智能微調的混合動力汽車能量管理策略研究
2022-06-18 02:13:10賴晨光龐玉涵楊小青張?zhí)K男黃志華
重慶理工大學學報(自然科學) 2022年5期
賴晨光,龐玉涵,胡 博,楊小青,張?zhí)K男,黃志華
(1.重慶理工大學 汽車零部件制造及檢測技術教育部重點實驗室, 重慶 400054;2.重慶理工大學 車輛工程學院, 重慶 400054)
0 引言
隨著社會和科技的發(fā)展,能源危機和環(huán)境污染問題日趨嚴重,在此環(huán)境下新能源汽車迅速發(fā)展[1]。混合動力汽車是新能源汽車的一種,動力系統(tǒng)包含2種或多種動力裝置,最常見的組合是發(fā)動機與電動機,在保障續(xù)航里程的同時,還能減少油耗和降低排放[2]。
混合動力汽車動力系統(tǒng)的好壞主要取決于能量管理策略,好的能量管理策略能夠在滿足動力性的前提下同時減少油耗。如圖1所示,目前的控制策略主要分為3種[3]:基于規(guī)則、基于優(yōu)化和基于學習。基于規(guī)則的控制策略是基于啟發(fā)式、直覺、人類專業(yè)知識或者數(shù)學模型而設計的,并且通常不需要預先定義的駕駛循環(huán)的先驗知識,但需要花費大量的時間進行人為調參,適用范圍受到行駛工況的限制,已有很多學者將其應用于混合動力汽車[4-6]。基于優(yōu)化的控制策略由于適應好、調參簡單等特點受到諸多學者的關注。Serrao[7]對動態(tài)規(guī)劃[8]、龐特里亞金最小原理[9]和等效能耗最小策略[10]3種已知的優(yōu)化算法進行了比較分析。全局最優(yōu)的動態(tài)規(guī)劃(dynamic programming,DP)由于需要知道全局信息才能求解,所以在實際應用中存在一定的局限性,通常作為其他策略的比較基準[11]。國內外許多學者將龐特里亞金最小原理(Pontryagin’s minimum principle,PMP)應用于混合動力汽車能量管理問題上,均取得了不錯的控制效果[12-14]。PMP解決的是離散問題,學者們在此基礎上提出了等效能耗最小策略(equivalent consumption minimization strategy,ECMS),用于解決連續(xù)的問題[15]。