基于密度Canopy的評論文本主題識別方法
2023-11-09 01:37:44詹世源雷曉雨楊雨寬陳伯軒劉格格皇甫佳悅
河北科技大學學報 2023年5期
劉 濱 ,詹世源,劉 宇,雷曉雨,楊雨寬,陳伯軒,劉格格,高 歆,皇甫佳悅,陳 莉
(1.河北科技大學經濟管理學院,河北石家莊 050018;2.河北科技大學大數據與社會計算研究中心,河北石家莊 050018;3.河北政法職業學院圖書館,河北石家莊 050061;4.電子科技大學格拉斯哥學院,四川成都 610000;5.南京警察學院信息技術學院,江蘇南京 210000;6.中國人民解放軍空軍預警學院,湖北武漢 430019)
評論文本泛在于文化、演藝、消費等諸多平臺,利用自然語言處理領域的主題模型,可以挖掘出各類意見或觀點,輔以數據可視化技術[1-2],幫助產品或服務提供方準確識別社會反饋并優化品質。LDA[3](latent dirichlet allocation)、pLSA[4](probabilistic latent semantic analysis)等主題模型通常采用Gibbs采樣或變分推斷等算法,從高維稀疏的文本特征空間中挖掘潛在主題信息[5]。然而,評論文本通常長度短、語義稀疏、情感詞多且用詞較為隨意[6],致使LDA和pLSA的效果并不理想,出現模型泛化能力弱、主題詞可解釋性差等問題。針對短文本特征空間高維稀疏的特征,研究人員提出了BTM[7](biterm topic model)和DMM[8](dirichlet multinomial mixture model)等模型。BTM通過在短文本集合中構建詞對,緩解了稀疏性問題;而DMM模型假設每一篇短文本只有一個主題,且一篇文本中所有詞共享一個主題,使其適用于短文本處理[9]。然而,由于評論文本中詞匯共現信息不足,并且上述2個模型仍然以概率計算為核心,導致出現主題識別不準確、缺乏深層語義理解等問題。為此,阮光冊等[10]將深度學習模型與LDA主題模型相結合,提出融合Sentence-BERT和LDA的評論文本主題識別(SBERT-LDA)方法,取得了較好效果。然而,由于該方法使用K-means對特征融合后的向量進行聚類,且將LDA的主題數作為k值,因而存在可解釋性較差、主題一致性較低等問題;此外,由于K-means算法隨機選擇初始聚類中心,因而容易陷入局部最優解的問題。為此,本文提出基于密度Canopy的SBERT-LDA優化方法(SBERT-LDA-DC),即采用基于密度Canopy的改進K-means算法進行向量聚類,并通過實驗證明其效果。
1 相關研究
