高職院校商務英語技能型人才認知診斷評價模型構建與應用研究
2023-06-13 12:14:23郭辰玥
寧波職業技術學院學報 2023年3期
郭辰玥
摘 ?要: 通過實證分析驗證了采用認知診斷評價方法對專門用途英語職業技能等級測試結果進行深度解讀的可行性,刻畫了高職院校商務英語學習者閱讀理解加工技能的掌握情況,總體上學生對細節提取等局部信息加工技能掌握較好,推測與判斷技能次之,歸納與比較技能掌握較弱,此外為每位學生提供了多維度、精細化的個性化反饋報告。研究結果顯示,與傳統的技能鑒定標準唯“合格”論相對,診斷評價能準確反映學生在知識技能結構上潛在的個體差異,為高職院校商務英語人才能力發展研究與新時代職業能力評價改革實踐提供新思路。
關鍵詞: 認知診斷; 高職院校; 專門用途英語; 個性化學習
中圖分類號: G710 ? ? ? ? ?文獻標志碼: A ? ? ? ? ?文章編號: 1671-2153(2023)03-0058-08
測試效度理論指出,科學的知識和能力評價方式應能根據學習者在測試項目上的作答表現,準確診斷他們當前的知識狀態和技能結構,并提供全面、細粒度的反饋信息,以便利益相關者及時進行干預和教育決策,真正形成以評促學、以評促教的良性循環[1]。在專門用途英語(ESP)教育領域,學生英語職業技能水平認定的一個重要途徑是參加各行業和組織舉辦的職業技能等級考試,獲取相應的技能等級鑒定證書。但鑒定結果大都停留在“合格”與否的終結性評價,無法有效揭示學生的個體差異,不能反映發展潛力,阻礙個性化干預與學習。鑒于此,本研究聚焦商務英語技能型人才的語言能力模型構建,以實用英語交際職業技能等級測試為素材,探究了構建認知診斷評價模型生成個性化反饋報告和學習建議的可行性,以期為職業教育智慧化教學改革和人才能力評價方式優化提供參考。
一、認知診斷評價簡介及發展現狀
(一)認知診斷評價的內涵及優勢
認知診斷評價是當下心理測量領域的研究熱點之一,屬于交叉學科的范疇。其實施以現代教育測量理論為基礎,依靠各類認知診斷模型(又名“診斷分類模型”)等統計工具的輔助分析和技術驗證,已在國內外許多學科和專業得到廣泛應用。在二語測試領域,一些大型標準化語言測試如托福考試、托業考試、我國的英語能力等級考試(NETS)、西語專業四級考試等,已實現了運用診斷模型了解考生二語認知加工過程和技能掌握情況的成功探索[2-4]。
利用大數據分析助力精準教學和自主學習是診斷評價的主要優勢之一。認知診斷評價通過為學習者測試時的知識狀態建模,來預測學生技能的強弱項,歸納認知規律,刻畫不同學生之間的具體能力差別[5]。該評價方式有助于教師因材施教,按需設計課堂教學活動,給予真實有效的反饋;也有利于學生依據個性化反饋自我調整,準確定位和掃除學習障礙[6];用人單位和學校則可根據評價結果選拔人才、研制培養計劃,提升技能人才的競爭力。
(二)認知診斷評價的發展現狀
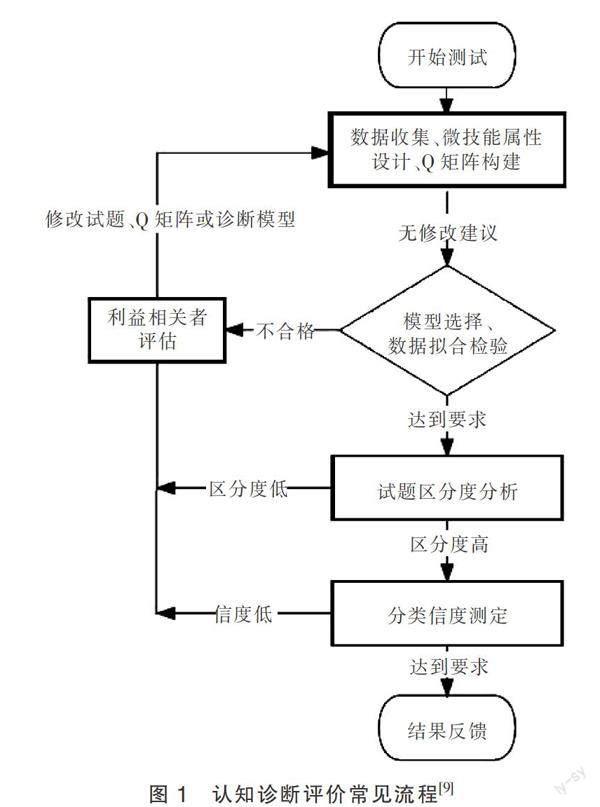