隨著人工智能技術的發(fā)展,基于學習的方法也廣泛應用于混合動力汽車能量管理問題的研究。Liu等提出了基于Q-learning和Dyna算法的混合動力車輛自適應能量管理策略,并取得優(yōu)于基于規(guī)則能量管理策略的控制效果[16-17]。Sciarretta等[18]提出了一種基于深度強化學習的能量管理策略,可以學習直接從狀態(tài)中選擇動作,而無需任何預測或預定義規(guī)則,并在仿真環(huán)境中驗證策略在燃油經(jīng)濟性方面的有效性。

圖1 混合動力汽車能量管理策略分類框圖
目前國內外利用深度強化學習算法強大的自學習能力去優(yōu)化已有的控制策略的研究較少,往往是通過深度強化學習算法直接控制,但是控制效果不是很理想,需要大量的學習時間。李家曦等[19]利用DDPG算法直接調整ECMS的等效因子,取得了接近A-ECMS的控制結果,在油耗上也有所改善。陳渠等[20]將DP算法與機器學習相結合,提出了一種全新的控制策略,該策略的燃油經(jīng)濟性較基于規(guī)則的能量管理策略有明顯的提升。
基于上述的一些研究,結合深度強化學習算法與自適應等效能耗最小策略,提出了基于DDPG微調的能量管理策略。利用DDPG考慮更完善的汽車狀態(tài)來微調A-ECMS輸出的等效因子,實現(xiàn)電池SOC保持,整車油耗降低。
1 混合動力汽車模型
P2構型混合動力汽車的電機、發(fā)動機和變速器位于同一軸線上,通過對離合器與P2模塊的協(xié)同控制可以讓汽車在純發(fā)動機、純電動、能量回收、加速助力4種模式下工作。圖2為P2混合動力汽車結構示意圖。搭建整車仿真模型的參數(shù)如表1所示。
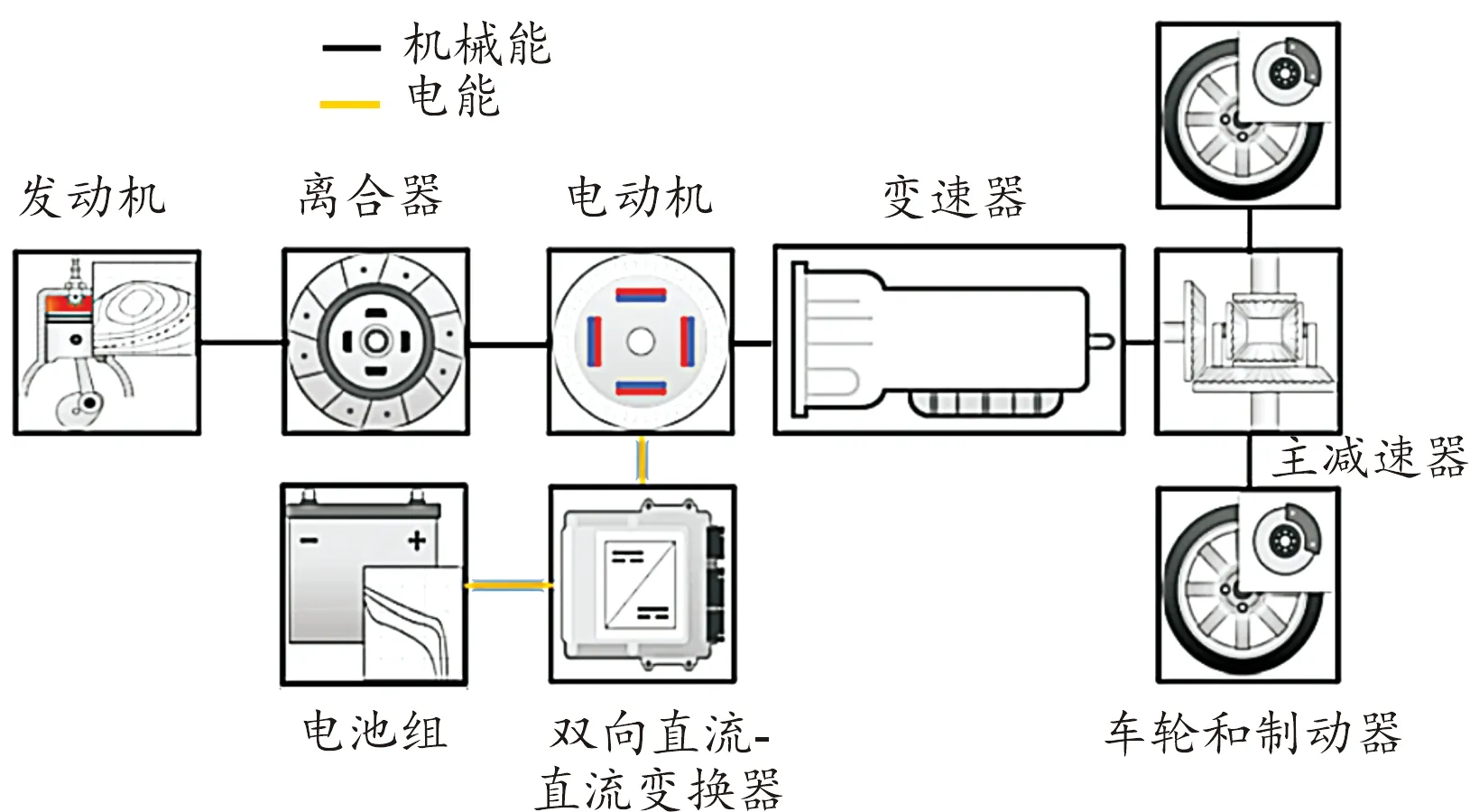
圖2 P2混合動力汽車結構示意圖
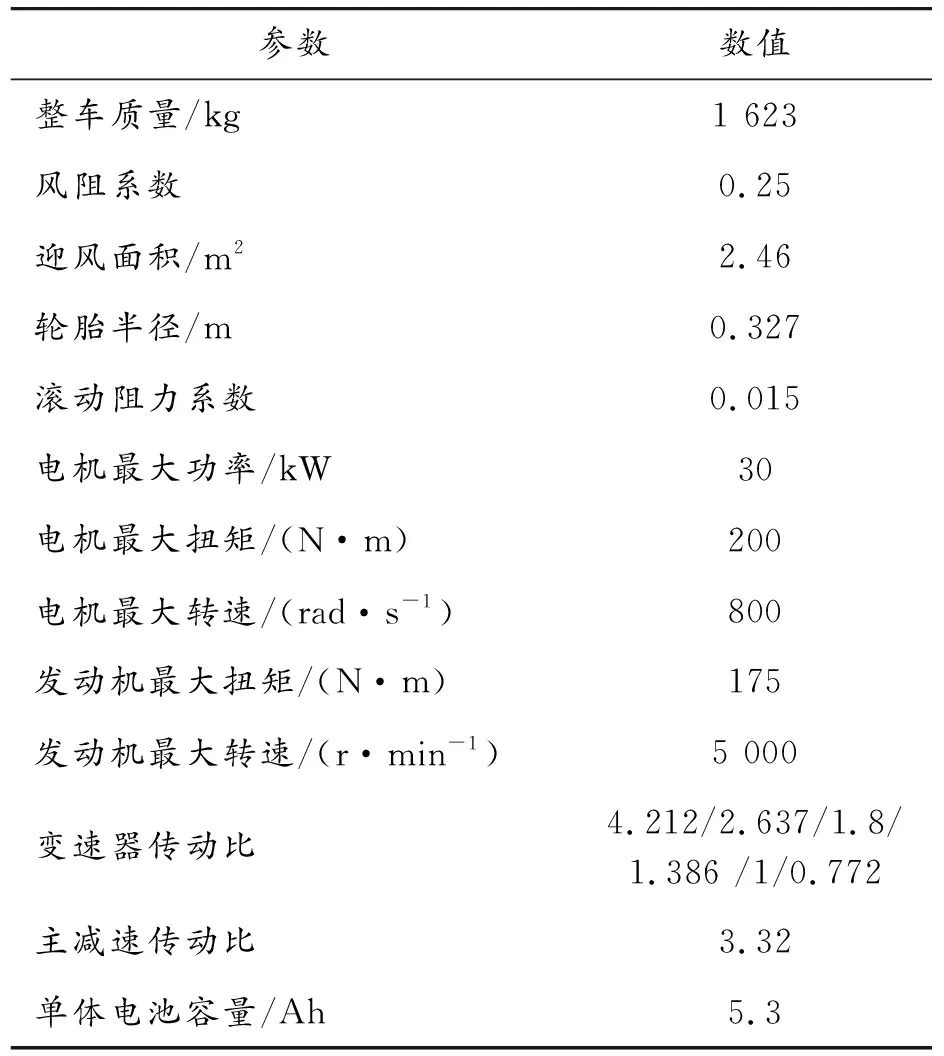
表1 整車及動力部件參數(shù)
1.1 動力總成模型
在給定車速v后,需求功率Prep由所需克服的道路滾動阻力Ff、空氣阻力Fw、坡度阻力Fj、加速阻力Fi通過以下公式計算得到:
Prep=(Ff+Fw+Fi+Fj)v
(1)
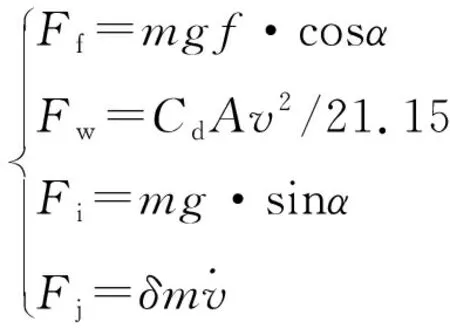
(2)
