貿易業務風險分析及防范建議
2021-01-04 18:20:45劉軍劉玉峰周夢甜
航空財會 2021年6期
關鍵詞:風險
劉軍 劉玉峰 周夢甜
摘要近年來,國有企業在開展和參與貿易業務的過程中發生了多項重大經營風險和法律糾紛,給國有資產安全帶來了諸多風險和挑戰。本文從大宗商品融資性貿易及“空轉”“走單”貿易的主要特征和表現形式入手,結合貿易業務實際案例中總結的經驗和教訓,分析開展貿易業務存在的風險,并針對性地提出應對措施建議,為防范貿易業務風險提供借鑒和參考。
關鍵詞 貿易;風險;體系化防控
DOI: 10.19840/j.cnki.FA.2021.06.005
一、融資性貿易的主要特征和表現形式
融資性貿易是指參與交易的各方主體在商品和服務的價值交換過程中,依托相關權益或行業地位,綜合運用各類交易手段和金融工具,以短期融資或信用增持為目的,增加交易方的現金流量或信用評級。
融資性貿易主要有以下特征:(1)虛構交易背景或人為增加交易環節;(2)上游供應商和下游客戶均為同一實際控制人控制,或上下游之間存在特定利益關系;(3)合同標的由另一方實質控制;(4)直接提供資金或者通過結算票據、辦理保理、增信支持等方式變相提供資金。
融資性貿易通常存在以下表現形式[1]:
1.采購合同、銷售合同形式簡單且具有一致性。合同中一般不明確約定具體的交貨時間、交貨地點,交貨方式一般約定為“倉庫交貨”,交貨時間通常為一個區間段。貿易業務下的采購、銷售合同常常格式基本一致,同一貨物、金額基本相等,也可能多份合同在同一時間或相近時間簽訂,僅付款時間存在先后。
2.人為增加交易環節,交易上下游存在關聯關系或特定利益關系,企業無加入貿易鏈條的商業合理性。
3.貿易合同毛利為零或負,或存在明顯不合理的異常之處。如:“低賣高買”、合同中未約定市場價格變化的保障機制、商品價格不受市場變化所左右、貨物檢驗由下游單位負責等。
4.不參與交易談判或貨物流轉過程,貨物未發生實際轉移。不見供應商、下游客戶、貨物的“三不見”貿易形式;通過“走單、走票、不走貨”進行交易流轉;貨物并未發生實際交付和流轉,貿易標的始終由一方實質控制等。
5.其他表現形式。如:非專業貿易企業開展的與主業或熟悉領域無關的貿易;貿易形成的倉單、票據等質押融資、信用證期限越來越長等。
二、貿易業務損失案例分析
(一)循環貿易偽造經營業績
2015年,某礦業企業所屬子公司在無真實貿易背景的情況下,采取簽訂虛假貿易合同、虛開增值稅專用發票等手段循環“購銷”鋼材,虛增經營業績30多億元。
該案例為循環模式融資性貿易業務,如圖1所示。業務中,與該公司開展貿易業務的上下游為同一公司或關聯公司,整個貨物流轉形成一個閉合回路,從而使該公司達到短期內擴大經營規模、完成經營考核指標等目的。
(二)委托采購貿易貨權失控
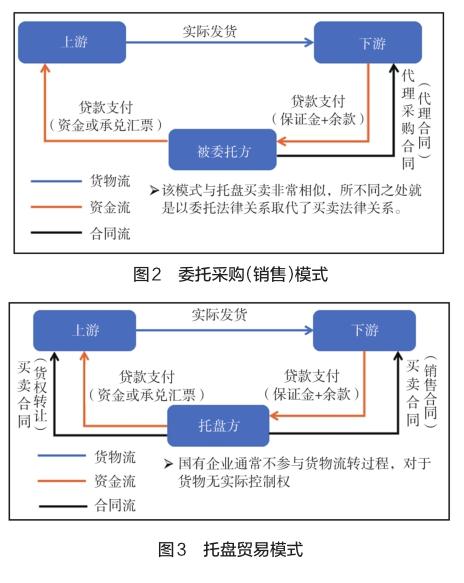
2014年至2016年,自然人羅某的控股公司委托8家企業代其從境外進口貨物,以相關企業代開的90天遠期信用證支付貨款。羅某通過偽造第三方倉庫資料,在未按合同約定付款的情況下,私自出庫并出售相關貨物非法獲利4億多元。
該案例是較為典型的委托采購(銷售)模式的融資性貿易,如圖2所示。業務中,受托方接受下游公司委托代為采購相關貨物,并將采購、保管、銷售等環節全部或部分委托下游公司或其關聯方完成[2],期間并不直接有效控制貨權,導致錢貨兩空。
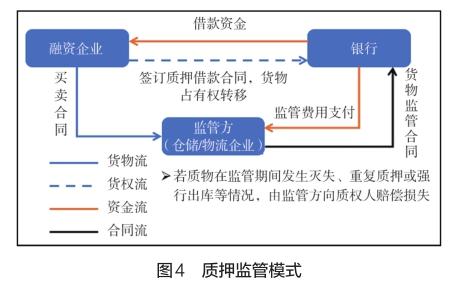
(三)墊資貿易形成大額資金損失
2009年至2013年,某礦業企業所屬子公司開展鉛錠貿易,因對方資金鏈斷裂形成0.73億元債權逾期。2014年,某企業所屬子公司利用自身銀行信譽分別開展電解銅、化工品貿易,因下游企業未能按約支付貨款導致60多億元損失。