認知診斷評價方法可通過模型構建,從被試已知的作答表現推知個人及群體層面潛在的知識狀態及認知屬性掌握情況,為利益相關者提供細粒度的診斷性反饋。認知屬性,一般簡稱屬性或微技能,是認知診斷評價方法的一個重要概念,泛指完成測試任務所需的任何知識、技巧、能力等[7]。屬性定義是診斷評價的第一步,巴赫曼和帕默(Bachman & Palmer)等學者建議結合具體測試的場景和用途來定義適用的微技能[1]。診斷評價的第二步是構建Q矩陣,以標明屬性和題目之間的對應關系[8],一道試題可測量多個屬性,模擬真實作答過程中多個微技能的交互作用,Q矩陣通常需要經量化和質性方法反復檢驗。第三步為選擇合適的認知診斷模型并進行模型—數據擬合檢驗。在擬合良好的前提下,最終提取模型診斷信息,反饋學習成效并進行個性化干預。認知診斷評價方法的常見流程如圖1所示。
認知診斷評價技術目前在教育界已逐漸推廣,但梳理現有成果發現,在二語測試領域其實際應用尚存在以下問題:一是診斷評價應用研究的多樣性不足[10]。主要表現在研究對象和測試內容及用途的同質性較高[11]。研究對象多為普通教育階段的二語學習者,對其他群體代表如職業院校學生的外語學習效果了解相對有限;測試內容一般以英語為主要語種且多為學術用途,而較少關注職場英語如商務英語等;大多圍繞高利害語言測驗,服務于人才選拔,而很少采用本地化測驗,服務于課堂學習成效的評價。
二是對診斷評價結果的準確性以及個性化反饋的有效性探討還不夠充分。部分實證研究的重心仍集中在前期的數據分析階段,而豐富的量化診斷信息無法直接提供給考生和其他利益相關者,需要通過加工處理進一步轉化為準確、清晰、全面的個性化反饋報告。閔尚超、何蓮珍等學者指出可以結合認知診斷和標準設定方法驗證診斷分類結果的準確性,并成功生成了基于中國英語能力等級量表的標準參照個性化反饋,有效增強了診斷反饋的可讀性和對教學的指導作用[11-12]。但除此以外,其他關于診斷報告設計及反饋質量評估的研究相對缺乏,對如何優化診斷評價結果和個性化反饋之間的轉化路徑尚不明確。
三是關于診斷反饋和補救性干預對二語教學反撥效應的長期研究較少[13]。因為認知診斷是一種橫向研究,應用診斷分類模型對數據進行橫向分析,因此時效性較強。而縱向的認知診斷評價研究由于時間跨度較長,可追蹤研究對象在接受診斷反饋及教學干預后的一段時期內的語言學習效果,因此在評估反饋結果的有效性和促進自主學習方面更具價值。然而,目前縱向認知診斷研究大都停留在模型開發階段,實證研究缺乏。同時,收集長期數據難度大、保障測試工具及衡量標準的一致性、開發何種學習資源或語言支持活動等問題仍待解決。
綜上所述可得:(1)在二語測試領域的應用主要集中于學術英語考試,對學習者在職場英語水平測試中所運用的信息加工技能尚不明確;(2)總體呈現重前期診斷,輕后期反饋的趨勢,對促進個性化學習發揮的作用較為有限;(3)縱向研究較少,關于診斷報告反撥效應的追蹤研究不足。基于研究范圍的限制,本文主要針對前兩個問題,運用認知診斷評價方法分析高職院校學生的特殊用途英語技能掌握情況,探討進一步優化職業技能等級測試分數報告的有效手段,實現診斷反饋與職業情境下的語言能力標準對接,科學評價高職院校商務英語技能型人才的能力水平。擬解決的問題有:(1)高職院校商務英語學習者的閱讀理解加工技能如何劃分?(2)高職院校商務英語學習者的閱讀理解加工技能掌握情況如何?(3)商務英語測試的診斷結果如何轉化為個性化的反饋報告?