式中:v為車速;m為車輛質量;f為滾動阻力系數(shù);α為道路的坡度;g為重力加速度;Cd為空氣阻力系數(shù);A為迎風面積;δ為質量系數(shù)。
混合動力汽車的需求功率由發(fā)動機和電池共同提供:
Prep=(Peng+Pbatηm)ηT
(3)
式中:Peng為發(fā)動機輸出功率;Pbat為電池功率;ηm為電動機效率;ηT為變速器和車軸的效率。
1.2 發(fā)動機建模
發(fā)動機的燃料消耗與發(fā)動機輸出扭矩Peng和發(fā)動機轉速neng有關,所以燃料消耗率表示為:
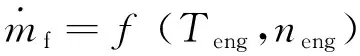
(4)
汽車發(fā)動機在時間t內的總油耗可由燃油消耗率積分得到:
(5)
1.3 電機建模
電機作為電動機時,通過電池組供電與發(fā)動機共同提供扭矩,輸出功率可以由輸出轉子端轉速和轉矩乘積決定;作為發(fā)電機時,通過回收發(fā)動機多余的輸出功率給電池組充電,發(fā)電功率由定子端電壓和電流乘積決定。
電動狀態(tài)時,電機轉矩Tmot與轉速ωn滿足:
(6)
發(fā)電狀態(tài)時,電機轉矩Tmot與轉速ωn滿足:
Pmot=Tmot·ωn·ηm
(7)
1.4 電池模型
采用容量為5.3 Ah的磷酸鐵鋰電池,整個電池組由72個單體電池串聯(lián)組成。忽略溫度對電池組的影響,使用內阻建模的方法建立電池組模型。電池組輸出功率Pbat和輸出電壓Ubat為:
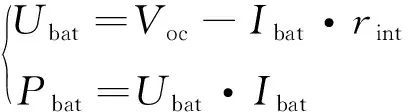
(8)
式中:Voc為開路電壓;rint為電池內阻;Ibat為電池電流。由式(8)可知,當電池組輸出功率已知時,電池電流可表示為:
(9)
電池荷電狀態(tài)SOC是電池組的重要參數(shù),是電池所剩電量和電池總容量Qbat之比:

(10)
式中:Ibat為電池電流,本文選擇SOC作為能量管理問題中的狀態(tài)變量之一。聯(lián)立式(9)和(10)可得SOC微分,重新表示為:
(11)
1.5 建模約束
為了保證部件的安全性和可靠性,整車動力系統(tǒng)需要滿足相應的物理約束,即發(fā)動機與電機的輸出轉速、轉矩,SOC的變化范圍、電池功率應該在約束范圍內工作:
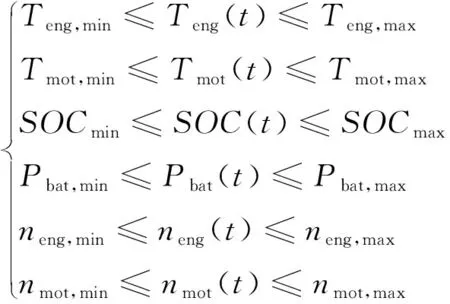