評論文本主題識別是指對互聯網和在線社交媒體上的評論文本數據,通過自然語言處理技術,從文本中提取關鍵信息并推斷出評論的主題[11]。BLEI[12]認為主題模型是一種統計方法,通過分析原始文本的詞語來發現貫穿其中的主題以及這些主題如何聯系,幫助人們理解文本文檔中的潛在主題。主題模型最早的代表為pLSA,隨后LDA主題模型對pLSA模型進行了貝葉斯改進,假設文檔中主題的先驗分布和主題中詞的先驗分布都服從Dirichlet分布。然而,網絡評論文本具有數量多、噪聲大、文本規范性不高、長度短等特點,導致pLSA和LDA模型在短文本處理方面效果不佳。研究人員在LDA基礎上,分別從參數推斷方式、模型假設、主題數量等角度提出了改進措施。BTM模型通過將2個詞語結合起來,組成詞對,建立了全局詞共現關系;DMM模型假設每個文本只包含一個潛在主題。這2種模型在一定程度上克服了短文本詞匯特征的稀疏問題,然而社交網絡短文本中的詞匯共現信息匱乏,DMM和BTM在進行主題推斷時,僅能分析語料本身提供的信息,效果并不理想。LDA在主題識別過程中無法考慮時間因素,而有的文本數據會隨著時間推移發生動態變化。例如關于某個熱點話題的討論,為了能夠對不同時間階段的文本主題進行追蹤,研究人員在LDA基礎上對時間維度進行拓展,具有代表性的是DTM[13](dynamic topic models)模型和TOT[14](topic over time)模型,這些模型能夠揭示主題演變過程,適合對新興主題生命周期特征進行動態分析。
深度學習作為機器學習領域的一個研究熱點,近年來在自然語言處理任務中取得了令人矚目的效果[15]。主題建模主要利用概率主題模型進行多文檔全局文本語義分析,這種方法需要綜合考慮各個文檔之間的語義關系,目前大多數采用的方案仍然是概率主題模型。為了解決文本詞匯共現信息不豐富或領域知識匱乏等問題,研究人員在傳統概率主題模型的基礎上,與先驗知識相結合,包括領域知識、詞向量等,取得了不錯的效果,其中比較具有代表性的就是將深度學習模型與LDA主題模型相結合進行文本主題識別。楊恒等[16]選擇人工智能領域的專利數據作為研究對象,通過使用Word2Vec擴展文本語料庫,進一步挖掘文本的語義知識,增強LDA主題模型的效果。顏端武等[17]利用新浪微博發布的數據,使用LDA文檔-主題分布特征和加權Word2Vec詞向量特征,構建微博短文本的融合特征,通過K-means算法對這些特征進行主題聚類。ZHOU等[18]提出了基于BERT-LDA聯合嵌入的主題聚類模型,該模型同時考慮上下文語義和主題信息,用于對財經新聞進行主題特征分析。ZHAO等[19]提出一種結合Word2Vec、基于主題的TF-IDF算法和改進的卷積神經網絡方法WTL-CNN對網絡新聞文本進行主題分類;國顯達等[20]使用Word2Vec獲取電商平臺在線評論的詞向量,并利用Gaussian LDA模型獲得評論的主題分布,再利用主題分布計算評論的相似度矩陣,運用聚類算法將相似的評論聚類在一起實現主題發現。綜上所述,將LDA與深度學習結合的主題模型,已經成為評論文本主題識別的重要應用技術,這些模型通過神經網絡更有效地捕捉上下文信息和文本數據的語義信息。