對降低,由此呈現規模報酬遞增效應。
現有文獻普遍認為數據要素存在微觀層面的規模報酬遞增,并能區分不同因素導致的規模報酬遞增。通過對具體企業和行業的進一步研究,有望揭示數據要素的規模報酬對于不同企業和行業的異質性。
3.宏觀層面數據要素的規模報酬遞增:非競爭性與隱私成本
在宏觀層面,數據要素的規模報酬可以分為總產出的規模報酬和凈價值的規模報酬,這兩方面與數據要素的非競爭性和隱私成本相關(1)內生經濟增長理論較早就從技術知識的多部門可復用性推導出研發活動的規模報酬遞增。例如Romer(1990)的研發模型就假設最終品部門和研發部門都將技術知識作為生產函數的投入,且一個部門使用技術知識不妨礙另一部門使用。。
(1)非競爭性
數據要素的非競爭性,來源于數據可以無成本地復制,因此一個使用者對數據的使用并不減少數據要素對其他使用者的供給。同一組數據可以同時被多個企業或個人使用,額外的使用者不會減少其他現存數據使用者的效用。從宏觀經濟層面來看,數據要素的非競爭性直接導致數據要素的規模報酬遞增。
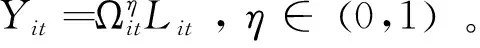
現有文獻中通過刻畫數據要素的非競爭性,容易在宏觀經濟增長模型中得到數據要素的宏觀規模報酬遞增性。需要指出,包含數據要素的宏觀增長模型都需要設定數據要素的來源,Jones and Tonetti(2020)假定數據要素是社會產出的副產品,Veldkamp and Chung(2019)假定數據要素是消費的副產品。不同的假定都能將數據要素與宏觀加總變量關聯,但可能導致刻畫的數據要素規模報酬遞增的程度不一樣。
(2)隱私成本
Veldkamp and Chung(2019)、Jones and Tonetti(2020)、Dosis and Sand-Zantman(2020)等多篇文獻都將數據要素的隱私成本設定為數據使用量的二次項形式。這是一種在現實消費者隱私損失難以度量的情況下,沿用傳統文獻標準設定的做法。但二次項的凸性成本函數引出了關于數據要素的凈價值是否存在規模報酬遞增的疑問。例如在Dosis and Sand-Zantman(2020)設定下,給定線性產出和二次項隱私成本,數據要素的凈價值是對數據量e嚴格凹的,因此數據要素凈價值呈現規模報酬遞減。對于那些數據產出呈現規模報酬遞增的設定,如果結合二次項隱私成本,則更難考察數據凈價值的規模報酬。當然,研究中也完全可以回避這一問題,只考察數據要素產出的規模報酬遞增。
綜上所述,數據要素的宏觀規模報酬遞增性主要來源于數據要素的非競爭性,但凸性隱私成本的存在可能導致數據要素的凈產出不存在規模報酬遞增。因此,未來的研究應更關注于隱私損失的刻畫度量,以及數據要素宏觀規模報酬遞增效應的實證度量。
三、數據要素市場化
傳統生產要素,如資本、勞動,其產權歸屬和市場交易機制較為直觀、成熟。而數據要素由于存在非競爭性等技術經濟特性,以及法律規定的不明確,導致其產權歸屬不確定。疊加數據要素交易場景的復雜性也導致學者難以探索數據要素市場化的一般機制。這一部分,我們將從數據產權歸屬和數據要素交易兩個層面,討論數據要素市場化問題。
(一)數據產權歸屬
需要指出,數據所有權這一概念在理論文獻中存在爭議。事實上,如Varian(2018)指出,數據與石油不同,由于數據有非競爭性,同樣的數據可以為多方訪問。“數據準入”(data access)比“數據所有權”(data ownership)更適合作為分析的基礎。因此數據要素產權的定義,應包含數據搜集(或有權要求不被搜集)、訪問、使用、交易等方面的權利束。在配置數據產權時,需要考慮(1)數據有隱私負外部性,賦予用戶數據產權,不一定能實現有效的數據交易;(2)數據有非競爭性,用戶可以將數據出售給多家廠商;(3)數據交易存在合約的不完全性和不可承諾性,用戶有時難以相信廠商會合理使用數據;(4)個人數據牽涉到個人隱私,同時企業搜集處理數據也要付出成本,合理的數據產權歸屬應該平衡到所有這些方面。
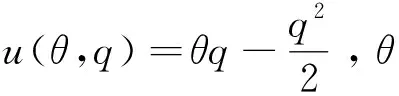
當數據處理和貨幣化變現是可締約(contractible)時,按照科斯定理,數據產權歸屬不影響交易結果。廠商需要設定最優合約,給消費者提供一份包含用戶給廠商支付t(θ), 服務使用量q(θ)和數據搜集量e(θ)的邀約{t(·),q(·),e(·)},并應用顯示原理(revelation principle)誘使消費者透露真實類型θ。可以證明,最優合約中,廠商限制對高類型用戶的數據搜集,換取這些用戶消費更多服務;而廠商對低類型用戶的數據搜集比例較高,原因是這些用戶本身的服務消費較少,隱私總成本也較低。廠商無需以數據搜集換取高消費。
