基于Lasso降維的不平衡數(shù)據(jù)處理方法在股票中的應(yīng)用
2023-10-28 21:36:01嚴(yán)濤王舒梵姜新盈
經(jīng)濟(jì)研究導(dǎo)刊 2023年17期
嚴(yán)濤 王舒梵 姜新盈
摘? ?要:為了在高維財(cái)務(wù)股票數(shù)據(jù)中選出重要的特征以及如何選出優(yōu)質(zhì)股票是每個(gè)投資者所面臨的問(wèn)題。為了減少特征選擇過(guò)程中人為因素的干擾,提出一種基于Lasso降維的股票分類(lèi)方法(LR-SC)。首先將高維的財(cái)務(wù)股票數(shù)據(jù)放入Lasso進(jìn)行特征選擇,對(duì)于降維后的數(shù)據(jù),選擇每股收益前10%的為少數(shù)樣本,之后計(jì)算每個(gè)少數(shù)類(lèi)樣本到svm生成的超平面的距離,通過(guò)Random-SMOTE算法來(lái)生成新的少數(shù)類(lèi)樣本,并選擇距離超平面最遠(yuǎn)的后50%的多數(shù)類(lèi)樣本來(lái)剔除,以此來(lái)達(dá)到樣本之間的平衡。實(shí)驗(yàn)結(jié)果表明,其選出優(yōu)質(zhì)股的精度有所提高,證明了該算法在股票選股上的可行性和有效性。
關(guān)鍵詞:股票選股;不平衡數(shù)據(jù);lasso降維;Random-SMOTE
中圖分類(lèi)號(hào):F830.2? ? ? ? 文獻(xiàn)標(biāo)志碼:A? ? ? 文章編號(hào):1673-291X(2023)17-0070-04
一、研究背景
當(dāng)今,我國(guó)金融市場(chǎng)欣欣向榮,股票市場(chǎng)得到了越來(lái)越多的關(guān)注,如何從眾多的股票中選擇優(yōu)質(zhì)股對(duì)于投機(jī)人來(lái)說(shuō)就顯得尤為重要。從股票的選擇來(lái)看,就是對(duì)那些上市大公司的價(jià)值進(jìn)行估計(jì),而一個(gè)公司的財(cái)務(wù)數(shù)據(jù)可以很明顯地反映一個(gè)公司的經(jīng)營(yíng)情況,而且已經(jīng)有許多的研究者對(duì)股票的漲幅情況和財(cái)務(wù)數(shù)據(jù)做了相關(guān)研究,成果都表明它們之間有重要的聯(lián)系。
對(duì)于股票數(shù)據(jù)來(lái)說(shuō),優(yōu)質(zhì)股票畢竟是占一小部分,所以數(shù)據(jù)是極度不平衡的。現(xiàn)如今在不平衡問(wèn)題上分類(lèi)方法主要有兩個(gè)方面,一是算法方面的處理,有代價(jià)敏感學(xué)習(xí)[1]、集成學(xué)習(xí)[2]和單類(lèi)學(xué)習(xí),集成學(xué)習(xí)算法是通過(guò)將一些弱分類(lèi)器進(jìn)行組合來(lái)提高分類(lèi)器的性能,如Adaboost[3]算法等。二是數(shù)據(jù)處理方面,有兩大類(lèi),分別是過(guò)采樣和欠采樣。欠采樣就是對(duì)少數(shù)類(lèi)樣本進(jìn)行增加已達(dá)到數(shù)量上和多數(shù)類(lèi)樣本持平。過(guò)采樣的基本算法就是SMOTE[4]算法,它是通過(guò)對(duì)少數(shù)樣本進(jìn)行隨機(jī)的線性插值,依此來(lái)創(chuàng)造新樣本。但由于參與合成的樣本是隨機(jī)選擇,這就導(dǎo)致新合成的新樣本質(zhì)量不高。Borderline-SMOTE[5]算法首先確定出邊界集,對(duì)其邊界集上的樣本進(jìn)行插值,董燕杰等人用Random-SMOTE算法把插值放入三角形內(nèi),緩解了少數(shù)類(lèi)樣本分布稀疏的問(wèn)題[6]。文獻(xiàn)[7]所提出的SVMOM算法通過(guò)少數(shù)類(lèi)樣本的密度和距離權(quán)重來(lái)選擇樣本,進(jìn)而緩解噪聲樣本帶來(lái)的影響。