相關案例為典型的托盤模式融資性貿易業務,如圖3所示。業務中,托盤方利用信譽、資金等優勢采購大宗商品,下游利用信用期間或匯票承兌期獲得融資,該業務存在較高資金敞口風險。
(四)商品違約出庫或重復質押導致資金損失
2014年末,某棉花企業所屬公司開展倉單質押業務,在庫棉花被擅自違約出庫和重復質押,導致約8000多萬元質押資金面臨損失風險。
上述案例為質押監管模式的融資性貿易業務,如圖4所示。業務中,監管方根據質權人(金融機構)委托為融資方提供的質物進行監管,實質上是通過監管方對質物的監管為融資人增信[2]。由于部分企業實際無倉庫或額外倉儲空間,質物一般都委托第三方管理,滅失、重復質押或強行出庫的可能性較大,從而產生損失風險。


如上述質權人為企業,且質權人與融資企業直接進行貿易業務,上述貿易模式就變為倉儲保管模式,如圖5所示。倉儲保管貿易模式融合了托盤和質押監管兩種形式:一是買方也即托盤方,通過相關貨物買賣交易為融資企業提供資金;二是相關貨物的倉儲保管企業,以倉儲保管質押交易,為融資企業增加授信。
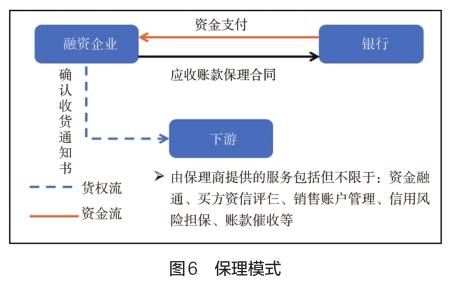
(五)貿易應收賬款保理導致大額資金損失風險
2013年2月,廣州某金屬企業(銷售方)與新疆某物資企業(采購方)開展融資性貿易業務,銷售方以該貿易業務應收賬款,向銀行申請辦理有追索權的保理融資,由于采購方無法支付貨款,導致銷售方保理融資被追索,形成損失。
該案例為保理模式融資性貿易業務,如圖6所示。業務中,銷售方將其對購買方的貿易類應收賬款轉讓給保理商(金融機構),由保理商向其提供一系列金融服務[2]。如果融資人違約無法支付貨款,將導致保理融資被追索,形成損失。
三、貿易業務的主要風險
綜合案例和貿易的特征分析,貿易業務可能存在以下風險:
(一)合規及法律風險
2013至2021年,國家多次下發了一系列文件,嚴格禁止開展融資性貿易及“空轉”“走單”類貿易業務。根據最高法相關判例和司法解釋,存在借貸行為或以借貸為主的貿易合同會因違反國家金融管制的強制性規定而被認定為無效合同[3]。
(二)貨權控制風險
若缺乏貿易業務中的貨物控制權,上下游企業故意不履行合同或合謀開展虛假交易,企業可能無法通過處置貨物以減少損失,從而面臨財產損失風險。
(三)資金損失風險
若無法對下游資信水平進行科學、充分的風險評估,或不能在交易過程中對資金結算實施有效監控,很可能產生資金風險[4]。
(四)人員專業經驗不足風險
貿易業務涉及環節眾多、利益關系鏈條復雜,被利用于套取資金的情形屢見不鮮,因此,通常需專業且經驗豐富人員進行管理,且操作過程需要仔細謹慎。
(五)發票和稅務風險
若在不具有真實貿易背景的情況下向下游企業開出增值稅專用發票,易被稅務機關認定為虛開發票而受到處罰[4]。
(六)信息不準確導致戰略制定風險
若開展貿易業務或制定戰略時僅運用相對方提供的“被加工”的信息,可能導致出現錯誤判斷或制定不合理的戰略規劃。
(七)企業聲譽風險
大中型國有企業是政府及銀行部門重點監管的對象,若發生重大經營性風險或大額損失,社會輿論可能產生各種負面評價,影響公司的社會聲譽。
四、風險防范對策
鑒于上述風險,貿易業務開展過程中,建議堅持“六位一體”開展全方位管控,強化事前、事中、事后全流程業務跟蹤,重點關注客戶管理和體系化風險防控,建立危機處理預案機制,通過綜合一體化管理,降低貿易業務的風險,詳見圖7所示。
(一)加強客戶評價和管理
嚴格選擇貿易合作伙伴,建立新客戶準入審核制度,通過制定嚴格的內部控制流程加強貿易合作伙伴的選擇。加強貿易背景的真實性審查,確保業務真實、合規。對于現有客戶進行分類管理,并定期追蹤其經營情況,動態評價客戶的經營況狀變化,對業務模式和合作額度進行相應調整。嚴格核查上下游關聯關系,多手段、多角度開展關聯關系調查,杜絕空殼公司的業務。
(二)規范合同內容和跟蹤管理