當數據處理和貨幣化是不可締約(non-contractible)時,用戶和廠商都無法在合約中承諾搜集多少數據(e)和加工多少數據。作者分別考察廠商和用戶擁有數據產權的后果。由于數據處理不可締約,廠商仍能就用戶服務使用量q(θ)和支付t(θ)締約,但無法承諾數據搜集量e(θ)。當廠商擁有數據產權時,廠商一定會盡其所能搜集數據使得e=q。作者證明此時廠商對于高類型用戶的數據搜集相對可締約情形是過度的,原因是高類型用戶預計到自己消費服務后生成的數據會被完全搜集,因此會降低自身的服務消費量。
當用戶擁有數據產權時,作者假設此時用戶在使用服務,產生數據后,能控制δ比例的原始數據,可以決策將其變現。其余的1-δ比例的數據必須由廠商加工后才能變現,但由于無法在合約中進行約定數據加工量及其補償,此時不存在事前合約激勵廠商加工數據。另外,廠商和用戶仍能就服務使用量q(θ)和支付t(θ)締約,但數據搜集程度e(θ)無法締約而是由消費者單方面決定。為了權衡數據要素變現收入和隱私損失,低類型消費者會選擇最大程度的數據搜集e=q, 高類型消費者會選擇只變現部分數據即e 作者討論了不同參數下的最優數據產權配置。將產權配置給廠商有可能導致高類型用戶擔心隱私受損而不愿消費服務,將產權配置給用戶可能導致廠商由于無法獲得補償而不愿加工數據。因此最優的產權配置需要權衡這兩種效應。 Jones and Tonetti(2020)從宏觀經濟增長的視角考察了數據要素不同產權配置的影響。在這篇文章中,數據要素產權配置的核心權衡來源于消費者單期效用: 現有文獻分別從微觀、宏觀兩個層面探討了數據要素產權歸屬的福利效應,覆蓋了數據處理的不可締約性、數據要素的非競爭性和隱私成本等,為數據要素的產權歸屬研究奠定了良好的基礎。未來的文獻有望在上述文獻基礎上,通過更細致的實證研究設計數據要素更細化的權利束安排。 數據要素交易深度嵌入不同行業數字化應用的具體場景,交易主體眾多、交易對象和方式多樣,因此對于數據要素交易的研究必須覆蓋不同的交易場景。這一部分中,我們將依據微觀經濟理論文獻,從不同的交易場景視角,探討數據要素的交易機制。需要指出,雖然不少文獻中明確了“信息”和“數據”的區別,指出數據是信息的載體,而數據要素的經濟價值通過信息來實現(Jones and Tonetti, 2020)。但任何數據要素交易機制的設定,都必須涉及數據攜帶的信息價值實現的微觀機理。因此,下文中對于數據要素交易機制的討論可能涉及較為微觀的信息設計問題。 1.雙邊交易機制設計 Dirk Bergemann應用微觀經濟理論中的信息設計、機制設計的思路和方法,研究了通過存在數據中間商的數據要素交易機制。這些雙邊數據要素交易機制有以下特征:(1)數據的作用在于提供信息,幫助數據買家與消費者更好匹配;(2)數據中間商可以通過提供事后信息、設定信息結構、收購并加工數據、提供事中信念更新機會等方式,交付數據。 作者使用機制設計方法,將數據商的試驗菜單設計問題轉化為一個說真話機制設計問題。最后得出賣家收益最大化的試驗菜單:將事前信息較少的賣家視為高類型,事前信息較多的賣家視為低類型。數據賣家將給高類型完全信息的試驗,給低類型部分信息的試驗。這一試驗以較小的概率告知買家其身處事前認為概率較低的狀態,以較大的概率生成一個有噪音的信號。這樣,低類型買家愿意出錢買數據,原因是這一數據交易以正概率改變買家的信念從而改進其收益。在整個機制的設定中,數據商需要在保障買家說真話的前提下,實現社會效率和信息租抽取盡可能兼得。 Bergemann et al.(2018)將數據交易深度嵌入到方興未艾的信息設計(information design)文獻,通過假定數據為買家提供有用的信息結構,以及將買家的信息結構偏好轉化為可加總的效用函數,從而應用標準的機制設計方法得到數據賣家的最優信息匹配。然而,由于現實中的數據要素交易往往是打包的數據買賣,鮮少精細的信息結構匹配,Bergemann et al.(2018)這一貼合主流理論的模型難以直接應用于眾多的現實數據要素交易場景。而Bergemann and Bonatti(2015)和Bergemann et al.(2021a,2021b)則為信息設計方法找到了較為符合現實的數據交易應用經濟環境。 Bergemann and Bonatti(2015)考察數據商擁有關于消費者個人信息的數據(即所謂Cookie),并可以將查詢消費者個人信息的機會售予廣告主(advertiser)。具體來說,一單位連續統的消費者和廣告主產生一個匹配價值:ν:[0,1]×[0,1]→V,廣告主從消費者處得到的收益為:π(ν,q)≡νq-c·m(q),q代表消費者對廣告商廣告的注意程度,m(q)代表廣告主為得到消費者注意而花費的廣告成本。在初始狀態,廣告主除了一個共同初始信念(common prior)之外沒有關于匹配價值ν(i,j)的額外信息,而數據商可以提供關于每一對消費者-廣告商匹配價值的信息。