基于PSOGA-BP的混合動力汽車非穩態工況聲品質評價
2022-06-18 02:13:40廖連瑩潘繼郭趙景波左言言廖旭暉孟浩東
重慶理工大學學報(自然科學) 2022年5期
廖連瑩,潘繼郭,趙景波,左言言,廖旭暉,孟浩東
(1.常州工學院 汽車工程學院, 江蘇 常州 213032;2.江蘇大學 振動噪聲研究所, 江蘇 鎮江 212013)
0 引言
混合動力汽車(hybrid electric vehicle,HEV)較傳統內燃機汽車,其車內噪聲總體水平有所下降,但乘客對HEV車內聲品質的感受并沒有明顯改善[1]。在某些非穩態工況下,HEV所產生的振動和噪聲,甚至會讓乘客感到更不舒服。因此分析HEV非穩態工況下的車內聲品質特點,找出影響HEV車內聲品質的關鍵因素,并采取相應的改進措施,從而提升HEV的乘坐舒適性顯得尤其重要。對于車內聲品質的研究,大量學者從主觀評價方法、客觀評價模型和應用上進行了探究。如Gauthier等[2]分別利用最小絕對收縮和選擇算子(LASSO),彈性網絡和逐步回歸3種算法構建了聲品質預測模型。通過比較,得到LASSO算法因具備有效控制評價參數數量,具有最準確的預測結果和便于構建評價模型等優點,在3種算法中成為最適合建立聲品質預測模型的一種算法。Duvigneau等[3]利用虛擬仿真的方法,建立了發動機聲品質評價模型。高印寒針對汽車穩態和非穩態工況下,利用GA-BP神經網絡和RBF神經網絡等方法建立內燃機汽車車內聲品質評價模型,取得了較好的評價效果[4-5]。徐中明等[6-7]利用粒子群-向量機同樣對內燃機汽車加速工況聲品質進行了研究,利用小波熵對汽車關門非穩態聲品質進行了分析,驗證了小波熵更能準確表征非穩態聲信號的時頻特性。朱仝等[8]利用遺傳算法優化的支持向量回歸方法對車內穩態噪聲進行了聲品質預測,提高了聲品質模型的預測精度。黃海波等[9-11]用Adaboost算法,利用深度信念神經網絡和GA-小波神經網絡,建立了車內聲品質評價模型,對內燃機汽車勻速工況車內聲品質進行了預測,提升了車內聲品質預測精度。趙向陽等[12]利用FELMS算法,對內燃機汽車勻速工況進行了聲品質研究,提高了車輛穩態工況聲品質預測精度。左言言等[13-15]對車輛聲品質進行主客觀綜合評價,依據心理聲學參數對聲品質的影響程度,利用LSSVM和神經網絡方法建立聲品質評價模型,選擇穩態工況對HEV車內聲品質進行了預測,取得較好的評價效果。
從以上分析可以看出,既往對聲品質的研究主要關注傳統內燃機汽車或者新能源汽車的穩態工況下的聲品質評價,針對HEV非穩態工況這種特殊工況的車內聲品質評價研究較少,所建立的評價模型是否適用于HEV非穩態工況聲品質評價還有待驗證。本文針對混合動力汽車原地熱機、緩加速、急加速、緊急制動、緩減速、滑行和變工況等非穩態工況,利用參考語義細分法進行主觀評價試驗。計算非穩態工況聲品質客觀參數,并進行相關分析。建立利用粒子群算法(PSO)和遺傳算法(GA)優化的BP神經網絡聲品質客觀評價模型。通過誤差對比,證明PSOGA-BP模型更適合進行HEV非穩態工況車內聲品質評價。
1 HEV車內噪聲樣本采集與處理
1.1 試驗設備
本次試驗選擇某汽車公司的混聯式HEV車輛作為試驗用車。選用SQuadriga I便攜式聲音分析儀,用于采集車內噪聲,為車內噪聲特性分析及車內聲品質分析提供必要數據。選用汽車檢測儀AllScanner,通過與OBD-Ⅱ接口連接工作后,采集反映車輛運行狀態的各參數數據,如發動機轉速、油門踏板深度、MG1轉速及扭矩、MG2轉速及扭矩、SOC值等。
1.2 傳感器及安裝位置
試驗所用傳感器主要有Head Acoustics雙耳麥克風、PCB麥克風、轉速傳感器等。
麥克風分別安裝在駕駛員、副駕駛及后排座椅乘員頭部附近,分別選取如圖1(a)的正駕駛右耳,如圖1(b)的副駕駛右耳和如圖1(c)的左后排乘客右耳3個位置為噪聲采樣點。

