大數據視域下思政課教育教學過程中的深度學習知識追蹤研究
2023-11-20 04:06:52王全蕊任建京韓菲謝鵬超欽佳燕
互聯網周刊 2023年20期
王全蕊 任建京 韓菲 謝鵬超 欽佳燕
摘要:通過借助深度學習技術對思政課教學過程中學習者進行建模分析,達到知識追蹤的目的。考慮到每個學習者的能力和其他外力因素的影響會導致學習者的思政知識水平不一致、輸入數據中存在差異性,在深度知識追蹤中使用自然聚類算法對學習者的思政知識水平進行動態捕捉和聚類操作,并且在貝葉斯知識追蹤模型中引入學習者學習情況分類標簽,使得模型在學習過程中重點關注以往特定時間段內的信息,而不是只依靠上一時刻的輸出狀態,由此提高對學習者思政課知識點掌握程度的預測結果。
關鍵詞:大數據;思政教育;深度學習;知識追蹤
引言
基于深度學習的知識追蹤方法,為學習者的思政教育認知程度和思政知識掌握情況進行動態追蹤評估提供了一種有效的手段。通過該方法的應用,教師可以更加精準地了解學生的學習狀況,制定個性化的教學策略,提高思政教育的質量和效果。同時,學生也可以通過該方法獲得及時的學習反饋和指導,提升學習效果和學習成績。
1. 知識追蹤研究現狀
隨著教育信息化的不斷推進和“互聯網+”課堂教學的迅猛發展,思政課在線教學已成為高校思想政治教育的重要手段,同時也產生了大量的在線教學數據。許多教育研究者們試圖采用數據挖掘、人工智能等信息技術來獲取學習者的思政認知情況。知識追蹤模型為教育研究者預測學習者知識狀態提供了便捷的途徑,也是教育數據挖掘領域的研究熱點[1]。
知識追蹤作為智能輔導體系的一個重要組成部分,目前被廣泛應用于各個在線教育平臺和智能輔助系統。貝葉斯知識追蹤模型是目前最流行的知識追蹤模型之一,但由于貝葉斯知識追蹤所使用的隱馬爾可夫模型假設當前題目和上一次答題的狀態有所聯系,這就導致貝葉斯知識追蹤模型難以模擬較長的序列[2]。因此學者將具有強大特征提取能力的深度學習應用于知識追蹤領域,能很好地解決該問題,同時也能捕捉到更復雜的學習者的知識表征,還可以用來發現知識成分之間的關聯信息[3]。
隨著深度學習技術不斷加強,基于深度學習的知識追蹤研究已經成為知識追蹤領域的一個重要分支,并且取得了豐碩的成果。由Piech Chris(2015)[4]等學者提出的深度知識追蹤模型,被看成深度學習知識追蹤領域中取得的開創性成果。此后,學者開始致力于研究深度知識跟蹤學習的模型改進。Williams(1990)[5]等人提出在連續采樣時間內運行完全遞歸網絡的梯度跟蹤學習算法,可對學習者的輸入數據進行降維操作,實驗表明在一定程度上能提高深度學習知識追蹤模型的效果。
2. 知識追蹤問題描述
2.1 知識追蹤定義
知識追蹤的任務就是根據學習者對相關練習的歷史學習記錄,預測下一次學習者練習交互的正確率。知識追蹤的任務可以被形式化為有監督的序列學習任務,使用Xt= (et, at) 表示學習者在t時刻對et所表示的練習給出的答案at。雖然將學習者學習交互活動Xt用顯式表示出來,但是學習者對知識概念的掌握狀態卻是內隱的,很難準確地對學習者實際學習狀態進行量化,因此可以將知識追蹤任務轉換為預測學習者將來練習的正確率。
2.2 基于深度學習的知識追蹤模型
為了改進深度知識追蹤,學者們提出了許多基于深度知識追蹤的擴展模型。深度知識追蹤模型的改進和擴展,需要打破該模型對學習者練習環節中引入文本信息、練習難易程度、概念層次以及概念之間的依賴性等先決條件的限制。受記憶增強神經網絡的啟發,學者們采用補充外部記憶結構來改進深度知識追蹤模型,由此能更好地追蹤學習者對復雜概念的掌握程度。其中使用鍵值記憶元來表示學習者學習知識狀態的KVMN模型,比深度知識追蹤的隱藏變量具有更大的表達能力。由于許多研究人員對深度知識追蹤的可解釋性提出了批評,因此學者們嘗試使用其他方法來解決該問題。最終學者發現模型的固有可解釋性可以通過構建學習模型來實現,該學習模型將可解釋性直接包括到特定模型結構中,以提高深度知識追蹤的可解釋性。