二、認知診斷模型在商務英語技能型人才評價中的實施應用
(一)數據來源和研究工具
本研究的數據來自某高職院校260名應用英語專業學生在商務英語課堂閱讀測試中的作答反應,在2022年9月到10月完成測試,共收回有效答卷252份。其中,男生32人,女生220人,比例約為1∶6.9,年齡跨度在20—25歲之間,樣本主體為大一大二學生,生源包含普高生和三校生。測試的形式為機考,素材來自參與“1+X”證書制度試點的實用英語交際職業技能等級證書(VETS)中級和高級考試題庫中的閱讀試題,包含4篇文章,20道二元計分的單選題,語言能力要求對應中國英語能力等級量表(CSE)四級和五級水平。VETS考試大綱顯示,目前的成績報告方式為百分制,滿分100分,60分及以上為合格。英語閱讀文本選自商務工作領域的真實場景,內容涉及外貿函電、市場調研報告、合同糾紛普法宣傳等,模擬職場情境下交易磋商、業務推廣、交易善后等典型工作任務,考查高職英語專業學生的跨文化交際能力和分析解決實際問題的綜合能力,相比于標準化語言測試更能反映用人單位對不同崗位英語交際職業技能的實際需求。
在研究中借助R語言編程運行CDM和GDINA程序包對閱讀測試數據進行認知診斷分析,包括Q矩陣驗證,題目層面的模型選擇,模型與數據的擬合優度評估,項目參數估計,學生個體和整體的屬性掌握模式估計等。
(二)技能屬性劃分和定義
文獻梳理發現,目前學界和標準化語言考試大綱對閱讀理解能力的進一步細分主要有以下五種:(1)識別詞義;(2)理解細節信息;(3)分析推斷;(4)理解句法結構;(5)整合銜接[14-15]。本研究邀請3位有豐富商務英語一線教學經驗的教師結合VETS技能等級標準對閱讀能力的要求,對本次課堂閱讀理解測試的4個語篇進行了初步的任務分析,確定所考查的三種微技能、適用職業場景及能力描述,見表1。
(三)Q矩陣構建和驗證
為確保認知診斷結果的信度和效度,基于Q矩陣的診斷模型經過了反復優化。首先,構建初始Q矩陣:由專家們根據屬性界定標準,獨立標定每個閱讀項目所考查的關鍵微技能,在Q矩陣上對應編碼為1,不需要則為0。接著比較標定結果,對分歧之處組織進一步討論,當超過半數專家達成一致,則對該項目與屬性的關系進行相應修改。此外,為反映學生真實的信息加工方式,經學生同意隨機抽取8人,通過有聲思維法報告實際作答過程并錄音,用于為專家標定結果提供參照。學生的英語水平是影響Q矩陣構建的重要因素之一。以試題17為例:
...... Party A is sure that Party B has breached an essential term of the contract and wants to end their cooperation. What should party A do next?