可以看出,融合多個模型雖可以彌補單個模型的不足,提升整體模型的性能,但LDA結合詞嵌入Word2Vec的方法,將每個詞轉換為一個向量,忽略了上下文語境問題,而評論文本有時候一句話就代表著一個主題,因此容易造成主題語義連貫性不強的問題。李松繁等[21]采用BERT模型得到文本的句嵌入,在此基礎上對農業領域前沿研究進行主題識別。但是由于BERT句向量空間的各向異性,導致生成的詞向量在空間分布不均,而BERT模型生成的句向量是對詞向量的平均池化,因此不適合用在文本相似度以及文本聚類等無監督任務場景。基于此,劉晉霞等[22]通過Sentence-BERT預訓練模型獲取句表征向量,采用二分K-means算法進行聚類,實現了對專利的前沿主題抽取。
文獻[10]提出的SBERT-LDA方法,首先將Sentence-BERT得到的句子嵌入向量與LDA得到的概率主題向量進行拼接,然后使用自編碼器將2個向量連接起來,得到評論文本的特征向量,最后采用K-means算法對特征向量聚類,挖掘旅游景點評論數據中的主題。該方法通過將Sentence-BERT和LDA相結合,提升了評論文本主題的語義性,取得了較好的實驗效果。但是該方法由于在對文本特征向量聚類時使用的算法為K-means,因此存在聚類結果容易陷入局部最優解的缺陷[23],同時需要人工指定聚類個數,即該方法依據LDA主題建模中的主題數量確定算法中聚類簇的數量k,存在解釋性較低的問題。針對上述問題,本文提出了基于密度Canopy的SBERT-LDA優化方法(SBERT-LDA-DC),采用基于密度Canopy的改進K-means算法,對潛在空間的向量進行聚類,得到用戶評論文本的主題信息,從而避免了傳統K-means算法因人工設定k值和隨機初始化聚類中心引起的聚類結果不穩定以及容易陷入局部最優解的問題;同時,能夠更好地理解評論文本的語義特征,對主題的劃分也更加精準,具備更高的一致性。
2 基于密度Canopy的SBERT-LDA優化方法
2.1 主要模型
2.1.1 LDA主題概率向量
LDA是一種貝葉斯概率模型,包括文檔、主題、詞3層,通過分析文檔集,能夠得到文檔集中每篇文檔的主題概率分布并用其進行主題聚類或文本分類。LDA是一種典型的詞袋模型,即每篇文檔由一組詞構成,詞與詞之間沒有先后順序關系。此外,LDA假設一篇文檔可以包含多個主題,文檔中的每個詞都由某一個主題生成。給定一個文檔集合,α是主題-文檔分布的先驗參數,它控制了每個文檔中主題的分布情況。具體來說,α決定了每個文檔包含哪些主題以及各個主題在文檔中的比例。β是主題-詞匯分布的先驗參數,它控制了每個主題中詞匯的分布情況,決定了每個主題包含哪些詞匯以及各個詞匯在主題中的比例。在文檔層中,N為一篇文檔中特征詞數量,θ為文檔對應的主題向量,在特征詞層中w和z分別為指定的特征詞與主題[24]。LDA主題模型聯合概率表示如式(1)所示:
(1)
2.1.2 Sentence-BERT句子嵌入向量
Sentence-BERT是REIMERS等[25]基于BERT模型提出的預訓練模型,是一種基于BERT的句子向量化方法,通過對比學習得到更好的句子向量表示。Sentence-BERT主要解決BERT語義相似度檢索的巨大時間開銷和其句子表征不適用于非監督任務如聚類、句子相似度計算等問題。與Word2Vec和BERT模型相比,Sentence-BERT更適用于文本相似度度量、文本聚類等任務。Sentence-BERT使用孿生網絡結構,通過孿生網絡獲取句向量表示,即將句子對輸入到參數共享的2個BERT模型中,在輸出結果上增加池化操作來獲得固定長度的句向量。Sentence-BERT的提出者在文中定義了3種池化策略:1)直接使用CLS位置輸出的向量作為整句話的句向量;2)平均池化策略,將通過BERT模型得到的句子中所有的字向量的均值向量作為整句話的句向量;3)最大池化策略,將通過BERT模型得到的句子中所有的字向量對應位置提取最大值作為整句話的句向量,之后將2個句向量進行相似度比較,Sentence-BERT模型的目標函數是最大化正樣本對的相似度,并最小化負樣本對的相似度,其模型結構如圖1所示。
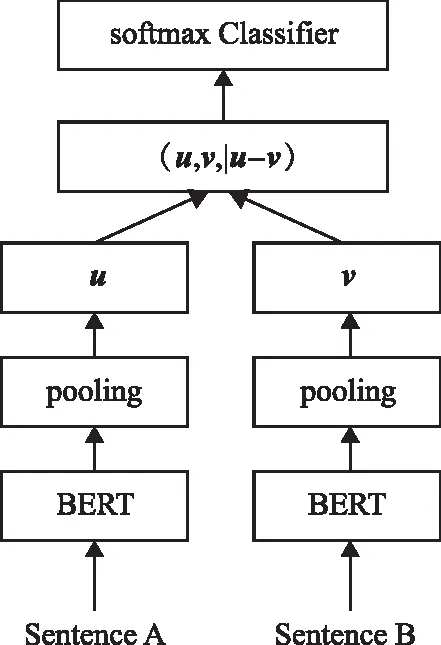
圖1 Sentence-BERT模型結構Fig.1 Sentence-BERT model structure
針對文本分類任務,Sentence-BERT模型的目標函數將句子嵌入u和v以及差向量|u-v|三者拼接起來,然后與可訓練的權重向量Wt∈R3n×k相乘,見式(2):
o=softmax(Wt(u,v,|u-v|))。
(2)
最終優化目標通過最小化softmax的交叉熵損失函數實現,其中n是句子嵌入的維數,k是標簽的數量。
2.1.3 特征向量拼接
LDA主題模型和Sentence-BERT模型在向量化表達評論文本時都有各自的側重點,雖然LDA的主題分布向量可以全局描述文本特征,但受詞袋模型的限制,無法挖掘深層語義信息。相比之下,Sentence-BERT模型可以完成對評論文本全局語義信息的特征提取,給2個向量分別賦予不同的權重,得到拼接向量:
V={w1*Vt;w2*Vs}。
(3)
式中:w1表示LDA的主題分布向量的權重值;Vt表示LDA的主題分布向量;w2表示Sentence-BERT句嵌入向量的權重值;Vs表示Sentence-BERT句嵌入向量,“;”表示向量連接符號。此時得到的拼接向量處于稀疏的高維空間,向量維度存在較高的相關性,因此使用自編碼器將向量映射到一個低維的潛在空間,得到最終的融合特征向量。
2.1.4 基于密度Canopy的改進K-means算法