圖1 麥克風車內布置圖
1.3 試驗工況
本次試驗測試工況包括了HEV原地熱機、緩加速、急加速、急減速、緩減速、滑行和變工況等大部分非穩態工況:
1) 原地熱機。分發動機低怠速和高怠速。
2) 緩加速。控制油門踏板開度小于50%,從車輛靜止加速到120 km/h。
3) 急加速。完全踩下油門踏板,從車輛靜止加速到120 km/h。
4) 急減速。完全踩下制動踏板,速度從120 km/h減到車輛完全停止。
5) 緩減速。輕踩制動踏板,速度從120 km/h減速到60 km/h。
6) 滑行。既不踩油門踏板,又不踩制動踏板,車輛利用慣性進行滑行,從速度120 km/h減速到40 km/h。
7) 變工況。在20~60 km/h速度區間,短時間內,進行加速、減速、滑行等各工況的迅速轉換。
1.4 數據采集
試驗參照ECE R51和GB/T 18697—2002進行,采樣頻率為44.1 kHz,噪聲樣本信號長度為30 s。試驗路段選擇郊區開闊地,周邊30 m內無聲音反射物。分別采集試驗車輛在不同工況時噪聲樣本,每個工況測試2組數據。通過篩選,選擇測試效果較好的20組噪聲樣本作為后續分析樣本,并對20個樣本進行5 s長度的截取,組成新噪聲樣本,總共28組,最終共得到84個噪聲樣本。
2 聲品質主觀評價
2.1 評價試驗實施
聲品質主觀評價方法有排序法、等級打分法、成對比較法、語義細分法、參考語義細分法等[16]。這些評價方法各有優缺點,其中參考語義細分法是在語義細分法的基礎上優化而來,其優點之一就是適合樣本數較多的主觀評價試驗,本次HEV非穩態工況聲品質主觀評價試驗即采用此方法進行。試驗選取15號樣本,即從65 km/h加速到100 km/h行駛工況下左后排乘客右耳處噪聲作為參考聲樣本。采用5級語義細分評價法,當評價噪聲樣本與參考聲樣本一樣好時賦值為3分,比較好時賦值4分,好得多時賦值5分,較差時賦值2分,差得多時賦值1分。
本次主觀評價試驗人員選擇,在考慮統計學和聽音經驗的基礎上,以及考慮HEV使用群體主要為年輕人的特點,選擇了20~40歲之間具有駕駛經驗和一定聲學基礎的人員共計24名,男女比例3∶1。
通過24位評價者,利用參考語義細分法分別對84個噪聲樣本進行評分,從評價結果來看,所有評價者評分都使用了滿刻度評分,即最低分打1分,最高分打5分。因評價者采用的刻度范圍一致,因此可以對評價結果直接進行統計分析。利用幾何平均法對評價結果進行處理后,得到84個噪聲樣本的主觀評價值如表1所示。
2.2 試驗數據可靠性分析
根據參考語義細分法評價結果的特征,正確可信度高的評價者的評價結果間存在較大的相關性。為檢驗聲品質主觀評價結果的有效性,計算了所有評價者評價結果幾何平均與各評價者評價結果的相關系數,如表2所示。
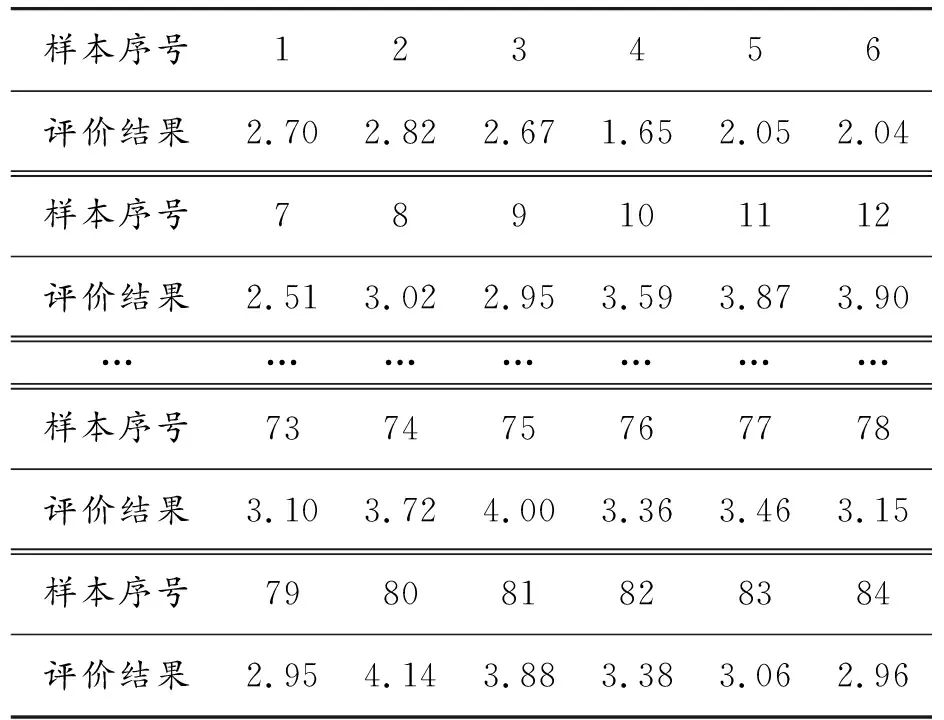
表1 所有評價者主觀評價結果