因此廣告主可以從數據商處購買與自己的匹配價值在任意范圍內的消費者的個人身份信息。假設數據商關于單個消費者的身份信息售價統一為p,并且假設廣告主對自己購買身份信息的消費者集合設定個性化的廣告方案(即設定不同的q),而對自己沒有購買信息的消費者集合設置統一的廣告方案(即設定統一的q)。由此,作者考察廣告主對消費者數據的需求量,以及數據商的最優數據定價。廣告主購買消費者數據,需要權衡更多消費者數據帶來的潛在匹配收益,以及增加的成本(包括數據購買成本和廣告匹配成本)。對于數據買家(廣告主)來說,高價值消費者的個人數據和廣告投入是戰略互補品,低價值消費者的個人數據和廣告投入是戰略互替品。數據商也根據廣告主的需求設定最優壟斷價格。作者成功地將經典微觀經濟理論中的壟斷定價理論靈活應用于個人身份信息相關數據交易這一常見的數據要素化市場化場景。 Bergemann et al.(2021a)討論了一個數據商從消費者手中購買數據,然后銷售給廠商,幫助廠商調整產品質量和價格的經濟場景。作者引入了個人數據的社會維度:單個消費者的數據能幫助預測其他消費者的行為,由此產生的數據外部性能降低數據商購買數據的成本。Bergemann et al.(2021a)中的數據商扮演了數據混淆、加工、轉售的角色,并且利用消費者的隱私負外部性獲利。 具體設定作者已在二(一)部分介紹。這里只需介紹文中的數據商角色和數據交易策略。 在上游數據市場,數據商事前(需求沖擊實現前)從個體消費者手中購買關于需求信息的數據,并把個體數據加總或混淆后售予產品廠商。數據商可以對消費者有效承諾搜集個人信息的精度。具體來說,如果消費者i出售數據,數據商根據承諾能夠得到關于他支付意愿wj的一個私有信號: 其中aj代表消費者j是否出售數據的決策;數據商可以承諾+j的精度,即“混淆”原始數據以照顧消費者的隱私需求;數據商也可以調整αij這一參數以“加總”不同消費者的信息。同樣,數據商對下游產品廠商也能出售進一步加總和混淆加工后的原始數據。記數據商搜集消費者數據的政策wi→si為入口(inflow)信息結構S:RN→ΔRN,數據商將信號si再次加工后傳給下游產品廠商信號ti為出口(outflow)信息結構T:RN→ΔRN。 綜上所述,Dirk Bergemann的一系列研究成功應用了機制設計、信息設計、產業組織等領域的前沿理論,探索數據商的市場設計問題。其研究既涵蓋關于數據交易的一般理論建模,也有對消費互聯網平臺這一數據要素重要應用場景中多種數據交易方式的市場設計。是對于數據要素交易機制綜合了理論與實際的優秀應用微觀理論研究。未來的實證研究可以基于這一系列研究進行拓展。 2. 市場結構與數據交易 現實中,數據要素的需求方主要是產業市場的企業。而數據要素交易將會透過市場結構的差異影響產業市場競爭的結果。機制設計/信息設計方法較為適用于一個數據商對多個數據需求方的情形。而無論數據要素供給端(數據商)存在競爭,還是需求端(產業市場廠商)存在產業競爭,都會使問題復雜化。一系列文獻考察了數據要素交易機制與產業市場結構的關系。 Bounie et al.(2021)建構基于經典Hotelling模型的產業競爭模型,考察一個數據商可以將消費者需求信息分段售予兩個競爭企業。通過控制數據的質量,數據商可以調控買家企業的競爭強度。數據買家根據獲得的消費者信息,識別最有利可圖的消費者身份,并據此定價。具體來說,一單位連續統的消費者均勻分布在線段[0,1]上,兩個廠商彼此競爭,位于線段兩段。任意位置的消費者最多消費1單位物品,獲取效用V,并付出單位交通成本t。位于位置x的消費者從廠商1購物的效用為V-tx-p1。 廠商知道消費者均勻分布,但不知道具體位置(即消費者身份)因此無法實現價格歧視。廠商可以付出成本w購買數據,數據商提供的信息結構是把線段劃分為n個任意大小的線段,廠商擁有這些數據后,可以針對特定線段的消費者設定不同價格實現價格歧視。廠商也知道競爭對手獲得的信息結構及由此采取的策略。更精細的劃分會導致(1)廠商更精細的價格歧視和更高的消費者剩余攫取;(2)廠商價格歧視策略導致低價格段的降價競爭加劇。數據商的最優數據出售策略是出售最有利可圖的消費者信息,并將低價值的消費者信息保留不售,從而在獲取對最有價值的消費者抽租的同時盡可能削減廠商競爭導致的損耗。最終均衡時,數據商只對一家廠商出售數據。 綜上所述,Bimpikis et al.(2019)從市場環境不確定性角度,Bounie et al.(2021)從價格歧視角度,都刻畫了數據要素的價值及存在產業市場競爭時,單個廠商效率和整個市場競爭的背離,以及對應的數據商抽租和效率的權衡。兩者都顯示,下游產業市場的競爭為數據要素交易的需求端增加了額外的復雜性。