為了提高K-means算法的準確性和穩定性,解決最合適的簇數K和最佳初始種子的確定問題,ZHANG等[26]提出了一種基于密度Canopy的改進K-means算法。實驗表明,與傳統K-means算法、基于Canopy的K-means算法、半監督K-means++算法相比,基于密度Canopy的改進K-means算法取得了更好的聚類結果,并且其對噪聲數據不敏感。該算法的具體流程如下:計算樣本數據集的密度、簇內平均樣本距離和簇間距離,選擇密度最大采樣點作為第一聚類中心,將密度簇從數據集中剔除,定義樣本密度ρ(i)、簇內樣本間平均距離a(i)的倒數、簇間距離的乘積作為權重乘積w,其他初始種子由剩余數據集中的最大權重乘積確定,直到數據集為空。
對于給定的數據集D={x1,x2,…,xn},數據集D中所有樣本元素的平均距離定義如式(4)所示:
(4)
數據集D中樣本元素i的密度定義如式(5)所示:
(5)
ρ(i)是滿足其他樣本到i點的距離小于MeanDis(D)條件的樣本數。滿足條件的樣本形成一個簇,簇內樣本間平均距離定義如式(6)所示:
(6)
簇間距離s(i)表示樣本元素i與具有較高局部密度的另一個樣本元素j之間的距離,簇間距離s(i)的定義如式(7)所示:
(7)
權重乘積w的定義如式(8)所示:
(8)
2.2 方法框架
圖2給出了SBERT-LDA的方法流程圖。首先對評論文本集進行數據預處理,使用Sentence-BERT生成句子的嵌入向量,通過LDA主題模型獲得文本主題向量,再將2個向量進行連接,構建評論文本向量,最后使用K-means聚類方法提取類簇的主題。
本文提出的SBERT-LDA-DC方法流程如圖3所示。對SBERT-LDA方法中的評論文本向量聚類方法進行改進,采用基于密度Canopy的改進K-means算法,解決了K-means算法需要指定聚類個數和隨機選擇初始聚類中心、結果容易陷入局部最優解的問題。

圖3 SBERT-LDA-DC方法流程圖Fig.3 Flowchart of the SBERT-LDA-DC method
SBERT-LDA-DC方法由5個部分組成:1)對評論文本數據集進行預處理,包括文本清洗,去掉非評論的噪聲文本以及文本中無意義的重復詞語,對清洗后的文本依次進行分詞、去停用詞處理;2)文本向量化,首先利用LDA模型對文本預處理后得到的語料庫進行建模,得到每個評論文本的主題概率分布,即評論文本的主題向量,再通過Sentence-BERT模型得到評論文本的句嵌入向量;3)向量連接,對評論文本的主題向量和句子嵌入向量賦予不同權重,再將得到的向量連接;4)由于拼接向量處于稀疏的高維空間,向量維度存在較高的相關性,因此通過自編碼器將拼接向量映射到低維潛在空間,得到重構之后的評論文本特征向量;5)通過基于密度Canopy的改進K-means算法對特征向量進行聚類,從聚類后的評論文本簇得到主題詞。相較于傳統K-means算法,基于密度Canopy的改進K-means算法可以自適應選擇聚類中心點和聚類數目,解決K-means算法由于隨機選取初始聚類中心容易陷入局部最優的問題。