表2 主觀評價結果相關系數
為使評價結果一致性相對較高,相關系數應達到0.7~0.8以上。從表2可以看出,TP3、TP12、TP14和TP21 4位評價者的相關系數小于0.7,給以剔除,剔除后剩余20位評價者。對20位評價者的主觀評價結果再次進行幾何平均計算,得到84個噪聲樣本的最終主觀評價值。
2.3 評價結果分析
為便于對聲品質進行評價,使用式(1)對以上聲品質主觀評測結果進行歸一化:
(1)
式中:X*為歸一化后的各聲音樣本分值;Xi為各聲音樣本主觀評價分值;Xmin為所有聲音樣本主觀評價最小分值;Xmax為所有聲音樣本主觀評價最大分值。各聲音樣本主觀評價分值如表3所示。
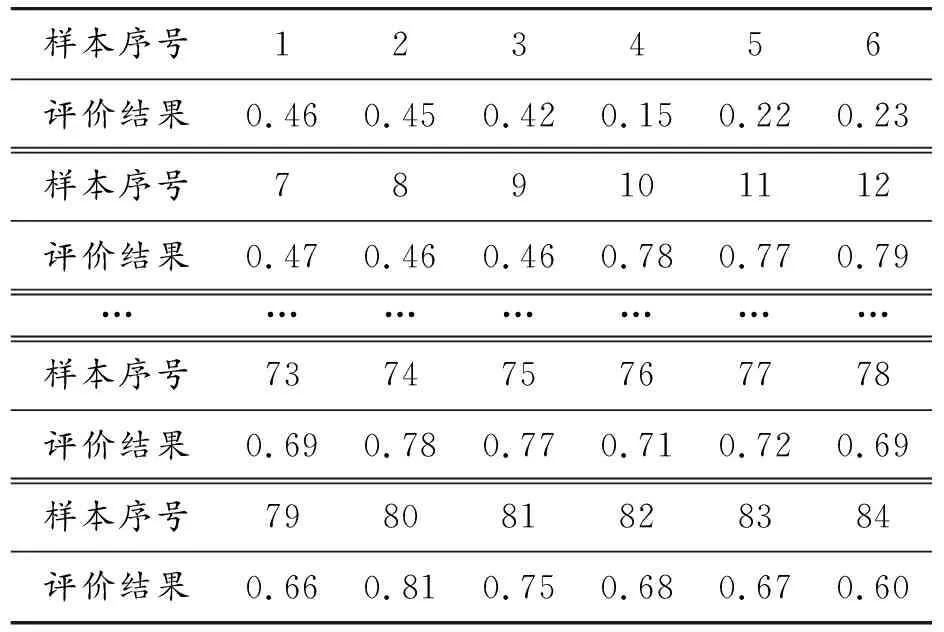
表3 聲音樣本主觀評價得分
3 客觀參數計算及相關性分析
3.1 客觀參數計算
聲品質客觀參數是聲品質客觀評價的基礎,本試驗選擇響度、音調度、AI指數、波動度、粗糙度、尖銳度、A聲壓級和聲壓級8個客觀參數,對84個噪聲樣本根據各客觀參數計算模型進行計算,得到表4所示的客觀參數值。