(12)
2 等效燃油消耗最小控制策略
等效燃油消耗最小控制策略(equivalent consumption minimization strategies,ECMS)基于的理念:電量維持型的混合動力汽車的電池初始SOC值和最終SOC值之間的差異非常小,相對于所使用的總能量可以忽略不計,所以最終所有的能量消耗均來自燃油。電池等同于一個可逆的輔助油箱,消耗的電能終將通過發(fā)動機的多余輸出功率補充回來。
ECMS的關鍵思想是,在放電過程中,等效燃油消耗可以與電能的使用聯(lián)系起來。未來(或過去)電能消耗可以等效為燃油消耗量,與當前實際燃油消耗量求和可以得到瞬時等價燃油消耗。以功率的形式定義ECMS的瞬時成本:
Peqv(t)=Pfuel(t)+s(t)Pbatt(t)
(13)
式中:s(t)是等效因子,其作用是把電池的功率轉為等效的燃油功率。實際上,等效因子代表燃油轉化為電能的效率鏈,也是電能轉化為等效油耗的效率鏈,因此,它會隨著動力系統(tǒng)的運行條件而改變。根據(jù)等效因子是否會實時變化,將ECMS分為恒等效因子ECMS和A-ECMS。
恒等效因子ECMS將等效因子看作一個恒定的常數(shù),該常數(shù)往往是在離線實驗中通過迭代發(fā)現(xiàn)最優(yōu)值求得。但是離線實驗得到的等效因子往往只適用于一段工況或者同類型的各工況,沒辦法滿足混合動力汽車復雜的行駛工況。
基于SOC反饋的A-ECMS是通過一個PID控制器根據(jù)SOC與SOC目標值的差值來輸出一個可實時變化的等效因子,這是一種最常見的A-ECMS方法,如圖3所示。該種方法由于只單一地考慮SOC的變化,沒有考慮復雜工況的行駛需求以及汽車本身的狀態(tài),所以控制效果并不是很好,本文將利用DDPG算法對此控制策略進行優(yōu)化探索。
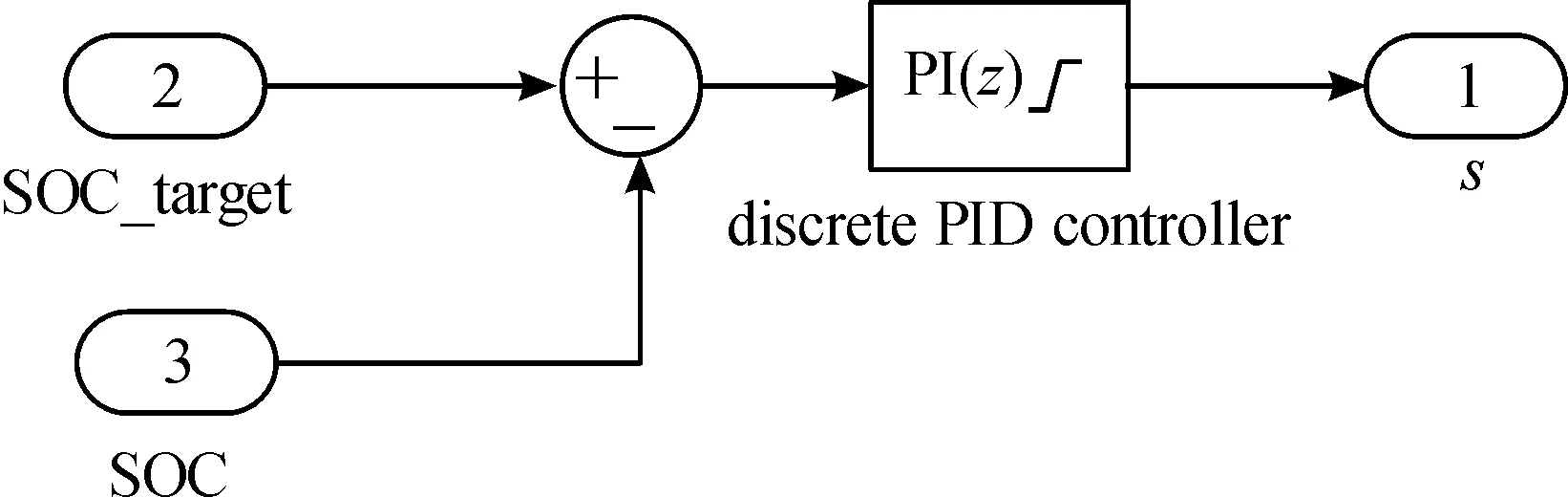
圖3 基于PID的A-ECMS邏輯圖
3 強化學習理論
3.1 強化學習
強化學習主要應用于控制領域,它的本質是試錯學習,通過不斷地探索與環(huán)境交互獲取狀態(tài)和獎勵來優(yōu)化自身的策略。從圖4中可以看出,在t時刻狀態(tài)St下,智能體根據(jù)已有的策略選取動作At,環(huán)境在t+1時刻到達狀態(tài)St+1,同時反饋一個獎勵Rt+1給智能體,通過此循環(huán)不斷優(yōu)化獎勵值得到接近最優(yōu)的控制序列。