Douzas Georgios等人提出了G-SOMO:一種基于自組織映射和幾何SMOTE的過(guò)采樣方法,該算法以知情的方式確定創(chuàng)建人工數(shù)據(jù)實(shí)例的最佳區(qū)域,并在數(shù)據(jù)生成過(guò)程中利用幾何區(qū)域來(lái)增加其可變性[8]。通過(guò)實(shí)驗(yàn)結(jié)果,表明G-SOMO始終優(yōu)于初始的過(guò)采樣方法。欠采樣算法是對(duì)多數(shù)類(lèi)冗余的樣本進(jìn)行剔除。
根據(jù)上述的研究,針對(duì)股票分類(lèi)問(wèn)題,本文提出一種基于LASSO-R.SMOTE股票分類(lèi)方法(Based on Lasso-R. SMOTE stock classification method,LR-SC)。首先通過(guò)Lasso算法對(duì)高維的股票財(cái)務(wù)數(shù)據(jù)進(jìn)行壓縮。將降維后的股票財(cái)務(wù)數(shù)據(jù)放入SVM支持向量機(jī)內(nèi)產(chǎn)生超平面。對(duì)于少數(shù)類(lèi)的股票財(cái)務(wù)數(shù)據(jù),通過(guò)Random-SMOTE算法來(lái)產(chǎn)生新的少數(shù)類(lèi)樣本,再選擇距離超平面距離最遠(yuǎn)的后50%的多數(shù)類(lèi)樣本數(shù)據(jù)來(lái)剔除,以達(dá)到少數(shù)類(lèi)和多數(shù)類(lèi)樣本的平衡。實(shí)驗(yàn)結(jié)果表明,本文所提出的LR-SC算法相較于其他算法,分類(lèi)效果更好。
二、相關(guān)理論
(一)Random-SMOTE算法
Random-SMOTE算法是在三個(gè)樣本內(nèi)產(chǎn)生新樣本,算法流程如下:一是隨機(jī)選擇一個(gè)初始樣本以及和周?chē)膬蓚€(gè)樣本a、b組成一個(gè)三角形;二是在樣本a、b上進(jìn)行隨機(jī)線性插值產(chǎn)生臨時(shí)樣本y;三是在初始樣本和臨時(shí)樣本之間通過(guò)如下公式產(chǎn)生新的少數(shù)類(lèi)樣本Xnew:
(二)LASSO算法
現(xiàn)在大多數(shù)關(guān)于股票的研究,其特征的選取往往是基于研究人員的檢驗(yàn)來(lái)選取,這樣摻雜主觀性的選擇或多或少會(huì)帶來(lái)一定的誤差或是特征的遺漏。為了盡可能地去減少這方面所引起的誤差,本文選擇Lasso方法來(lái)進(jìn)行降維處理。Lasso方法就是在普通的線性模型中增加了一個(gè)L1的懲罰項(xiàng),這是由于當(dāng)數(shù)據(jù)的維數(shù)過(guò)高而導(dǎo)致不是列滿秩,進(jìn)而無(wú)法采用最小二乘法來(lái)求解。懲罰項(xiàng)就是對(duì)部分參數(shù)進(jìn)行壓縮為0,而達(dá)到降維的目的。
等價(jià)于:
其中λ為調(diào)和參數(shù)。
(三)評(píng)價(jià)指標(biāo)
不平衡數(shù)據(jù)的特殊性,使得傳統(tǒng)的平衡數(shù)據(jù)的評(píng)價(jià)指標(biāo)已不再適合,這是因?yàn)殄e(cuò)分的代價(jià)是不一樣的,所以需要選擇更加合理的評(píng)價(jià)指標(biāo)。本文所選擇的是混淆矩陣結(jié)合G-mean和F1-value[9]的評(píng)價(jià)方法,其中F1-value和G-mean值是處于同等重要地位。
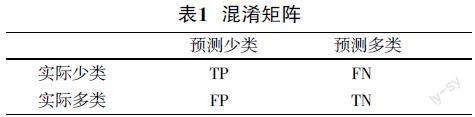
表1? 混淆矩陣