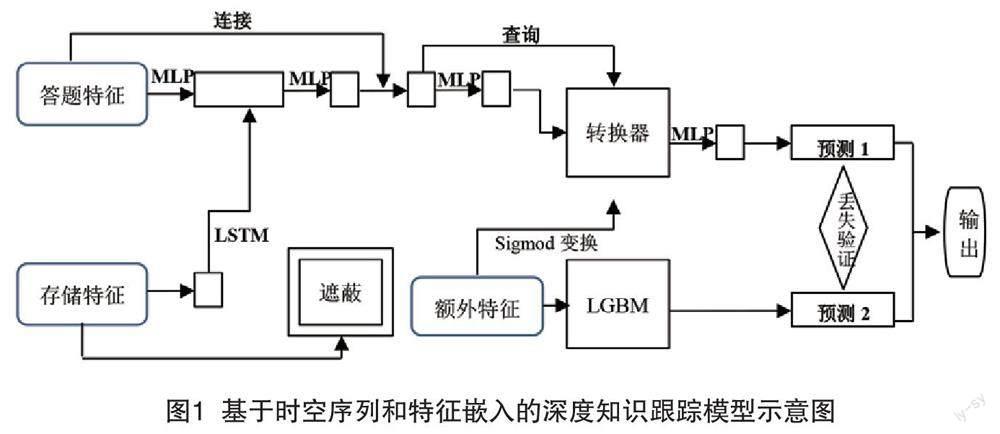
3. 基于時空序列和特征嵌入的深度知識跟蹤模型SSFE-DKT
3.1 模型框架
基于時空序列和特征嵌入的深度知識跟蹤模型包括三個部分:采用卷積神經網絡提取學習者答題序列的空間特征的部分、中間數據處理的部分、通過長短期記憶網絡提取學習者答題過程中的時間和空間特征的部分。如圖1所示。該模型直接使用LSTM從學習者的答題歷史中提取序列的時間特征,該特征表示為學習者的隱藏知識狀態,然后輸出下一段時間的預測結果。SSFE-DKT模型從兩個方面進行了改進。一是從序列特征中提取的信息數據不只包含原始學習者答題記錄,還包括使用卷積神經網絡從學習者答題序列中提取的空間特征數據。二是模型中時間特征學習結構采用LSTM可以學習正向學習者互動答題序列中的特征,由此既能夠預測學習者的未來表現還能兼顧他們的過去表現,這使得在分析學習者在每個時間步驟的知識掌握時能夠獲得更準確的判斷。
3.2 特征分類
嵌入的特征分為三類:基本特征、互動特征和其他特征。基本特征主要指在線教學平臺已加入課程的學習者的基本信息、課程相關知識點信息、課程發布的練習題信息;互動特征主要指學習者學習過程中的學習信息,由于此類特征具有動態性,因此需要嵌入時間信息,即設定時間跨度;除了基本特征和互動特征,還提取了其他具有一定輔助的特征,這些特征中隱含了學習者的答題前后序列信息,有助于提高學習者對其答題行為的可解釋性和可預測性。
4. 實證分析
4.1 數據來源和預處理
4.1.1 數據來源
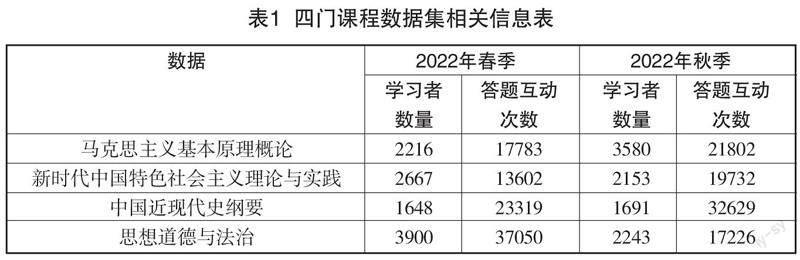
本研究的數據來源于在線教育平臺學習者選修的四門思政課,包括“馬克思主義基本原理概論”“新時代中國特色社會主義理論與實踐”“中國近現代史綱要”以及“思想道德修養和法律基礎”。學習者在2022年春季(數據集記為D)、2022年秋季(數據集記為D)兩個自然學期的答題歷史數據,共有10431人次參加學習。每個數據集的統計屬性分別為學習者用戶數量和答題互動次數,如表1所示。
4.1.2 預處理
首先,對原始數據集D和D進行清洗,若某條數據的缺失值比例大于等于50%,則去除該條數據,否則保留該條數據,并進行缺失值填充。其次,去除兩個數據集中的異常值,對于同一個學習者ID的同一道練習題的答題次數高于10次的,視為異常數據。再次,對兩個數據集進行歸一化處理。最后,對同一學習者的多條重復數據進行合并,根據學習者ID進行身份識別,得到同時學習四門課程的學習者用戶共有3711名,且有效答題次數為12620。
4.2 實驗驗證及分析
4.2.1 數據訓練實驗
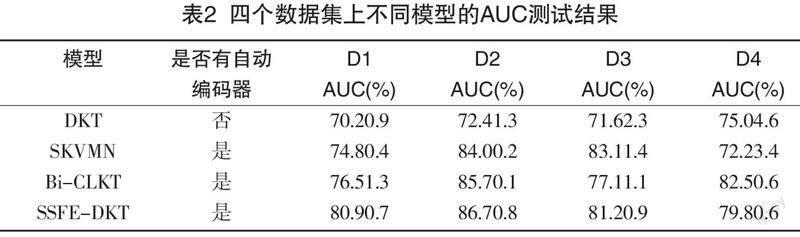
本研究使用基于時空序列和特征嵌入的深度知識跟蹤模型在處理后的2022年春季四門課程數據D和2022年秋季四門課程數據D'上進行訓練測試。采用將數據集隨機按照8:2比例劃分為訓練集和測試集,然后使用訓練集來生成模型,再用測試集來測試模型的AUC和R2的值。模型使用期望最大化將參數擬合到訓練集,所有模型使用相同的ad-hoc初始參數值集:p(Lo)=0.20,p(T)=0.10,p(G)=0.10、p(S)=0.15。由于評估時數據僅限于有限數量的計算資源,因此將EM迭代次數設置為5,以便在分配的時間段內進行交叉評估。使用SSFE-DKT模型對數據進行訓練,同時也在其他知識追蹤模型如DKT、SKVMN、Bi-CLKT上分別進行訓練,模型的AUC和R2測試結果分別如表2和表3所示。
4.2.2 實驗結果分析