數據商需要考量下游產業市場競爭對數據要素經濟價值的影響。 作者發現上下游企業的競爭不一定能提高廠商對消費者的補償。原因是數據存在非競爭性(non-rivalry):如果多個上游數據商同時以相同價格向消費者求購數據,消費者可以將一份數據出售給多個廠商,導致上游數據供應過量,下游市場數據價格降低。預計到這一點,數據商不會以有競爭力的價格向消費者購買數據。最終形成的均衡特點是:(1)不同數據商只會采購互斥的數據集合,不會采購同一數據,導致下游廠商面臨的加總數據集合與壟斷數據商一致;(2)數據商在數據采購市場表現為壟斷買家:給每個消費者的對價僅可補償下游廠商使用數據給消費者帶來的損失。 3. 消費者數據出售與數據市場有效性 現實中,數據要素交易除了有企業間的交易,還普遍存在企業用現金補貼或服務直接換取消費者個人數據的現象。這種“隱私換補貼”或“隱私換服務”的消費者-企業直接數據要素交易能否實現有效市場配置,是文獻關心的內容。由于本文二(一)部分關于隱私負外部性的討論已經覆蓋了本部分的主要文獻,這里將不再重復之前涉及文獻的具體設定,而是聚焦市場均衡的福利效應。 Ichihashi(2021b)研究了一個企業從消費者手中購買數據的模型,在較為抽象和一般的層次上,結合信息設計和產業組織理論探討了消費者出讓數據交易的社會福利。假設消費者的數據出售行為會透露其他消費者的信息(數據的隱私外部性)、作者討論了廠商如何利用數據外部性來降低數據采購的成本。具體設定已在二(一)部分中介紹。Ichihashi(2021b)將消費者數據出售刻畫為廠商選擇價格集合p=(p1,…,pn)并公布,其中pi是對消費者i的支付,然后所有消費者決定是否出售數據的時序。廠商的數據由出售了數據的消費者的數據(即統計試驗)μi決定。 作者證明,當廠商對信息掌握越多對消費者有害,即μμ′意味著消費者效用ui(μ)≤ui(μ′)≤0時,此時完全替代的數據配置會最小化消費者福利,最大化企業利潤,并導致數據售價為0。直覺是一個消費者透露個人信息會造成對其他消費者的損失,廠商可以利用這一外部性壓低消費者對個人數據的要價。由此類推,而給定一些條件,完全互補的數據配置最大化消費者福利,最小化企業利潤。當數據搜集對消費者有利,即μμ′意味著消費者效用ui(μ)≥ui(μ′)≥0,此時完全替代的數據配置會最大化消費者福利,最小化企業利潤。而給定一些條件,完全互補的數據配置最小化消費者福利,最大化企業利潤。 Acemoglu et al.(2021)設定平臺與消費者之間的數據交易。作者假定消費者i如果出售數據,其效用為: ui(ai,a-i,p)=pi-viJi(ai=1,a-i) 其中pi為平臺對消費者i的補償,vi是消費者i的隱私偏好,Ji為以消費者i類型預測均方誤差度量的信息泄露函數,不僅受到消費者i自身數據出售決策(ai=1)的影響,還受到其他消費者數據出售決策a-i的影響。作者發現平臺與消費者的數據交易中,數據隱私外部性導致了過多的數據分享和過低的數據價值。作者證明(定理3),如果高類型(更重視隱私)的用戶類型與其他用戶類型無關聯,則最終均衡是有效的。原因是高類型用戶不會出售個人數據,而低類型(不重視自己隱私)的用戶不管怎樣都會出售個人數據,但他們的決策不影響高類型用戶。作者還給出均衡時社會剩余為負的充分條件,滿足這一條件時,數據市場只給社會帶來凈損失,完全關閉數據市場能改善社會福利。Acemoglu et al.(2021)的貢獻在于給出隱私損失和隱私負外部性的客觀度量,并成功引入了用戶對隱私偏好的異質性。 Choi et al.(2019)假定消費者使用一個壟斷在線平臺的服務必須同意出讓個人數據。消費者需要權衡出讓數據的隱私損失和在線平臺的服務。但同時,消費者出讓的個人數據也會透露關于用戶和非用戶(即不同意以出讓隱私為代價接受平臺服務的消費者)的信息。具體設定見二(一)。通過考察社會最優和壟斷定價時的門檻值u(即平臺只服務對平臺內容偏好超過u的消費者),作者可以檢驗數據要素和數據外部性對社會福利的影響。作者發現在一個沒有數據搜集的簡單壟斷定價經濟環境里,壟斷平臺服務的消費者數量相對于社會最優不足,而在有數據搜集和數據外部性的條件下,壟斷平臺服務的消費者和搜集的數據超過社會有效水平。Choi et al.(2019)的特點是使用精巧的經濟環境設定,應用標準的壟斷定價和機制設計方法,探討在線平臺“服務換隱私”這一較為符合現實的數據要素交易場景。 上述文獻從不同角度探討了消費者作為交易主體直接與廠商或互聯網平臺交易數據的福利效應。通過納入隱私負外部性,這些文獻都顯示消費者與廠商的數據交易可能無法實現社會最優。這一結論具有重要的政策含義。 Fainmesser et al.