表4 聲品質客觀參數值
3.2 相關分析
為確定客觀參數與主觀評價結果之間的關系,利用Matlab軟件對兩者之間進行相關分析。同時對不同工況下主觀評價結果與客觀參數相關性也進行了計算分析,分析結果顯示急減速工況是個特殊的工況,其主觀評價結果與響度、AI指數、粗糙度、A聲壓級和聲壓級的相關性與其他工況的相關性呈相反狀態。在實際駕駛車輛時,急減速工況出現的概率較低,僅在緊急情況下才會發生,因此在研究HEV聲品質評價時,剔除急減速工況聲樣本。對剩余的78個聲樣本重新進行相關性分析,得到表5所示的結果。

表5 主觀評價值與客觀參數的相關系數
從表5可以看出,整個非穩態工況主觀評價結果與客觀參數的相關性都不高,但除了音調度外,其他客觀參數在0.01水平上顯著相關。考慮到聲壓級的相關性較低,因此在后續客觀評價模型建立時,只選擇響度、AI指數、波動度、粗糙度、尖銳度和A聲壓級6種客觀參數進行建模。
4 PSOGA-BP預測模型建立
4.1 粒子群算法
通過評價者對混合動力汽車車內聲品質進行評價,過程非常復雜,費時費力,評價結果受多種因素影響,因此建立一種聲品質評價模型對聲品質進行評價是一種不錯的選擇。考慮人耳對聲音感受,以及HEV非穩態工況聲品質均呈非線性,因此本文采用神經網絡對聲品質進行預測。為使HEV聲品質預測模型精度進一步提高,同時避免遺傳算法(GA)算法收斂速度慢的缺點,在GA-BP模型的基礎上,引入收斂速度快的粒子群算法(PSO),組成PSOGA混合算法,可以克服單種算法的局限性,實現優勢互補。PSOGA算法具有更好的全局搜索最優解的能力,在適應度、收斂速度和預測精度上體現較大優勢,從而提高了算法的綜合性能。