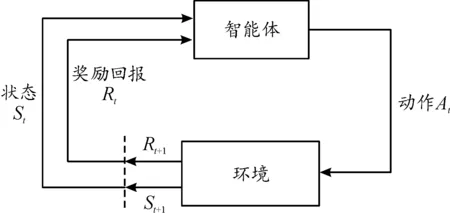
圖4 強化學習過程框圖
3.2 深度強化學習
普通的強化學習是表格化動作、狀態(tài)和獎勵,通過與環(huán)境交互對狀態(tài)下采取動作所獲得的獎勵值進行迭代,直至收斂。這種方法受到儲存空間、狀態(tài)與動作的維度的限制,讓強化學習只能用于較為簡單的離散動作控制。深度強化學習早在2015年就已經(jīng)被提出來了,谷歌Deepmind團隊將其用于解決圍棋問題,在與人類的比賽上,成功擊敗人類頂級棋手,讓強化學習受到了學者們的廣泛關注[21-22]。如圖5所示,智能體動作的選擇,以及評價動作選取的優(yōu)劣都是通過神經(jīng)網(wǎng)絡來實現(xiàn)的,提高了算法的計算能力,為強化學習應用于更加復雜的環(huán)境提供了基礎。

圖5 深度強化學習邏輯圖
3.3 深度確定性策略梯度算法
2016年,在DQN算法的基礎上結合Actor-Critic和確定性策略梯度,谷歌Deepmind團隊提出了DDPG算法,該算法可以在連續(xù)空間上進行控制,動作直接由神經(jīng)網(wǎng)絡輸出[23]。如圖6所示,DDPG算法總共有2套Actor-Critic網(wǎng)絡,一套為評估網(wǎng)絡,另一套為目標網(wǎng)絡。
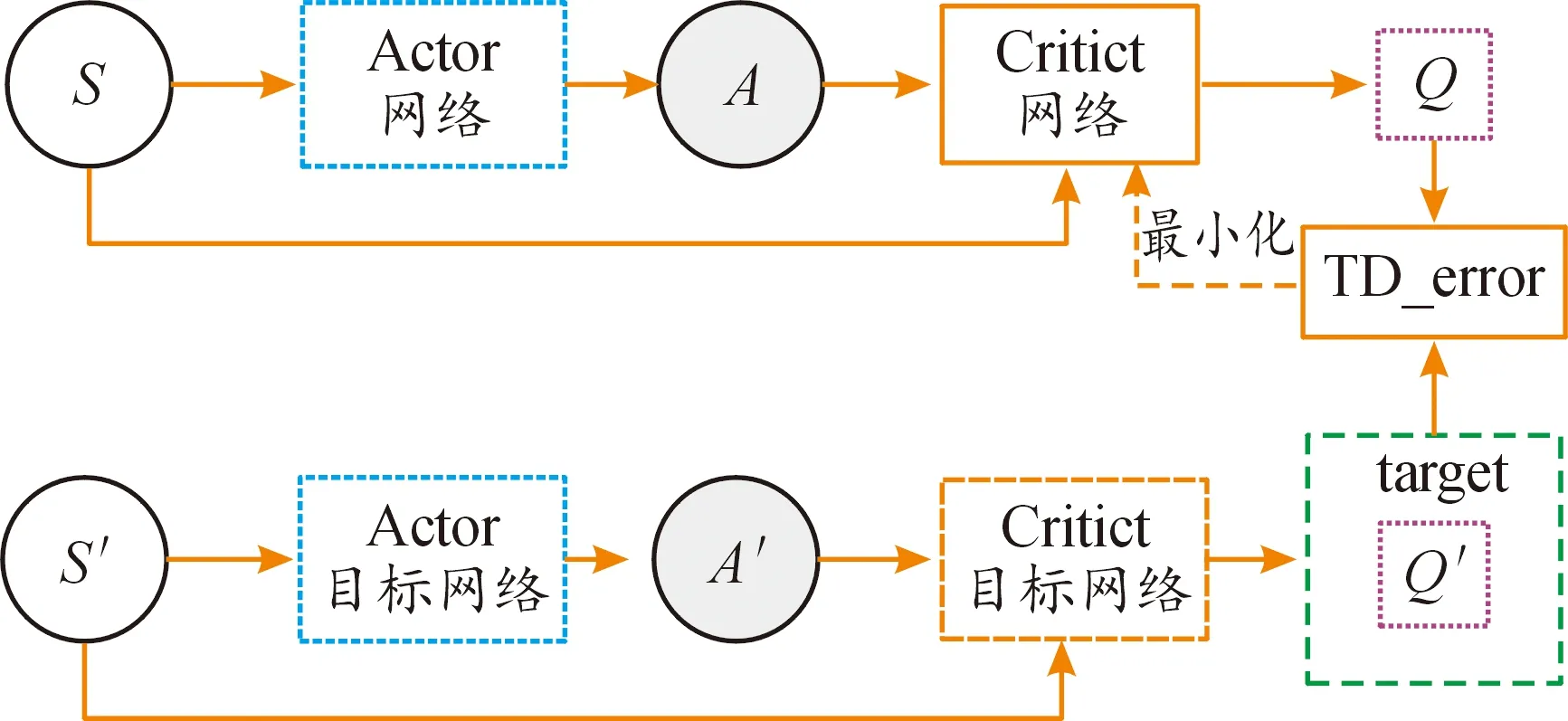
圖6 DDPG算法邏輯圖
Actor網(wǎng)絡目的是找出動作A,令輸出的Q(S,A)最大化,Critic網(wǎng)絡是根據(jù)當前的動作A和狀態(tài)S計算出Q(S,A)。算法更新時,智能體先凍結住目標網(wǎng)絡,從換環(huán)境獲得狀態(tài),通過評估網(wǎng)絡計算出Q值,同時也通過目標網(wǎng)絡計算出Q′值,最小化Q和Q′的差值來更新評估網(wǎng)絡。當智能體與環(huán)境交互經(jīng)過時間T之后,把評估網(wǎng)絡的網(wǎng)絡參數(shù)賦值給目標網(wǎng)絡。
DDPG算法的偽代碼如下:
1: Randomly initialize critic networkQ(s,a|θQ) and actorμ(s|θμ) with weightsθQandθμ
2: Initialize target networkθ*andμ′ with weights
θQ←θQ,θμ←θμ
3: Initialize replay bufferR
4: for episode = 1 toMdo
5: Initialize a random processNfor action exploration
6: Receive initial observation state
7: fort= 1 toTdo
8: Select actionat=μ(st|θμ)+Ntaccording to the current policy and exploration noise
9: Execute actionatand observe rewardrtand observe new statest+1
10: Store transition (st,at,rt,st+1) inR
11: Sample a random mini-batch ofNtransitions (si,ai,ri,si+1) formR
12: Setyi=ri+γQ′(st+1,μ′(si+1|θμ)|θQ)
13: Update critic by minimizing the loss:
14: Update the actor policy using the sampled policy gradient:
▽θμμ(s|θμ)|si
15: Update the target networks:
θQ←τθQ+(1-τ)θQ
θμ←τθμ+(1-τ)θμ
16: end for
17: end for
4 基于深度強化學習微調的能量管理策略
A-ECMS根據(jù)電池SOC的實時變化對等效因子進行實時地修改來控制發(fā)動機與電機的輸出功率。但A-ECMS對汽車自身的狀態(tài)考慮較少,僅考慮了電池SOC的變化,所以本研究通過DDPG算法考慮汽車自身的狀態(tài)來獲得一個等效因子修正量,然后與PID控制器輸出的等效因子相加得到最終的等效因子來控制發(fā)動機與電機的輸出功率,整個控制邏輯如圖7所示。從圖7中可以看出,基于DDPG微調的能量管理策略在考慮電池SOC的基礎上,增加了上一時刻的發(fā)動機和電機的輸出扭矩和當前時刻的需求扭矩。