(2019)的特點在于:(1)假定消費者隱私損失是客觀的數據被竊取量,避開對用戶主觀隱私偏好的建模;(2)假設隱私損失來源于外界攻擊,平臺與用戶利益本質一致,從而描述現實中數據存儲和數據保護兩類不同的策略;(3)根據網絡效應區分數字平臺的不同商業模式,梳理其數據隱私保護政策的差異。 綜上所述,現有文獻涵蓋了消費者直接參與數據要素交易時的各種場景和各種設定,例如外部數據竊取、隱私負外部性、數字平臺網絡效應等。現有文獻能有效解釋部分互聯網平臺的隱私保護策略差異,并能定性評估消費者數據要素交易的福利效應。應用計量經濟學方法對部分結論進行檢驗,并為更細致的數據隱私規制政策提供支撐,是未來研究可行的方向。 4.廠商數據交換與產品市場競爭 現實生活中,除了通過從數據商處購買數據,或者直接從消費者處搜集數據,廠商還熱衷互相分享數據。Elsaify and Hasan (2021)搜集到包含1285家廠商的1600多個數據交易/交換數據。作者發現17%左右的廠商參與數據市場,80%左右被交易的數據為消費者數據,50%以上的數據交易是以廠商間數據互換而非直接交易的形式進行的。作者還發現市值最高、處理數據能力越強的大廠商越容易參與數據買賣。同時,多數數據交易發生在同行業廠商間。 同行業的廠商何時有交易數據的動機?產業市場競爭又如何影響同行業廠商分享數據的激勵?Raith(1996)詳盡探討了同行業寡頭競爭廠商分享數據的問題。 自然狀態為τ=(τ1,…,τn)′,τi可以代表外生參數(例如企業邊際成本或線性需求函數截距項)與均值的偏差。τi均值為0,方差為ts, 協方差為tn∈[0,ts]。τi進入廠商利潤函數但廠商i并不知道其實現值(只知道分布)。在設定產量或價格前,企業接受到一個有噪音的關于τi的信號yi≡τi+ηi,ηi均值為0, 方差為uii, 協方差為un。作者考察了廠商間狀態的關聯度: (1)共同價值(Common Value):tn=ts=t。 此時所有企業面臨的自然狀態一致。 (2)獨立私有價值(Independent and Private Value):tn=un=0。 此時不同廠商之間的自然狀態不存在關聯,且彼此收到的信號也不存在關聯。 (3)完美信號的私有價值(Private Value and Perfect Signals):uii=un=0。此時不同廠商收到的信號不存在關聯, 且能完美反映自然狀態。 注意,在(2)、(3)兩種情形下,廠商間分享信息無助于各自更好了解面臨的市場狀況(即自然狀態),但可能影響廠商彼此策略的關聯度。 企業間分享信息有兩個效應:一方面每個廠商能更好了解市場狀況,另一方面廠商間信息的同質性會影響競爭策略的關聯性。作者證明,讓對手更好了解關于他們自己利潤函數的信息能增進策略關聯,策略關聯對廠商自身利潤的影響取決于廠商策略是戰略替代(例如古諾博弈)還是戰略互補(伯特蘭德博弈);而讓對手更好了解廠商自身的利潤函數的信息總能增進廠商自身的利潤。 Raith(1996)詳盡討論了產業市場上廠商彼此交換數據的權衡與激勵。然而,需要指出,由于年代較早,Raith(1996)的研究集中于廠商交換信息的激勵,較少討論在大數據、人工智能技術發達的今天,廠商通過共同匯集數據,發揮數據要素的非競爭性和規模報酬遞增性,實現行業整體數字化升級的激勵。當然,廠商的數據交易必然蘊含信息交換。本文作者參與廣東省各地市企業數字化轉型調研也發現多數企業仍然擔心向其他企業分享數據可能泄露機密。Raith(1996)的研究結論仍然成立。當然,未來的研究可以更精細地區分企業交易數據要素的多重效應:提升行業總體產出、改變產業市場競爭策略、泄露自身部分信息;并對不同的產業市場開展更細致的產業研究。 之前探討了數據要素的主要特性和市場化機制。本部分將從更微觀的視角,梳理文獻中提及的,數據作為一種生產要素在現實經濟中發揮的作用。我們將從微觀產業市場、金融市場、宏觀經濟增長等幾個角度來介紹文獻中對于數據要素經濟價值的理論探討和建模思路,并給出根據GDPR等實際政策評估的實證結果。 1. 產品市場的產品設計 在消費品市場上,數據的作用使企業能更好地設計產品,滿足消費者的需求,從而獲取更大的消費者剩余。現有文獻通常外生假定(1)數據要素有助于降低成本或提升質量;(2)數據要素來源于需求量或生產過程;來體現數據要素的特殊性。同時,引入數據要素也為探討數字經濟的產業市場結構提供了新視野。 Corniere and Taylor(2020)與Hagiu and Wright(2020)一樣,同樣對數據要素的價值施加外生假定。作者假設有n家企業,每家企業i選擇一個消費者效用水平ui,而消費者I從廠商i獲取的實際效用為uiI=ui+iI。廠商產品的需求函數為Di(u),滿足和即廠商設定的消費者效用水平越高,廠商銷量越高;而競爭對手設定消費者效用水平越高,廠商銷量越低。