審慎簽訂貿易合同,優先選擇本企業的標準合同范本,嚴格規范合同標的、交貨方式、結算方式、違約責任等合同內容。加強在手合同的跟蹤和分析,定期對合同執行情況進行評價,對于執行情況有偏差的合同及時進行匯報,考慮是否終止合作。
(三)完善組織人員和信息化建設
建立和完善組織結構,明確各部門職能,加強貿易業務開展過程中的審核和審批管理,通過各職能部門共同把關、共同決策,降低貿易業務風險。同時,加強專業化隊伍建設,組織各類培訓,提高業務人員對于貿易流程的理解和執行能力。積極利用大數據、云計算、人工智能等互聯網技術構建信息化平臺,提升其信息化程度,通過信息化手段進行貿易業務的實際操作和風險管控。
(四)加強資金單據管控和倉儲運輸管理
1.加強資金管控。一是嚴格檢查合作方資信情況。規范貿易合作方、擔保人的資金信用背景調查,防范資金信用風險。二是加強資金集中歸集和監管。結合企業實際,合理制定資金歸集與使用管理制度,優化資金監控流程,實時監控資金去向和收支情況。三是壓實抵押擔保責任。合理評估抵質押物市場價格,保證擔保抵押效力。四是嚴格把控貿易業務授信。合理分配授信額度,嚴格控制付款信用期限。五是加強應收賬款管控。建立監督和清收機制,專人定期辦理。
2.加強單據審核。嚴格審查客戶提供的合同、發票、報關、物流、提單等相關資料的真實性,分析各項資料之間的邏輯合理性,發現異常情況要加強追蹤和調查,防范單據偽造、變造風險。
3.加強增值稅開票事前檢查。嚴格規范增值稅開票流程;對于特殊稅務事項,要做好政策研究和合規性審查。
4.加強貨權控制。一是盡可能要求先貨后款,嚴密監控出庫和貨權轉移過程,確保交易的實物流轉可控;二是嚴格落實業務、財務及倉庫的存貨定期盤點,確保存貨安全;三是選擇資質信譽好的倉儲和物流單位,密切關注其服務和信用變化情況,嚴防相關方企業挪用貨物或“一貨二賣”。
(五)建立風險預警機制和監督機制
建立動態風險管控機制和市場變化預警機制,安排專職人員跟蹤市場狀態和貿易業務各流程的實時狀態,防止信息不對稱的產生,發現異常時及時采取有效財產保全措施。
建立貿易業務監督機制,將法務、風控、財務等各職能部門納入到業務實施監管環節中,通過定期開展貿易業務的風險排查,使客戶管理、合同管理、付款單據審核、物流等一系列環節都實現有監督、有控制。
(六)提高危機應對能力和效果
在分析、總結行業風險事件成因、處置過程、效果的基礎上,借鑒同行單位的應對經驗,結合公司自身風險防范、控制各項制度措施,系統編制風險處置預案。當發生貿易風險事項時,及時采取終止合作、財產保全等措施最大程度降低損失。AFA

參考文獻
[1]蔡振.國企融資性貿易業務的識別、危害與防范[J].企業改革與管理,2018(15):82-83.
[2]張曉惠.國有企業融資性貿易的風險分析及防范[J].經濟師,2019(9):272-273+275.
[3]呂冰心.融資性貿易的實證研究及裁判建議[J].人民司法.2020(31):81-87.
[4]張靜.國有企業融資性貿易風險分析[J].中國儲運.2018(12):105-107.
(審稿:王遠偉編輯:趙晴)
猜你喜歡
現代經濟信息(2016年19期)2016-10-20 15:36:30
現代經濟信息(2016年19期)2016-10-20 15:20:15
中國科技博覽(2016年18期)2016-10-19 06:47:57
中國市場(2016年33期)2016-10-18 13:14:16
中國市場(2016年33期)2016-10-18 13:13:33
中國市場(2016年33期)2016-10-18 12:55:28
商(2016年27期)2016-10-17 06:18:10
商(2016年27期)2016-10-17 05:41:05
商(2016年27期)2016-10-17 05:33:32
大眾理財顧問(2016年9期)2016-10-11 17:05:02