3 實驗過程及討論
3.1 數據集
本研究從大麥網(www.damai.cn)爬取了舞劇《永不消逝的電波》的4 146條用戶評價,時間跨度為2019年4月至2023年5月。首先在數據預處理環節篩選出1 852條字數在5~60之間的評論文本(通過查看評論發現,字數超過60時的大多數評論內容會涉及劇情的討論,導致主題過于分散,因此將60設置為上限);然后對評論中出現的無意義重復文本,例如“好看好看好看”“震撼震撼震撼”等進行整合處理,即將多個重復詞語替換為一個;再對評論文本中的同義詞進行處理,如演員“朱潔靜”在評論文本中的稱謂表現為“朱姐”“朱老師”“朱潔靜老師”等,本研究將其統一映射為“朱潔靜”,得到的評論文本長度直方圖如圖4所示;最后使用Jieba分詞工具包對評論文本進行分詞,使用停用詞表去除停用詞,獲得評論文本語料庫。
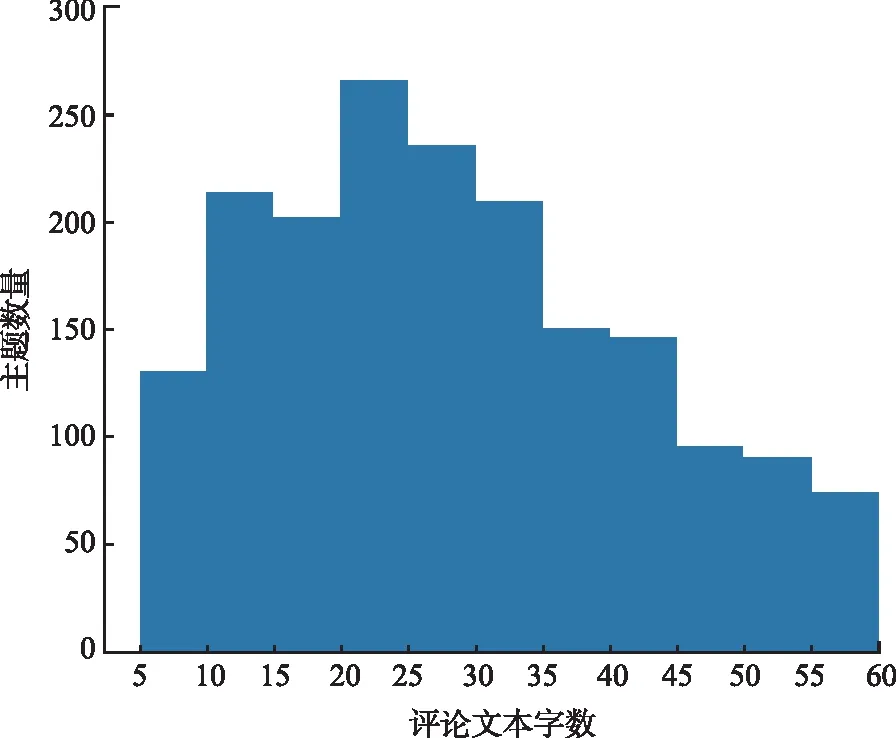
圖4 評論文本長度直方圖Fig.4 Comment text length histogram
3.2 評論文本向量化
本文使用支持中文文本句嵌入構建的Sentence-BERT預訓練模型“distiluse-base-multilingual-cased-v1”,該模型下載自HuggingFace網站。通過該模型獲得評論文本的特征向量,其可以將句子映射到512維密集向量空間,使用該模型對1 852條評論文本進行向量化處理,可以得到1 852×512維度的矩陣向量。采用LDA獲取評論文本的主題概率向量。為了獲取最適宜的評論文本主題數量,本研究使用主題一致性指標CV(coherence value)來評估聚類效果的好壞。由圖5可以看出,隨著主題數的增加,一致性結果呈現波動上升的趨勢。語義一致性在一定范圍內最大時,確定的主題數挖掘出的主題可以較好地表征數據集的主題。根據計算結果,最優主題數分別為6,10,12,14和17個,由于評論文本數據集的文本數量較小,因此當主題數為6時,主題的表達效果更好,綜合考慮SBERT-LDA-DC模型生成主題群效果和主題可解釋性,實驗中選擇主題數k=6,采用LDA對評論文本進行主題建模,獲得每個評論文本的主題概率向量,即每個評論文本對應一個6維的向量表示。
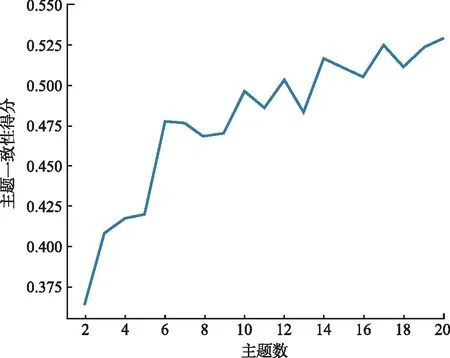
圖5 主題一致性隨主題數量的變化情況Fig.5 Topic consistency changes with the number of topics
在分別獲得評論文本的句子嵌入向量以及主題概率向量后,對其賦予不同權重,其中句子嵌入向量權重為1,主題概率向量權重為5。將賦予權重后的向量進行加權拼接,由于拼接向量處在稀疏的高維空間,因此使用自編碼器對拼接向量進行無監督學習,使用訓練好的自編碼器對拼接向量進行特征壓縮,將拼接向量從518維壓縮至32維。