其中,TP表示實(shí)際為少數(shù)類(lèi)且預(yù)測(cè)為正確樣本數(shù)量,F(xiàn)N是實(shí)際為少數(shù)類(lèi)且預(yù)測(cè)錯(cuò)誤的樣本數(shù)量,F(xiàn)P是實(shí)際為多數(shù)類(lèi)且預(yù)測(cè)錯(cuò)誤的樣本數(shù)量,TN是實(shí)際為多數(shù)類(lèi)且預(yù)測(cè)正確的樣本數(shù)量。
(1)Re:少數(shù)類(lèi)樣本被成功分類(lèi)的精度:
(2)Re:多數(shù)類(lèi)樣本被成功分類(lèi)的精度:
(3)Pr:分類(lèi)器的分類(lèi)精度:
(4)G-mean值:
(5)F1-value值:
由于G-means值僅考慮了少數(shù)和多數(shù)類(lèi)被正確分類(lèi)的情況,其值只會(huì)隨著少數(shù)類(lèi)樣本和多數(shù)類(lèi)樣本正確分類(lèi)精度的提高而提高。F1-value值是綜合考慮了召回率和查準(zhǔn)率這兩種情況,可以較為全面地反映少數(shù)類(lèi)被正確分類(lèi)的精度。本文選取Re、Rp、G-mean、F1-value值這四個(gè)指標(biāo)來(lái)研究算法的分類(lèi)效果。
三、LR-SC算法描述
假設(shè)在一個(gè)二分類(lèi)問(wèn)題中,數(shù)據(jù)集C=C(0)∪C(1),C(0)∩C(1)=Φ,|C(0)|>|C(1)|,其中少數(shù)類(lèi)樣本新增加的樣本為CNew(1)。LR-SC算法首先是對(duì)高維的財(cái)務(wù)股票數(shù)據(jù)進(jìn)行降維,使用Lasso算法對(duì)訓(xùn)練集的數(shù)據(jù)進(jìn)行特征選擇,降低維數(shù)。將處理好的訓(xùn)練集放入支持向量機(jī)SVM里來(lái)生成超平面,通過(guò)Random-SMOTE算法來(lái)生成新的少數(shù)類(lèi)樣本,并選擇距離超平面距離最遠(yuǎn)的多數(shù)類(lèi)樣本數(shù)據(jù)來(lái)剔除,最終合成新的訓(xùn)練樣本。
LR-SC算法流程:
輸入:高維不平衡的股票財(cái)務(wù)數(shù)據(jù)集C。
輸出:低維平衡的股票財(cái)務(wù)數(shù)據(jù)集。
Step1:將高維數(shù)據(jù)集用Lasso進(jìn)行降維得到新的訓(xùn)練集。
Step2:將新的訓(xùn)練集放入SVM進(jìn)行訓(xùn)練,生成超平面Σ。
Step3:確定少數(shù)類(lèi)樣本生成數(shù)量|C(1)New|= -|C(1)|。
Step4:對(duì)于少數(shù)類(lèi)樣本,通過(guò)Random-SMOTE產(chǎn)生其新樣本C(1)New。
Step5:CNew(1)和C(1)合并形成新的訓(xùn)練集Train_data_
min。
Step6:對(duì)于多數(shù)類(lèi)樣本,選取距離超平面Σ最遠(yuǎn)的后50%樣本進(jìn)行剔除,形成新的多數(shù)類(lèi)樣本Train_
data_most。
Step7:將Train_data_min和Train_data_min合并為T(mén)rain_data,放入分類(lèi)器里進(jìn)行訓(xùn)練。
四、數(shù)據(jù)集描述和處理
本文從wind金融數(shù)據(jù)庫(kù)選取了2019年300家A股制造業(yè)行業(yè)上市公司財(cái)務(wù)報(bào)表年報(bào)的相關(guān)數(shù)據(jù)作為訓(xùn)練時(shí)的數(shù)據(jù)特征,其中包括每股指標(biāo)、現(xiàn)金流量、資本結(jié)構(gòu)、償債能力、盈利能力、收益率、運(yùn)營(yíng)能力共35組特征,其訓(xùn)練標(biāo)簽選擇的是2020年的每股收益,用此數(shù)據(jù)集來(lái)驗(yàn)證本文所提出算法的有效性。對(duì)于股票財(cái)務(wù)數(shù)據(jù),把股票每股收益在前10%的記做陽(yáng)性樣本,即優(yōu)質(zhì)股,其余的樣本記做陰性樣本。為了去除不同量綱對(duì)實(shí)驗(yàn)結(jié)果的影響,對(duì)數(shù)據(jù)進(jìn)行歸一化處理。處理方法如下:
上式中Max,min為一組特征值的最大和最小值。
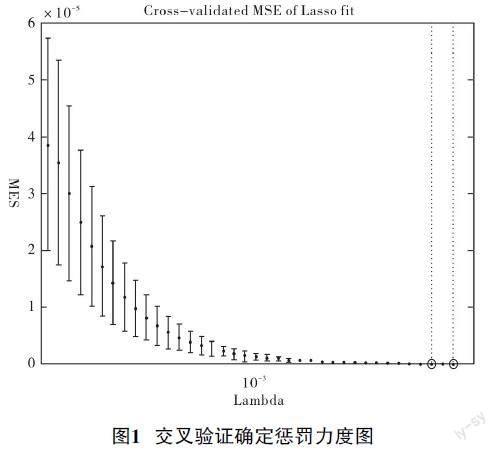
本文使用十折交叉驗(yàn)證來(lái)估計(jì)Lasso算法中的λ值,從圖中可以看出,λ的值不斷增大MSE(誤差平方和)呈現(xiàn)先降后升的趨勢(shì),其曲線的最低點(diǎn)對(duì)應(yīng)的就是MSE的最小值,此時(shí)的λ=0.0027,Lasso最終篩選出13個(gè)特征。將最后降維后的數(shù)據(jù)放入SVM中進(jìn)行訓(xùn)練。
為了測(cè)試本文中LR-SC算法的可行性,也為了驗(yàn)證Lasso算法可以得到更好降維結(jié)果,于是設(shè)計(jì)了和把該算法和Borderline-SMOTE算法、SMOTE算法、ISMOTE算法、SMOTE+TOMEK算法和RU-SMOTE分別在另外三種降維算法:主成分分析方法、因子分析方法和線性判別分析方法進(jìn)行精準(zhǔn)度的打分比較,為了確保實(shí)驗(yàn)結(jié)果的準(zhǔn)確性,每次使用的訓(xùn)練集和測(cè)試集統(tǒng)一按照7∶3進(jìn)行劃分,本文采取MATLAB2016b為仿真環(huán)境,其他算法均由imbalance-learn提供支持。本文SMOTE算法的K近鄰選取為5。
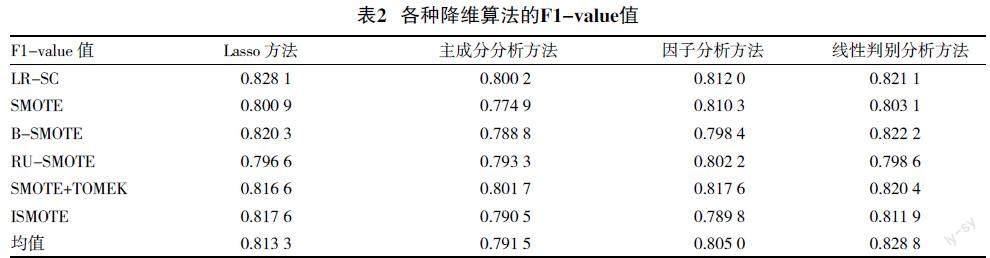
通過(guò)圖1的結(jié)果,將Lasso降維過(guò)后的財(cái)務(wù)數(shù)據(jù)用來(lái)實(shí)驗(yàn),將本文算法和其他五種算法在不同的降維方法下進(jìn)行打分比較。表2是各種降維算法在F1-value指標(biāo)上的打分情況,表3是各種降維算法在G-mean指標(biāo)的打分情況,圖2是六種算法在各種降維方法下的打分情況。
從表2的結(jié)果可以看出,在四種降維算法中,Lasso方法的最終均值最高,在Lasso方法的內(nèi)部也可以看出,本文提出的LR-SC算法相較于其他五種不平衡數(shù)據(jù)的處理方法,F(xiàn)1-value值得分最高,這是有Lasso方法在特征選擇的時(shí)候降低了人為的因素,減少誤差,對(duì)少數(shù)類(lèi)樣本的采樣是在三角形內(nèi)完成的,提高生成樣本的質(zhì)量。
從表2的結(jié)果可以看出,在四種降維算法中,Lasso方法的最終均值比線性判別分析方法稍低,只低了不到0.005。從Lasso方法的內(nèi)部來(lái)看,只有ISMOTE算法高于本文的算法,這是由于LR-SC算法提高了少數(shù)類(lèi)樣本的分類(lèi)精度,降低了對(duì)多數(shù)類(lèi)的分類(lèi)精度,以至于提高了F1-value的值而犧牲了G-mean的得分。但是,從整體而言,本文所提出的算法相較于其他算法都是有優(yōu)勢(shì)的,這也驗(yàn)證了LR-SC算法思想的有效性。
為了可以更加直觀明了地展示LR-SC算法在不同的降維算法下與其他算法的打分情況,繪制了六種算法在各種降維方法下的打分情況(見(jiàn)圖2),縱坐標(biāo)反映的是各種算法的得分范圍是從0-1,橫坐標(biāo)是Lasso方法、主成分分析方法、因子分析方法和線性判別分析方法這幾種降維算法。從結(jié)果上來(lái)看,Lasso方法對(duì)于高維股票財(cái)務(wù)數(shù)據(jù)降維效果更優(yōu)秀,本文所提出的LR-SC算法在整體上更優(yōu)。
五、結(jié)束語(yǔ)