本題考查學生聯系上下文理解段落含義的能力,劃線部分對應文中不同位置的信息,需通過比較確定關鍵信息“end their cooperation”和選項中“terminate the contract”的同義替換關系。而有3名考生在口頭報告中提到不認識“terminate”一詞,使用了推測詞義的答題技巧,因此,專家討論后認為應將“推測與判斷”補充定義為本題考查的微技能(項目17:A1 0,A2 1,A3 1)。
其次,進行認知診斷前導試驗(pilot study):應用GDINA模型對所得初始Q矩陣和測試數據進行診斷分析。魯普(Rupp)等研究者指出,試題區分度、題目水平上的模型數據擬合優度等參數可作為判定題目質量及Q矩陣適切性的量化依據[16-17]。結果顯示,除項目4外,試題整體的區分度良好(DItest=0.337,DI4=0.005);題目水平上的擬合度較高(S-χ2test,p>0.05),證明Q矩陣能較好地代表試題和屬性之間的關系,僅有4題(項目6、8、9、16)與模型的擬合欠佳。經專家評估后認為以上5題或因語言難度、句長、題型等不具典型性,影響了診斷效果,同意加以移除。對題目重新編號后確定的Q矩陣見表2。每個技能屬性對應的試題數量分別為7、4、10題,每題平均考查1.4個(21/15)微技能。
最后,為完善初始Q矩陣,進一步通過量化手段對其進行檢驗。納胡拉(Nájera)等比較了不同的Q矩陣驗證算法,推薦Hull算法和在屬性、樣本量或項目數較少的情況下使用Wald檢驗[18]。通過R程序包cdmTools和GDINA對該Q矩陣進行實證檢驗。考慮到樣本量較小,在編程時設置單調約束條件,即學生掌握的屬性數量和答對題目的概率正相關,并分別通過Wald檢驗和Hull算法驗證,修改建議見表3。
觀察左右兩個Q矩陣可發現,除個別項目外,兩種算法對初始Q矩陣提出了不同的修改意見。對于純量化分析得出的結論,通常建議由專家根據試題具體情況再次把關[14]。因此,在重新逐題審視后,專家小組探討確定了用于進一步分析的最終Q矩陣,部分采納了量化分析建議。以項目15為例(圖2):左圖顯示,原屬性組合[101](A1+A3)可釋方差得分(PVAF<0.95)優于算法建議的[001](A3);右圖也證明該題掌握兩個技能的考生正確率顯著提高,因此未采納該建議。
接著進行模型選擇,陳慧麟等學者建議,閱讀理解加工技能之間交互的可能性較高,宜選擇飽和的診斷分類模型[19],如G-DINA模型,允許題目對應不同的補償性關系(即答題時掌握一種或幾種技能可補償其他未掌握的技能),并匹配適用的診斷模型[20]。GDINA模型通常要求大樣本量(N>1000),但馬文超等研究者提出設置先驗分布和單調約束(指技能屬性掌握數量和答對概率正相關)等模型參數條件可有效提升小樣本(N≤200)的分類準確率[21]。
項目水平上的模型選擇結果表明,不同測試題目可匹配不同的診斷模型,如補償性的DINO模型、非補償性的DINA模型,說明屬性間潛在的不同交互關系。修改后的最終Q矩陣見表4,用于生成后續的診斷反饋信息。
三、數據分析與解釋
(一)模型數據擬合評價
模型與數據的擬合檢驗是判斷測試及其所產生的診斷反饋信息是否有效的前提條件。擬合度可以從兩方面進行評估:(1)模型與數據的絕對擬合優度檢驗;(2)不同模型與數據的相對擬合優度比較。后者用于選擇恰當的認知診斷模型。
表5結果顯示,飽和的GDINA模型和補償性的ACDM模型的均方根殘差(SRMSR)均低于0.08,表明后兩個模型與數據的絕對擬合較為準確;而比較不同模型的相對擬合優度可發現,GDINA模型依然是最佳的,具有最小的-2似然比(-2 log-likelihood)和AIC(赤池信息量),其次是ACDM,DINA和DINO模型。但DINA模型具有最小的BIC(貝葉斯信息量),陳勁松等學者指出,這可能是因為BIC更偏好簡化模型[22]。此外,模型間的似然比檢驗顯示,飽和的GDINA模型和各嵌套模型的擬合度存在顯著差異(p<0.01),GDINA模型的擬合優度顯著高于其他模型。