PSO屬于全局隨機搜索算法,通過一群粒子在空間里不斷調整自身位置Xi和速度Vi來搜尋最優解。在這過程中,每個粒子可以尋得到一個最優解,這個解叫作個體極值,用Pbest表示。將Pbest與其他粒子共享,把整個粒子群中最優的Pbest作為全局最優解,稱為全局極值,用Gbest表示。粒子群中的個體粒子再根據Pbest和Gbest調整Xi和Vi來得到全局最優解[17-18]。
其中Xi和Vi的調整公式為
Xi+1=Xi+Vi+1
(2)
Vi+1=wVi+c1r1(Pbest-Xi)+c2r2(Gbest-Xi)
(3)
式中:w表示慣性權重因子;c1和c2表示學習因子,取值[0,2];r1和r2表示隨機數,取值[0,1]。
PSO算法全過程為:粒子群初始化,粒子適應度計算,尋找Pbest,尋找Gbest,更新粒子的Xi和Vi,輸出最終全局最優解。
4.2 PSOGA-BP網絡建立
建立的PSOGA-BP網絡流程步驟如下:
1) 首先確定BP網絡結構。為了便于把預測結果與BP和GA-BP神經網絡模型進行比較,此預測模型的BP網絡結構選擇與它們一致,確定為6-6-1結構。即把響度、AI指數、波動度、粗糙度、尖銳度、A聲壓級6個參數作為輸入層的6個節點,隱含層選擇6個節點,輸出層為聲品質預測結果1個節點,如圖2所示。
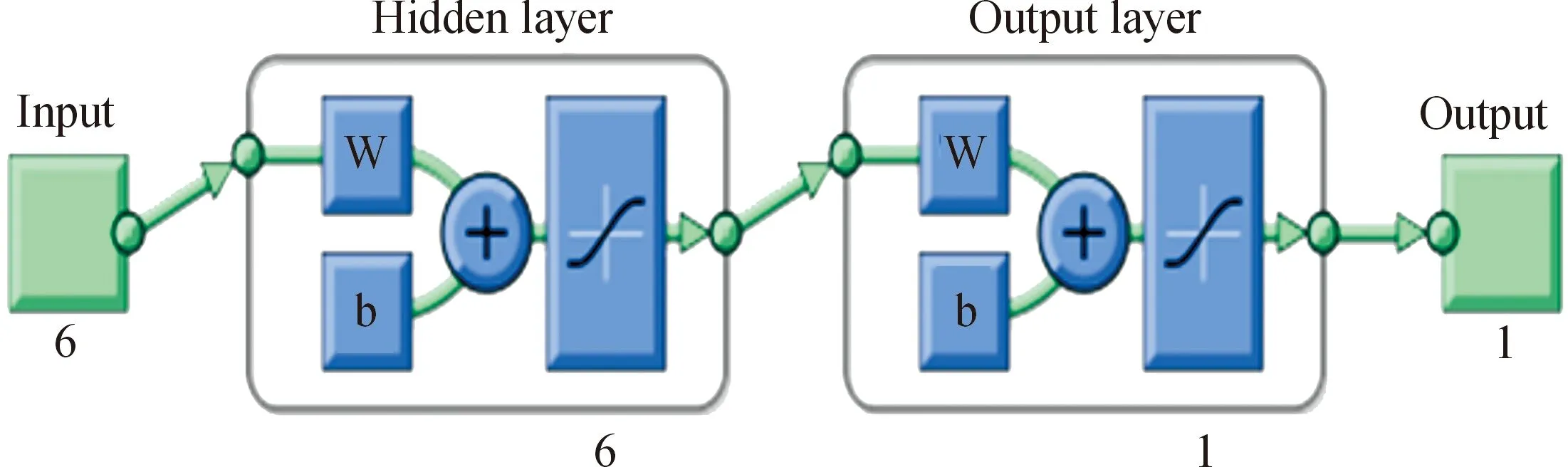
圖2 BP神經網絡聲品質預測模型結構示意圖
2) 初始化網絡及初始化粒子群,確定各參數值:染色體長度為49;種群規模為40;最大進化代數為200;交叉概率為0.8;變異概率為0.07;最大慣性權重因子為0.9;最小慣性權值因子為0.4;學習因子為2。
3) 通過計算適應度函數,搜索Pbest和Gbest,按規則對粒子群的Xi和Vi進行更新。
4) 進行粒子群的交叉操作。
選擇適應度值較好的粒子,按照設定的概率,利用式(4)和式(5)位置交叉算子和速度交叉算子對第i個粒子速度和位置與第j個粒子速度和位置進行交叉,對適應度較優的粒子重新放回粒子群進行下一步操作。