本文針對(duì)股票財(cái)務(wù)數(shù)據(jù)分類(lèi)問(wèn)題,提出了一種基于Lasso降維的股票分類(lèi)方法(LR-SC),LR-SC算法是通過(guò)Lasso算法對(duì)高維股票財(cái)務(wù)數(shù)據(jù)進(jìn)行特征選擇,對(duì)處理后的數(shù)據(jù)通過(guò)Random-SMOTE算法來(lái)產(chǎn)生新的少數(shù)類(lèi)樣本,并通過(guò)距離來(lái)確定多數(shù)類(lèi)樣本剔除的數(shù)量。最后將樣本數(shù)量相等的平衡數(shù)據(jù)放入SVM進(jìn)行訓(xùn)練。這樣一方面保證避免了特征選擇時(shí)的人為因素干擾,也保證了少數(shù)類(lèi)及多數(shù)類(lèi)樣本在生成和剔除時(shí)的合理性,LR-SC算法在一定程度是提高了股票分類(lèi)的精度。本文提出的算法也存在些許不足之處,例如,在使用SVM時(shí),所使用的參數(shù)是默認(rèn)值,參數(shù)調(diào)優(yōu)以及對(duì)于噪聲點(diǎn)等問(wèn)題并沒(méi)有考慮在內(nèi),這些都是今后的研究重點(diǎn)。
參考文獻(xiàn):
[1]? ?蔡艷艷,宋曉東.針對(duì)非平衡數(shù)據(jù)分類(lèi)的新型模糊SVM模型[J].西安電子科技大學(xué)學(xué)報(bào),2015,42(5):120-124,160.
[2]? ?張銀峰,郭華平,職為梅,等.一種面向不平衡數(shù)據(jù)分類(lèi)的組合剪枝方法[J].計(jì)算機(jī)工程,2014,40(6):157-161,165.
[3]? ?Ma S.,Bai L.A face detection algorithm based on Adaboost and new Hear-like feature[C].IEEE International Conference on Software En-gineerning & Service Science,2017.
[4]? ?Chawla N.V.,Bwoyer K.W.,Hall L.O.,et al. SMOTE:synthetic minority over-sampling technique[J].Journal of Artificial Intelli-gence Research,2011,16(1):321-357.
[5]? ?Han H.,Wang W.Y.,Mao B.H. Borderline-SMOTE:a new over-sampling method in imbalanced data sets learning[C].Proceed-ings of the 2005 International Conference on Advances in Intelligent Computing - Volume Part I,2005.
[6]? ?陶新民,張冬雪,郝思媛,等.基于譜聚類(lèi)欠取樣的不均衡數(shù)據(jù)SVM分類(lèi)算法[J].控制與決策,2012,27(12).
[7]? ?Han H.,Wang W.Y.,Mao B.H.Borderline-SMOTE:a new over-sampling method in imbalanced data sets learning[C]//International conference on intelligent computing. Springer, Berlin, Heidelberg, 2005: 878-887.
[8]? ?董燕杰.不平衡數(shù)據(jù)集分類(lèi)的Random-SMOTE方法研究[D].大連:大連理工大學(xué),2009.
[9]? ?Z. Gu,Z.Zhang,J.Sun.Robust Image Recognition by L1-norm Twin-Projection Support Vector Machine[J].Neurocomputing,2017(223):1-11.
[責(zé)任編輯? ?白? ?雪]