(二)具體技能掌握情況及信度分析
表6呈現了252名考生對于3個商務英語閱讀測試微技能的掌握情況及屬性水平上的分類信度(classification accuracy)。整體技能掌握的概率在0.47—0.75之間,具體而言,約有47%的學生掌握了“歸納與比較”閱讀技能,說明該技能的難度要求是三者中最高的;其次,掌握了“推測與判斷”能力的學生約占64%;最容易的是“提取細節信息”,超過七成的學生已具備該技能。三種微技能的分類準確率都較高,超過0.8,表明當前模型能準確地評估考生技能層面的掌握和未掌握情況。
(三)技能認知模式分布情況及信度分析
考生群體的技能認知模式分布情況也可通過模型分析獲得,這充分體現了認知診斷評價反饋內容多維度的優勢,可從宏觀和微觀等不同層面進行報告,對學生學業整體情況的分析報告也可為課堂教學改革提供借鑒和參考。
本次商務英語閱讀測試共有8種潛在的技能認知模式(23),按認知模式普遍程度由高到低排列,學生分布最廣泛的技能掌握類型是[110],約占27.1%,表明近三成的學生已掌握細節信息提取和推理判斷能力,但尚不能熟練運用整合歸納能力完成商務情境下的閱讀任務,對該技能的訓練有待于進一步強化。這一方面與技能難度有一定關聯,歸納與整合能力通常被認為是高階閱讀技能,學生熟練程度因而相對較低;另一方面,提取細節信息和推理判斷能力常組合出現,說明這兩個技能之間的聯系可能較為密切,在今后的教學中可以適當融合加以培訓,以提升課堂教學的效率。教師還可以據此認知規律,結合課程內容規劃教學路徑,由淺入深地強化對學生商務英語閱讀技能的培養。從分類信度而言,群體層面的認知模式分類準確率較高,除人數較少的[010]和[001]類型外,其余均在0.54—0.92不等,而測試整體的分類準確率達0.77,即隨機抽取一名考生,有77%的概率正確診斷出他實際的閱讀技能掌握情況。
(四)商務英語閱讀測試個性化學習診斷報告及反饋
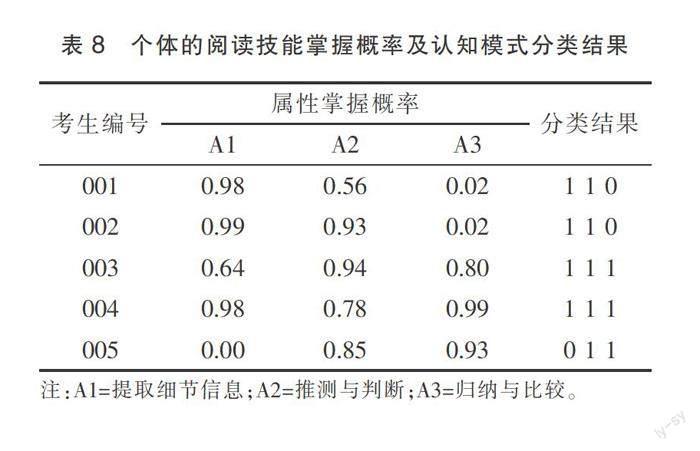
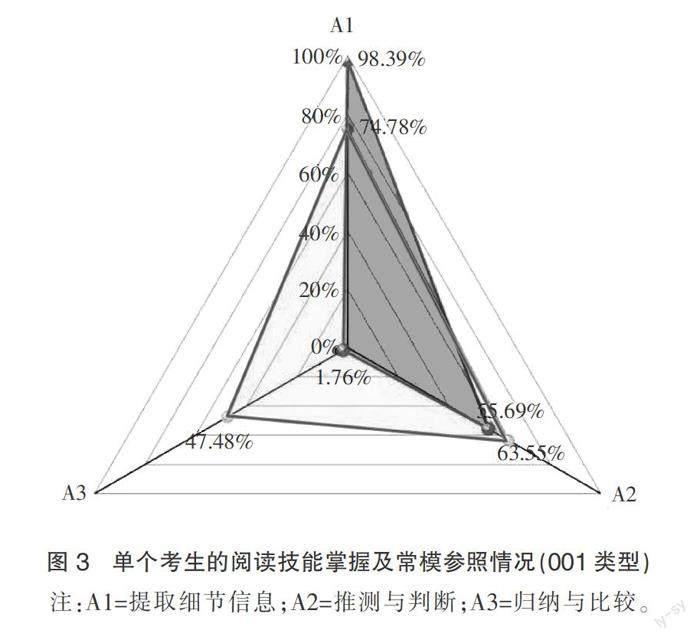
在學生個體層面,診斷報告的主要關注點集中在技能掌握模式的精細化反饋和建議上。表8列舉了樣本前5位學生在3個閱讀分項技能上的掌握概率。魯普等學者建議以概率大于等于0.5作為判定一項技能已掌握的標準[16],由此可確定每位學生的認知模式分類結果,例如,考生1的診斷結果為:A1掌握;A2掌握;A3未掌握。在呈現報告時,李令青等學者認為匯報掌握概率更能體現認知診斷評價的價值,借助概率可進一步比較不同屬性掌握程度的高低[23]。仍以考生1為例,A1識別細節信息掌握得最好,A2推理與判斷次之,A3整合與歸納掌握較差。為使這一細化的分類結果更為直觀,以雷達圖的形式(見圖3)呈現該考生的技能掌握概率,同時融入常模參照的反饋形式,將單個考生的屬性掌握概率與受試群體的平均水平進行對照,更有利于為各利益相關者的教育決策提供參考。
為使診斷結果更為清晰易讀,報告中還補充了文字闡述,以完成特定職場情境下典型工作任務的方式,對學生的語言應用能力進行刻畫,以下舉例加以說明,屬于[110]技能認知模式的考生將得到如下反饋信息:
在本次課堂英語閱讀測試中,你能讀懂語言難度適中、話題豐富的商務材料,如調研報告、信函等。
· 在完成“市場調研”任務時,你能較為準確地理解報告內容和圖表數據,讀取關鍵信息。
· 在完成“交易磋商”任務時,你能根據交易方的條件,較好地評判和推測交易雙方的觀點和態度。
為進一步提升你的商務英語閱讀技能:
· 你需要多加練習“交易善后”任務,訓練歸納整合文本內容,提升妥善處理違約問題的能力。相關習題等學習資源可在課程線上平臺獲取。
四、總結與展望
本項目作為高職商務英語課堂教學評價改革的初步成果,旨在探索運用心理測量領域的認知診斷模型解讀職場英語水平測試數據的可行性,了解高職院校英語專業學生閱讀理解加工技能掌握的特性,并評估借助診斷性反饋開展個性化學習實踐的有效性。通過對學習者個體閱讀能力強項和弱項的診斷,以及考生整體能力掌握情況的分析,本項目為課程學習者提供了職場情境下使用英語完成商務交際活動熟練程度的反饋報告,以及個性化的學習資源和建議。診斷結果將實用商務英語閱讀技能劃分為定位識別、推測判斷、整合歸納三個層次,對應市場調研、交易磋商、交易善后三個工作任務,采用文字描述和雷達圖等不同形式立體化呈現診斷信息。該個性化技能成長檔案的構建,有助于學習者根據自身情況精確設定學習目標,也為教師、企業、學校等不同育人主體動態調整和規劃人才培養方案提供參考和借鑒。
未來,依托大數據分析的診斷性評價手段將進一步深化“互聯網+職業教育”的混合式教學模式,打造個性化的智慧外語學習環境,優化教學水平,培養學生的自主學習能力,提升復合型商務英語專業人才培養的質量,為其贏得更廣闊的發展前景。
參考文獻:
[1] BACHMAN L,PALMER A. Language Assessment in Practice [M]. Oxford:Oxford University Press,2010.
[2] LEE Y-W, SAWAKI Y. Application of three cognitive diagnosis models to ESL reading and listening assessments[J]. Language Assessment Quarterly,2009(3):239-263.
[3] MIN S, HE L. Developing individualized feedback for listening assessment:Combing standard setting and cognitive diagnostic assessment approaches[J]. Language Testing,2022(1):90-116.
[4] 王萌萌. 信息技術支持下的外語能力精準診斷與教學[J]. 中國遠程教育,2021(9):69-75.
[5] 段惠瓊,黃洪燕. 基于認知診斷的英語閱讀研究述評[J]. 外語教學理論與實踐,2022(1):63-70.
[6] 何蓮珍,熊笠地. 二語聽力理解認知加工模式發展新探:結合認知診斷與標準設定的方法[J]. 外語界,2021(4):35-43.
[7] BUCK G, TATSUOKA K. Application of the rule-space procedure to language testing:Examining attributes of a free response listening test[J]. Language Testing,1998(2):119-157.
[8] TATSUOKA K. A probabilistic model for diagnosing misconceptions by the pattern classification approach [J]. Journal of Educational and Behavioral Statistics,1985(1):55-73.
[9] SHI Q, MA W, ROBITZSCH A, et al. Cognitively Diagnostic Analysis Using the G-DINA Model in R [J]. Psych,2021(3):812-835.