3.3 評論文本主題識別
通過自編碼器將評論文本句子嵌入向量和主題概率向量的加權拼接向量壓縮得到低維向量,即每個評論文本對應一個32維向量表示。為了對評論文本進行主題識別,需要對評論文本向量矩陣進行聚類分析,之后從聚類結果中提取上下文主題信息。對于向量聚類,本研究采用基于密度Canopy的改進K-means算法,與K-means算法相比,該算法對噪聲數據不敏感且擁有更好的聚類效果,解決了傳統K-means算法需要人工指定聚類個數K和最佳初始種子的問題。實驗使用該聚類算法對評論文本向量進行聚類,即先通過密度Canopy算法對評論文本向量進行預聚類,將獲得的最優值k=7以及對應的7個初始聚類中心作為K-means算法的輸入參數,然后按照K-means算法流程進行聚類,最終將評論文本語料庫聚合成7個類簇。
3.4 實驗結果
使用UMAP降維算法對獲得的7個類簇的評論文本向量降維,將數據降維至二維進行可視化展示,如圖6所示。
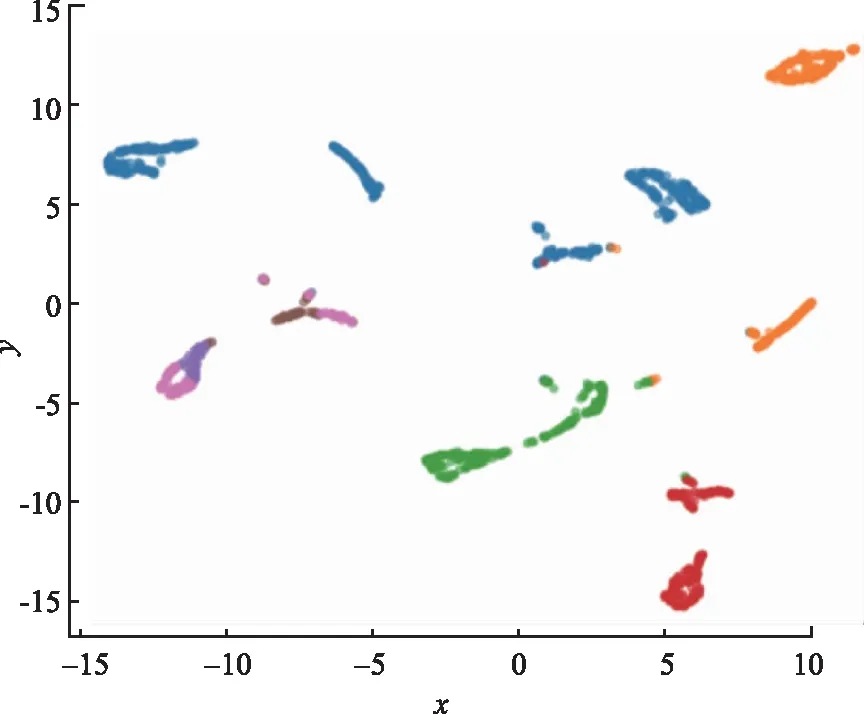
圖6 7個類簇分布的UMAP圖Fig.6 UMAP of 7 clusters distribution
從圖6可以看出,評論文本向量聚類得到的類簇不同主題之間邊界清晰,同一主題內凝聚,進一步驗證了SBERT-LDA-DC在短文本具體聚類任務上具有較好的效果。
本研究在模型識別出的7個類簇的基礎上,將主題詞設置為8個,各個類簇的主題信息如表1所示。
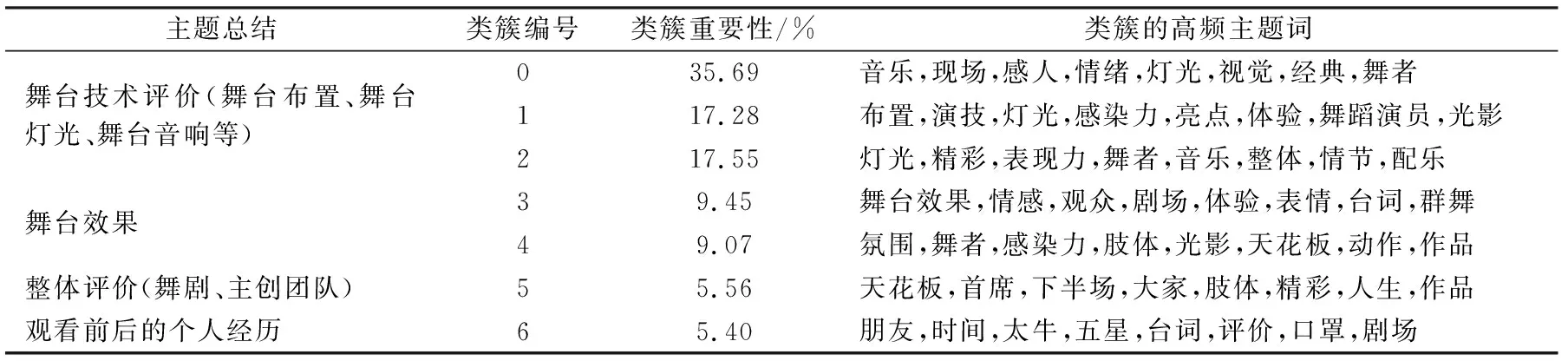
表1 各個類簇的主題信息Tab.1 Topic information for each cluster
由表1可以看出,用戶對舞劇《永不消逝的電波》的評論主題主要分為舞臺技術評價、舞臺效果、整體評價以及觀看前后的個人經歷4個方面。其中觀眾對于舞臺技術評價的評論最多,“音樂” “布置” “燈光”等高頻詞匯反映了用戶對于舞臺技術的使用及其對觀看體驗影響的看法。例如:“舞臺裝置、音樂燈光把氣氛烘托得挺不錯的” “怎么有這么好看的舞劇?舞者、燈光、音樂把控得非常好”等。關于“舞臺效果”主題的評論,“舞臺效果” “情感” “氛圍” “感染力”等詞,說明觀眾對于舞劇《永不消逝的電波》的主創團隊所表現出的舞臺效果有比較深刻的印象,如“很震撼,舞蹈很美,舞臺效果很好,音樂非常好聽,有幾段情節特別感人” “很喜歡,氛圍很好,感染力十足!”。占比較少的主題為觀眾對于舞劇的整體評價,如“完美的體驗,天花板級別的舞劇” “首席組的電波真的太好看了”,這類評論情感較為強烈,表達了用戶的滿意程度。最后是關于觀眾觀看舞劇前后的個人經歷等,與舞劇本身的內容評價相關性較小。例如:“跟朋友看完以后,會一起聊幾天的那種美” “兩年前一直想看,終于等到了合適的時間、合適的地點來看了”。