圖7 基于DDPG微調的A-ECMS能量管理策略邏輯圖
結合文獻和源代碼的理解[19,24],搭建基于DDPG算法框架的部分超參數(shù),如表2。DDPG中神經(jīng)網(wǎng)絡的結構如圖8,Actor網(wǎng)絡和Critic網(wǎng)絡均由輸入層、3個隱藏層、輸出層構成,其中每一層隱藏層包含120個神經(jīng)元,神經(jīng)層之間均采用全連接。

表2 DDPG超參數(shù)
DDPG記憶庫需要存儲由當前狀態(tài)St、該狀態(tài)下所執(zhí)行的動作At、動作執(zhí)行后得到的獎勵Rt以及環(huán)境所達到的下一狀態(tài)St+1組成的一個四元組(St,At,Rt,St+1)。所以,接下來分別對狀態(tài)、動作、獎勵進行定義。
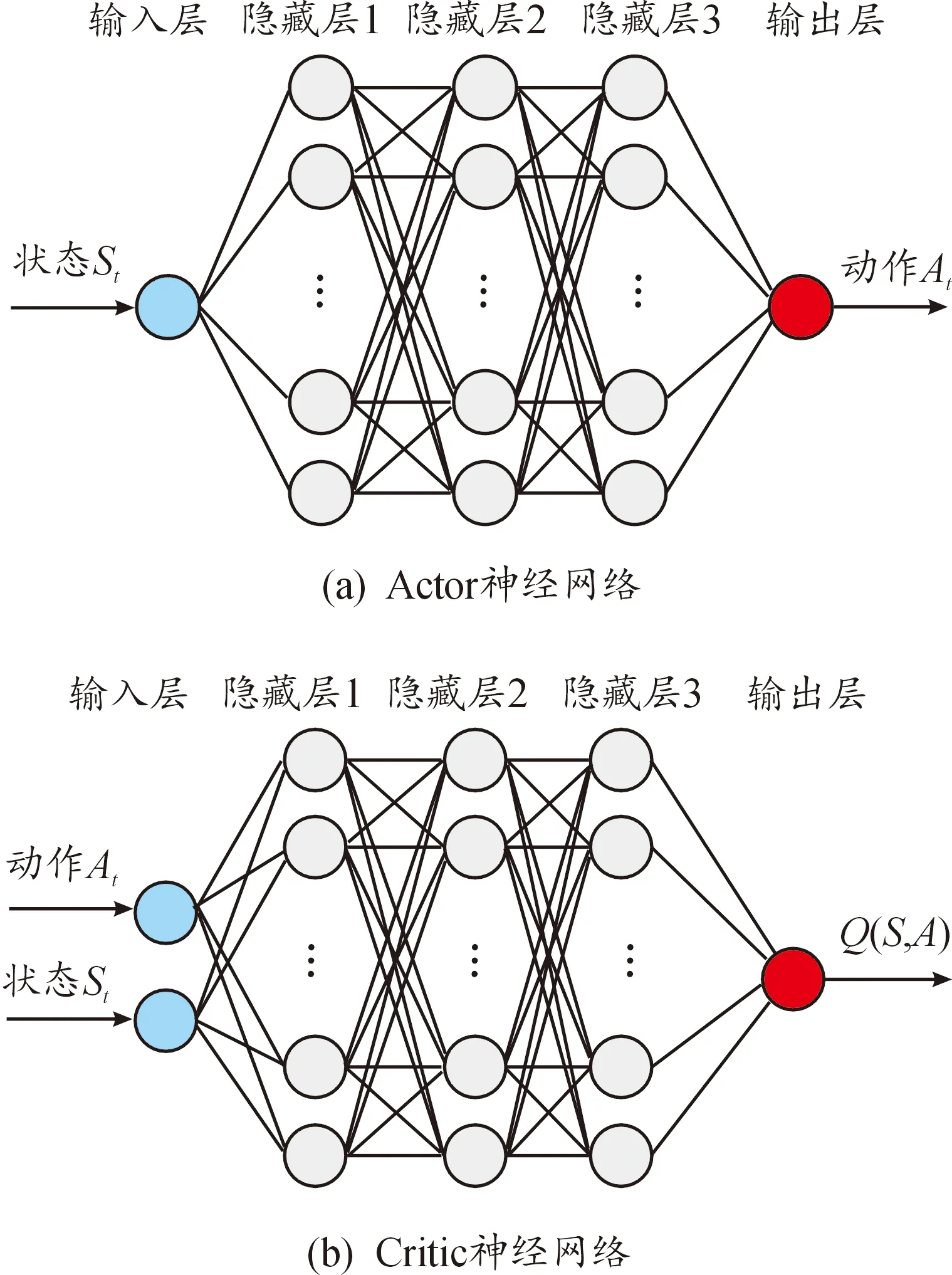
圖8 Actor和Critic神經(jīng)網(wǎng)絡結構示意圖
狀態(tài)St:混合動力汽車的駕駛循環(huán)是連續(xù)變化的,所以為了更加準確地描述混合動力汽車的狀態(tài),狀態(tài)應選擇連續(xù)變量。同時,如何精確描述行駛狀態(tài)的變化具有很大的挑戰(zhàn)性,所以應該選擇能夠定義混合動力汽車的行駛周期狀態(tài)的狀態(tài)變量。本研究選取了6個狀態(tài)變量:電池SOC、PID控制器輸出的等效因子、汽車的需求扭矩、上一步的輸出動作、上一步ECMS的電機和發(fā)動機的扭矩控制量。選擇SOC作為狀態(tài)變量是因為本研究的混合動力汽車是電量維持型的混合動力汽車,所以SOC與汽車油耗息息相關,如何在電量與油耗之間找到最優(yōu)的平衡點是本研究的目的。選擇PID控制器輸出的等效因子、汽車的需求扭矩、上一步的輸出動作、上一步ECMS的電機和發(fā)動機的扭矩控制量作為狀態(tài)變量是為了更加準確地描述混合動力汽車當前的狀態(tài),對等效因子的影響因素考慮更加完善,從而更加準確地修正等效因子。