通過四種知識追蹤模型對數據進行訓練測試,在學習者層面進行了5倍的交叉驗證,使用曲線下面積作為度量,同時也使用R2用來描述數據對模型的擬合程度的好壞。根據數據結果顯示,具有合并特征的SSFE-DKT模型優于原始DKT模型。由于SSFE-DKT模型可以捕捉學習者提交的多個練習之間的關系,因此在多粒度上AUC有顯著的提高。在D2數據集上,添加時間序列和正確性的交叉特征后,AUC值從80.9提高到86.7,R2值從0.373增加到0.416。在D3數據集上,AUC值從四種模型的均值76.2增加到81.2,R2值從0.132增加到0.141。事實上,如果只結合時間序列和正確交叉特征,則輸入層的維度僅增加4×2=8(時間×正確性),因此與原始DKT模型相比,SSFE-DKT模型的運行效率更高,且預測效果也有所提高,即如果學習者在上一次提交中的答案已經正確,他們更有可能做出正確的回答。
結語
越來越多的學習者通過在線教育平臺進行學習,由此產生了大量的學習和互動數據,促進了人工智能輔助教育系統的快速發展。在學習者互動數據急劇增長的同時,需要不斷優化學習者的認知判斷和學習策略,以提高教育系統的整體效率。因此人工智能輔助的教育應用,如基于深度學習的知識追蹤,獲得了越來越多的關注。由于深度學習尚未解決可解釋性問題,因此深度知識追蹤的三種方法即嵌入、損失函數限制和新結構都有自身的缺點。未來對于知識追蹤的研究可以借鑒這三種方法,在嵌入學習信息的基礎上通過設置損失函數自適應保留和丟失數據,最后結合知識圖譜這種圖模型來直觀體現學習者學習過程中知識的遷移,從而實現知識追蹤的目的。
參考文獻:
[1]梁琨,任依夢,尚余虎,等.深度學習驅動的知識追蹤研究進展綜述[J].計算機工程與應用,2021,57(21):41-58.
[2]李夢琦.基于深度學習的學習者知識追蹤方法研究[D].長春:東北師范大學,2020.
[3]劉鐵園,陳威,常亮,等.基于深度學習的知識追蹤研究進展[J].計算機研究與發展,2022,59(1):81-104.
[4]Piech C,Spencer J,Huang J,et al.Deep Knowledge Tracing[J].Computer Science, 2015,3(3):19-23.
[5]Williams RJ, Zipser D.A Learning Algorithm for Continually Running Fully Recurrent Neural Networks[J].Neural Computation,1990:270-280.
作者簡介:王全蕊,碩士研究生,講師,研究方向:智慧教育、知識圖譜構建。
基金項目:2023年河南省科技攻關項目:教育大數據視域下基于學習反饋自適應的知識圖譜構建(編號:232102211083);河南科技學院2023年教師教育課程改革研究項目:基于智慧教育理念的中學線上線下混合式校本課程開發與實踐研究(編號:2023JSJY10);河南科技學院2023年第一批教育教學改革研究與實踐項目:智慧教育趨向下的融合式教學實踐研究——以《操作系統》課程為例(編號:2023YG04)。
猜你喜歡
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
科教導刊·電子版(2016年26期)2016-11-21 08:25:44
知音勵志·社科版(2016年9期)2016-11-09 22:27:03
軟件導刊(2016年9期)2016-11-07 22:20:49
知音勵志·社科版(2016年8期)2016-11-05 02:56:48
知音勵志·社科版(2016年8期)2016-11-05 02:35:58
軟件工程(2016年8期)2016-10-25 15:47:34
科技視界(2016年20期)2016-09-29 10:53:22