假設廠商從每個消費者上獲取的收益為ri(ui,δi),其中δi代表廠商獲取的消費者數據的質量。即數據要素通過改善同等質量的廠商產品與消費者的匹配度,進而提升廠商收益。通過檢驗數據質量δi對企業效用設定水平ui的影響,可以刻畫數據要素是否促進產品市場的競爭。Corniere and Taylor(2020)的這一抽象框架可以應用于個性化產品定制、定向廣告、價格歧視等數據要素價值實現的具體場景。 上面兩篇文獻都是從數據要素增進廠商產品與消費者的精準匹配這一角度設定數據要素的經濟價值。而Prüfer and Schottmüller(2017)則強調了數據要素通過增進廠商對消費者未來需求的精準預測,從而降低創新成本,改善創新效能。具體來說,消費者根據兩個寡頭企業的產品質量差異Δ=q1-q2來選擇購買的產品,企業能用獲取的消費者信息改進產品,而企業獲取的消費者信息與產品需求量Di成正比。每一期,企業選擇創新幅度xi,t=qi,t-qi,t-1。假設企業創新成本c(x,Di)隨數據量即需求量下降。因此企業產出呈現間接網絡效應,產業市場可能呈現趨向完全壟斷的多米諾趨勢。 2. 金融市場的資產配置 3. AI訓練 隨著AI(人工智能)行業的發展,數據要素通過強化計算機統計學習,直接提升人工智能技術水平和輔助決策能力的功能受到了關注。Baraja et al.(2020)考察了AI行業中的數據要素價值。人工智能行業中,通過大數據訓練模型能改善AI模型的精度,從而提升AI軟件的性能。作者使用中國數據驗證了這一假說。作者特別考察了中國人臉識別AI系統公司與政府簽訂的采購合約,與政府簽約開發人臉識別系統的AI企業,有機會接觸到政府擁有的人臉識別原始數據。而這些數據能幫助企業提升AI軟件開發水平,而企業軟件創新水平的提升,不僅有助于企業更好完成政府合約,還能幫助企業提升民用軟件的水平。使用三重差分計量方法,作者檢驗發現獲取“數據密集”(data-rich)政府合約的企業,相對于獲得“數據貧乏”(data-scarce)合約的企業,在獲得合約的三年后,無論是開發的面向政府的AI產品還是面向商業用途的AI產品都顯著更多。顯示了數據要素在AI行業的特殊應用價值。 4. 經濟增長 上面討論了不同行業中的數據生產要素的微觀經濟價值。如果將數據要素抽象為一種新型生產要素,可以通過經典的經濟增長模型討論數據要素的經濟價值。 眾多文獻已經從理論層面闡述了數據價值產生經濟價值的路徑和領域。已有文獻也應用實證方法評估數據要素的經濟價值。 2018年,歐盟實施一般數據保護條例(GDPR),強化了對互聯網平臺搜集個人信息的限制,從而限制了數據要素的市場化。對于歐盟GDPR的研究有助于評估數據要素的實際經濟價值。Aridor et al.(2020)研究了歐盟一般數據保護條例(GDPR)的經濟效應。GDPR限制了互聯網平臺接觸、使用、共享包含個人信息的數據。作者使用一個在線旅行平臺的數據,采用雙重差分法檢驗了GDPR的經濟效應。發現GDPR實施后,由于允許消費者選擇不提供個人信息,在線旅行平臺的消費者數量減少了12.5%。Jia et al.(2021)也發現,GDPR降低了歐洲相對于美國互聯網行業的融資水平。Johnson et al.(2021)則發現GDPR實施后,網站間數據分享減少,同時為網站提供服務的技術服務商市場集中度增大。 Bajari et al.(2020)使用周度零售價格數據檢驗數據規模對于亞馬遜平臺的零售價格預測系統的預測準確度的影響。作者發現數據跨度越長,系統價格預測越準確,盡管存在邊際收益遞減。同時,橫向數據規模越大(即同時期不同零售商的價格數據越多)不影響系統預測精度。作者也確實發現亞馬遜價格預測系統隨時間不斷改進預測精度,體現了數據要素的持續積累能力。 Hughes-Cromwick and Coronado(2019)實證檢驗了美國政府數據對企業的價值,通過搜集政府報告和對企業調查的數據,作者估算了美國政府數據對部分行業(汽車、能源、金融服務)企業的價值,并匯總了一系列研究對美國政府公開數據的行業價值的估算。作者總結說,隨著信息技術的發展,政府數據對私營部門的價值越來越高。盡管公司部門也在積累自身數據,但只有把自身數據和公開的綜合的政府數據結合,才能提供數據應用的關鍵場景,從而獲取最大利益。 其中λit代表數據加工的勞動投入,ADM代表數據經理的生產率。通過求解企業的最優動態選擇問題,作者可以將企業的最優數據要素存量寫成關于企業薪資、勞動力和數據加工勞動投入的函數。在實證部分,應用投資管理行業企業數據,作者發現知識工作中勞動收入比例從44%下降到27%,體現了數據要素在該部門生產函數中的作用提升。 綜上所述,現有文獻或基于現實政策評估(GDPR),或基于微觀數據統計預測及宏觀數據擬合,檢驗了數據要素的經濟價值,總體上確認了數據要素在產業市場中的作用趨向顯著。