3.5 實驗對比
一致性度量是一種評估主題質量的方法,其根據主題的可理解性進行評估,通常應用于通過主題模型計算得出的主題。主題一致性度量方法通常基于詞語之間的共現關系和相似度進行計算。Gensim提供了4種計算主題連貫性的方法,即C_V,C_UCI,C_NPMI和U_Mass。這些方法能夠評估主題一致性,并給出一致性得分。一致性得分越高,表示主題模型能夠更好地理解評論文本的語義特征,對主題的劃分也更加精準。與其他廣泛使用的主題一致性度量方法相比,C_V Coherence方法表現更優,因此本研究采用該指標對不同方法計算出的主題質量進行了評估。
表2給出了使用SBERT-LDA(使用K-means算法進行文本特征向量聚類)、SBERT-LDA-K-means++(使用K-means++算法進行文本特征向量聚類)和SBERT-LDA-DC(使用基于密度Canopy的改進K-means算法進行文本特征向量聚類)3種方法的對比情況。實驗使用Gensim包的Coher-enceModel來計算主題一致性,采用C_V方法進行計算,結果如表2所示。
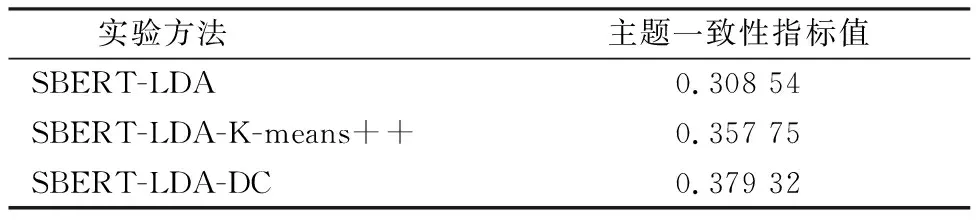
表2 實驗結果Tab.2 Experimental results
由表2可見,本文方法在數據集上得到的主題一致性指標值最高,為0.379 32,相較于SBERT-LDA方法,本文一致性指標值提升了22.9%;相較于“SBERT-LDA-K-means++”方法,一致性指標值提升了6.0%。由此可見,本文方法在無需指定聚類個數的同時,在主題識別效果上也要優于其他2種方法,從而驗證了本文所提方法的有效性。
4 結 語
本文針對SBERT-LDA方法存在的不足,提出了SBERT-LDA-DC方法,通過采用密度Canopy改進K-means算法,避免了傳統K-means算法因需要人工設定k值和隨機選擇初始聚類中心引起的聚類結果不穩定以及容易陷入局部最優解的問題,使聚類結果盡可能接近全局最優解。通過對比實驗可以看到,本文方法在主題一致性上要優于使用K-means對特征向量聚類的SBERT-LDA方法以及SBERT-LDA-K-means++方法。
本文方法能夠有效挖掘評論文本中具有語義信息的關鍵主題詞,識別評論文本中包含的主題信息。相較于K-means算法,基于密度Canopy的改進K-means算法計算的復雜度更高,因此需要的計算資源也會更多。此外,可以使用評論文本對Sentence-BERT模型進行微調,使其更好地理解句子之間的語義關系,進一步提高評論文本主題識別效果。未來將在模型復雜度、微調Sentence-BERT模型方面進行改進,進一步提高評論文本主題識別的效果和效率。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