(4)

(5)
式中:α和β表示[0,1]之間的隨機數。
5) 進行粒子群的變異操作。
按照設定的概率選擇適應度值較差的粒子,分別根據式(6)和(7)的位置變異和速度變異算子,對粒子的位置和速度進行變異操作,將變異后的粒子重新放回粒子群。

(6)
(7)
式中:f(g)=r3(1-ei/emax),ei為當前迭代次數,emax為最大迭代次數,r1,r2,r3均為[0,1]之間隨機數。
6) 更新Pbest和Gbest。
7) 判斷PSOGA迭代運算是否滿足結束條件,滿足則輸出最優權值和閾值,否則返回繼續對種群進行初始化。
8) BP神經網絡權值閾值更新。
9) 判斷BP神經網絡訓練是否達到結束條件,如果不滿足,返回重新進行權值閾值調整,并進行訓練;如果滿足,則訓練結束。
PSOGA-BP算法流程如圖3表示。

圖3 PSOGA-BP算法流程框圖
4.3 聲品質評價
利用圖3所示的PSOGA-BP算法,進行混合動力汽車聲品質客觀評價。選取歸一化處理的78個噪聲樣本中的70個噪聲樣本,實現對網絡的訓練,訓練結果如表6所示。
將剩余8個聲樣本的6種客觀參量,導入建立的PSOGA-BP神經網絡評價模型中,計算得到此8個聲樣本的聲品質客觀評價值及誤差,如表7所示。
從表7可以看出,PSOGA-BP聲品質預測模型的預測結果與主觀測試結果較為吻合,誤差較小,說明PSOGA-BP預測模型可較精確地對HEV車內聲品質進行預測。

表6 PSOGA-BP神經網絡聲品質預測模型權值與閾值

表7 PSOGA-BP聲品質預測模型預測結果
5 聲品質預測結果精度對比分析
為了驗證PSOGA-BP聲品質預測模型的效果,把預測的8個聲樣本的聲品質結果與BP神經網絡模型、GA-BP神經網絡模型進行比較,利用折線圖對預測結果進行顯示,如圖4所示。
由圖4可以看出,3種聲品質預測模型的8個噪聲樣本的預測結果均較接近于主觀評價值,其中PSOGA-BP聲品質客觀評價模型,除樣本51外,其他樣本的預測值更加接近主觀評價值。為進一步驗證PSOGA-BP聲品質預測模型的精確度,把模型預測誤差分別與GA-BP和BP模型進行對比,如圖5所示。

圖4 聲品質預測模型預測值曲線

圖5 不同聲品質評價模型預測誤差直方圖
從圖5可以看出,利用普通BP神經網絡對HEV車內聲品質的預測誤差較大,最大達到21.22%。使用遺傳算法和粒子群算法優化遺傳算法的GA-BP和PSOGA-BP模型進行HEV聲品質預測后,無論均方根誤差、平均相對誤差還是最大相對誤差都有所下降。特別是PSOGA-BP模型的均方根誤差僅有3.89%,最大誤差也只有12.72%。對BP神經網絡進行優化后的PSOGA-BP模型結合了粒子群優化和遺傳算法優點,能顯著提高預測結果的精度,說明該模型適合運用于HEV車內聲品質預測。
6 結論
1) 選擇原地熱機、緩加速、急加速、緊急制動、緩減速、滑行和變工況等涵蓋HEV大部分非穩態工況,進行了車內噪聲測試。采用參考語義細分法,較全面地評價了非穩態工況HEV車內聲品質。評價結果表明HEV車內聲品質與車輛運行工況緊密相關。
2) 結合遺傳算法和粒子群算法,建立了PSOGA-BP神經網絡聲品質預測模型,預測結果顯示,均方根誤差僅為3.89%,平均相對誤差降到5.95%,最大誤差只有12.72%,優于對比模型。說明PSOGA-BP神經網絡聲品質預測模型較適合用于非穩態工況下的HEV車內聲品質預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