未來的實證研究可以基于理論模型研究的成果,應用結構式計量的方法進一步檢驗數據要素的經濟價值。 對數據要素市場化的研究,離不開對微觀經濟學前沿理論的跟蹤。本部分將介紹三篇文獻,分別依托信息設計理論、行為經濟學理論和機制設計理論的前沿發展,拓展了數據要素的研究視野。 1.信息設計 Dirk Bergemann等學者長期深耕信息設計理論在數據要素市場化方面的應用。而Ichihashi(2020)則應用信息設計領域方興未艾的貝葉斯勸說(Bayesian Persuasion)方法,考察了消費者對廠商的數據透露(disclosure)策略。該論文的核心權衡(trade-off)是消費者透露信息后能獲得廠商更準確的產品推薦,但也會導致廠商有機會實施價格歧視。 作者假設存在一個生產K種產品的壟斷廠商,一個有單位需求的消費。消費者對產品k的估價uk是服從獨立同分布的隨機變量,消費者效用為uk-p。 消費者起初不知道每種產品價值uk的實現值。消費者先選擇一個信息透露策略φ:VK→Δ(M), 這一策略將u的實現值轉換為對應的信號m的分布。作者用貝葉斯勸說(Bayesian Persuasion et al., 2011)設定消費者的信息透露。 例如廠商出售兩種產品(K=2)的情形,δ∈[1/2,1]為透露水平,當uk=max{u1,u2}時以δ概率發送信號k∈{1,2}。 博弈初始,自然(nature)決定u的實現值,并根據消費者信息透露規則決定信號m~φ(·|u)。 在非歧視定價規則下,廠商先定價,在觀測到消費者的信息透露策略φ和信號m后,再推薦產品k。 在歧視定價下,廠商先觀測到消費者的信息透露策略φ和信號m后,再推薦產品和定價。無論哪種情況,只有在廠商推薦后,消費者才能觀察到廠商所推薦產品k價值uk的實現值和價格。 這一模型應用信息設計理論捕捉了數據-隱私交易的幾個特征:(1)消費者的信息透露策略可以解釋為消費者對個人數據的保護策略,例如是否允許購物網站訪問Cookies等;(2)消費者只有在獲得廠商推薦后,才能知道(自然決定的)產品估價,這體現了推薦系統在當前消費互聯網領域的普遍應用,以及消費者的有限注意力。作者證明,廠商有動機承諾不進行價格歧視,但非歧視定價反而有損消費者福利——原因是如果有價格歧視,消費者可以用信息披露影響價格,而沒有價格歧視,消費者只能披露更多信息以換取準確推薦。如果消費者能預先承諾保留一部分信息,能改善自身處境。 2.行為理論 數據要素市場化的一大應用場景是消費者出讓個人數據,換取消費互聯網平臺的更好服務。此時,對消費者偏好和理性程度的刻畫成為評判數據市場社會福利的重要出發點。Liu et al.(2020)考察了當一部分消費者存在弱自我控制,容易受廣告誘惑購買成癮品時的個人數據交易問題,證明存在成癮消費時,任何消費者向平臺分享個人數據的行為都可能導致商家向低控制力消費者推送成癮品廣告的成本降低,從而損害社會福利。 具體設定如下:一個數字化平臺服務一單位連續統消費者。平臺可以搜集消費者的數字足跡,形成關于消費者偏好的有用信息。平臺上有兩個消費品賣家,分別出售兩類消費品,一類是正常品A, 一類是成癮品B。三類消費者{S,W,O}比例分別為πS、πW和1-πS-πW。分別代表強自制力、弱自制力和其他人。強自制力消費者永遠不會購買成癮品,弱自制力消費者在一定條件下會買成癮品,第三類其他人則兩種消費品都不買。根據行為經濟學對成癮品消費和自制力的建模思路,消費者的選擇可以分為兩步:第一步,消費者從一個菜單的集合中選擇最優菜單;第二步,消費者從最優菜單中選擇最終消費品。 Liu et al.(2020)捕捉了現實中個人數據要素市場化的一大特征:即互聯網用戶存在較大差異和分層。且互聯網平臺的營收,較多依賴于短視頻、網頁游戲甚至網絡賭博等成癮品銷售。評估個人數據市場化的福利效應,不可忽視行為效應。 3. 機制設計 現實中,數據要素市場化不一定通過消費者-互聯網平臺交易或數據商交易的形式進行,傳統行業生產過程和數字新基建中所產生的大量有用數據可以通過應用機制設計理論,設計社會有效或賣家收益最大化的機制,實現數據要素市場化。 數據要素深度嵌入當今中國經濟的現實問題,而解決這些問題需要根據現有經濟學理論,結合中國實際,開展規范、扎實、全面的實證研究。 1.數據要素度量與生產率測算 準確度量數據要素存量、增量及其要素生產率,評估數據要素的宏觀和微觀經濟價值,是數據要素研究和政策應用的重要議題。當前中文文獻中有較多對于數字經濟定義、數字經濟度量的討論,但缺乏對于數據要素及其相關變量測算的研究。研究者可以跟蹤Jones and Tonetti(2020)、Veldkamp and Chung(2019)等框架,應用宏觀經濟增長模型,測算中國的數據要素及其生產率。 2.