[10] BRUNFAUT T. Future challenges and opportunities in language testing and assessment:Basic questions and principles at the forefront[J]. Language Testing,2023(1):15-23.
[11] HE L, XIONG L, MIN S. Diagnosing listening and reading skills in the Chinese EFL context:Performance stability and variability across modalities and performance levels[J]. System,2022(106):102787.
[12] MIN S, ZHANG J, LI Y, et al. Bridging local needs and national standards:Use of standards-based individualized feedback of an in-house EFL listening test in China[J]. Language Testing,2022(3):425-452.
[13] ZHAN P. Longitudinal learning diagnosis:Minireview and future research directions[J]. Frontiers in Psychology,2020(11):1185.
[14] JAVIDANMEHR Z, SARAB M. Retrofitting non-diagnostic reading comprehension assessment:Application of the G-DINA model to a high stakes reading comprehension test[J]. Language Assessment Quarterly,2019(3):294-311.
[15] RAVAND H. Application of a cognitive diagnostic model to a high-stakes reading comprehension test[J]. Journal of Psychoeducational Assessment,2016(8):782-799.
[16] RUPP A, TEMPLIN J, HENSON R. Diagnostic assessment:Theory,methods,and applications[M]. New York,NY:Guilford.
[17] SAWAKI Y, KIM H-J, GENTILE C. Q-matrix construction:Defining the link between constructs and test items in large-scale reading and listening comprehension assessments[J]. Language Assessment Quarterly,2010(3):190-209.
[18] N?魣JERA P, SORREL M, DE LA TORRE J, et al. Balancing fit and parsimony to improve Q-matrix validation[J]. British Journal of Mathematical and Statistical Psychology,2021(74):110-130.
[19] 陳慧麟. 英語專業大學生閱讀技能的認知診斷及其教學啟示[J]. 教學研究,2022(2):73-79.
[20] DE LA TORRE J. The generalized DINA model framework[J]. Psychometrika,2011(2):179-199.
[21] MA W, JIANG Z. Estimating cognitive diagnosis models in small samples:Bayes model estimation and monotonic constraints[J]. Applied Psychological Measurement,2021(2):95-111.
[22] CHEN J, DE LA TORRE J, ZHANG Z. Relative and absolute fit Evaluation in cognitive diagnostic modeling[J]. Journal of Educational Measurement,2013(2):123-140.
[23] 李令青,韓笑,辛濤,等. 認知診斷評價在個性化學習中的功能與價值[J]. 中國考試,2019(1):40-44.
Research on Construction and Application of Cognitive Diagnostic Evaluation Model for Business English Skilled Talents in Higher Vocational Colleges
GUO Chenyue
(Zhejiang Institute of Economics and Trade, Hangzhou 310018, China)
Abstract: This empirical study analyzes the feasibility of employing cognitive diagnostic methods to interpret students performance results of an ESP career qualification test, creating profiles for Business English learners from a higher vocational college based on their mastery levels of reading cognitive processing skills. In general, students have a better grasp of partial information processing skills such as detail extraction, followed by speculation and judgment, and weaker mastery of induction and comparison. In addition, each student is provided with a multi-dimensional, refined and personalized feedback report. Results indicate that contrary to traditional career qualification criteria which focus solely on a “pass” standard, cognitive diagnosis can accurately reflect potential individual differences in students knowledge and skill structure, thus offering insights into research on how to improve skill cultivation of Business English talents from higher vocational colleges and how to reform evaluation system of vocational skills in the new era.
Keywords: cognitive diagnosis; higher vocational college; ESP; individualized learning
(責任編輯:程勇)
猜你喜歡
東方教育(2016年11期)2017-01-16 01:14:10
都市家教·上半月(2016年12期)2016-12-29 09:49:15
中國教育技術裝備(2016年19期)2016-12-27 19:32:41
亞太教育(2016年34期)2016-12-26 18:28:29
考試周刊(2016年77期)2016-10-09 12:05:08
考試周刊(2016年77期)2016-10-09 11:59:13
科技視界(2016年20期)2016-09-29 12:58:21
科技視界(2016年20期)2016-09-29 12:56:14
科技視界(2016年20期)2016-09-29 11:31:29
大眾理財顧問(2016年8期)2016-09-28 13:57:10