數字稅征收與區域經濟協調發展 當今中國,數字化平臺經濟蓬勃發展。但互聯網平臺的業務跨越地理界限,定價方式不同于傳統行業(例如淘寶、美團等互聯網平臺普遍為消費者提供免費甚至現金補貼),生產和消費普遍位置脫節。因此難以核算附加值和利益的地理歸屬。借鑒Jones and Tonetti(2020)、Veldkamp and Chung(2019)等的宏觀經濟增長模型框架,以及現有文獻中對數據要素微觀市場價值的評估方法,可以開展中國各地區、各行業數據要素對平臺經濟營收貢獻的實證研究,從而為全國統一的數字稅征收開辟方向,促進區域經濟協調發展。 3.隱私保護與數據交易 中國互聯網消費者隱私保護意識較弱,且付費意愿低,因此“隱私換服務”類型的數據要素市場化交易盛行。借鑒現有關于消費者作為數據賣家的數據要素交易文獻,對消費者隱私損失、成癮品消費、付費意愿、隱私外部性等影響個人數據交易有效性的種種因素做出系統的實證評估,從而為設計有中國特色的個人隱私保護機制和個人數據交易機制提供思路。事實上中國互聯網平臺的豐富數據也為評估現實世界中的消費者隱私偏好提供了極大便利。Chen et al.(2021)就利用手機支付寶小程序數據,結合問卷調查,發現對隱私偏好更高的用戶同時也對數字平臺的服務依賴更高,從而為解釋“隱私悖論”提供了新思路。 4.數據特性與平臺反壟斷 2020年以來,互聯網平臺反壟斷成為熱門的政策議題。眾多文獻已經指出,數據要素的規模報酬遞增性是導致產業市場企業分化和平臺壟斷的重要因素。在設計反壟斷制度時,必須考慮到互聯網平臺對用戶數據的獨占導致的反競爭效應,并設計合適的規制政策予以限制。同時,現有文獻也多指出了數據要素存在非競爭性,因此設計強制性的數據分享政策不僅有利于反壟斷,更有利于數據要素的充分利用。實證研究可以在數據要素的市場結構效應、反壟斷政策的政策評估、數據要素在不同行業的市場價值和非競爭性效應評估等方面為互聯網平臺反壟斷提供思路。
(二)數據要素交易機制
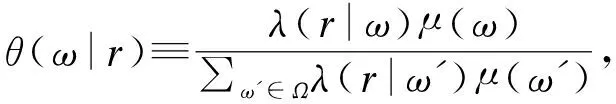
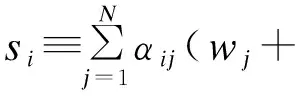
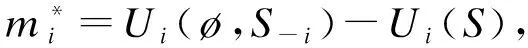

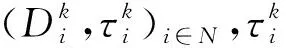
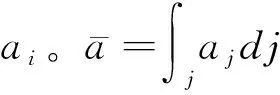
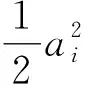
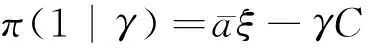
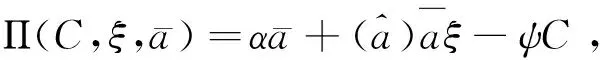
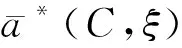
四、數據要素的經濟價值與實證評估
(一)數據要素的經濟價值
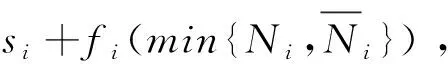
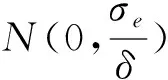
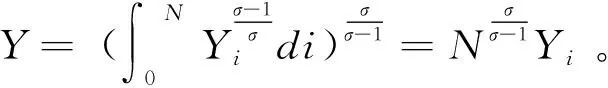
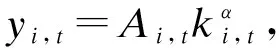
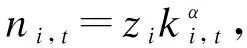
(二)數據要素經濟價值的實證評估
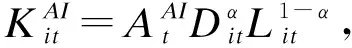
五、數據要素研究趨勢與展望
(一)追蹤學術前沿,創新理論工具

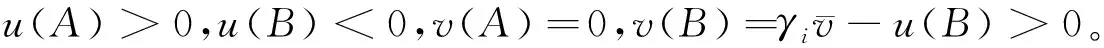
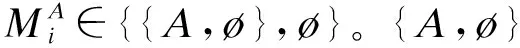
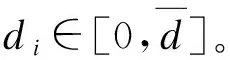
(二)聚焦中國問題,解決實證疑難
猜你喜歡
今日農業(2020年20期)2020-12-15 15:53:19
汽車維修與保養(2019年7期)2020-01-06 03:30:54
人民交通(2019年16期)2019-12-20 07:03:52
四川省干部函授學院學報(2019年2期)2019-08-27 01:20:38
消費導刊(2018年22期)2018-12-13 09:19:00
現代營銷(創富信息版)(2018年2期)2018-02-10 05:20:49
瞭望東方周刊(2017年34期)2017-09-13 17:13:26
生活用紙(2016年5期)2017-01-19 07:36:14
發明與創新(2016年16期)2016-08-21 13:56:16
公民與法治(2016年5期)2016-05-17 04:09:48