動作At:通過DDPG控制根據(jù)汽車當前的狀態(tài)對PID控制器輸出的等效因子施加一個修正量,從而讓ECMS控制器能夠更合理地分配發(fā)動機電機輸出扭矩。
獎勵Rt:獎勵信號應該與整個模型的優(yōu)化目標高度相關。本研究的最終目的是在保持電池SOC的基礎上盡可能地減少油耗,所以本研究的獎勵函數(shù)包含了電池SOC和油耗2個關注點,獎勵函數(shù)設置如下:
rt=exp(-0.7|et|-0.3|it|2)
(14)
式中:et是電池SOC與目標值的差值;it是控制周期內的燃油消耗量。經(jīng)過調整后,最終將et和it的系數(shù)設置為0.7與0.3。為了保證計算的高效性,采用高斯函數(shù)的形式對獎勵函數(shù)進行構建,讓獎勵值在(0,1)。
5 仿真分析
使用一臺搭載Windows 10專業(yè)版、64位操作系統(tǒng)、處理器為Intel(R) Core(TM) i5-10400F CPU @ 2.90 GHz、基帶RAM為32.0 GB的計算機完成計算任務。在Matlab/Simulink中搭建混合動力汽車仿真模型,通過To Workspace建立數(shù)據(jù)輸出接口,而在Python端通過調用Matlab中的m文件控制混合動力模型,以此循環(huán)交互完成仿真實驗。
將FTP75循環(huán)工況作為DDPG算法的訓練工況。FTP75工況是美國環(huán)保局在1975年提出來的,用于評估車輛的燃油經(jīng)濟性,分為冷啟動、瞬態(tài)、熄火浸車、熱啟動4個階段,全程平均車速25 km/h,最高車速91.2 km/h,全程用時2 474 s,如圖9所示。
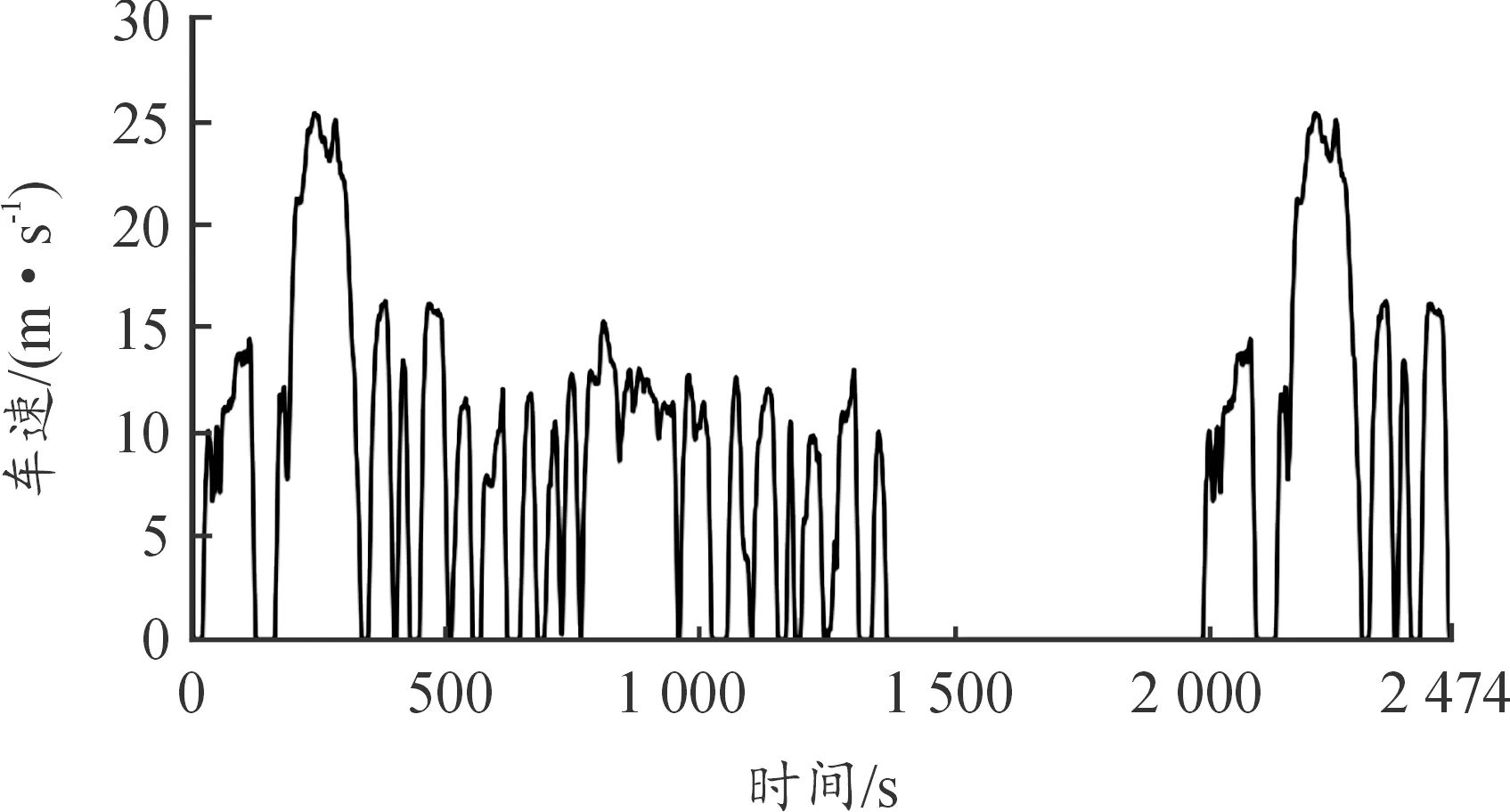
圖9 FTP75循環(huán)工況車速曲線
當算法訓練收斂后,將使用NEDC循環(huán)工況進行驗證,該工況包含了市區(qū)和市郊2種工況,具有頻繁的加減速和啟停,還有持續(xù)的加速,也是目前中國正在使用的測試工況,如圖10所示。為了證明所提出控制策略的優(yōu)越性,將基于DDPG微調的A-ECMS能量管理策略同基于規(guī)則的ruler-based、深度強化學習(DDPG)、A-ECMS、動態(tài)規(guī)劃(DP)4種能量管理策略分別在電池SOC和等效油耗上進行分析比較。
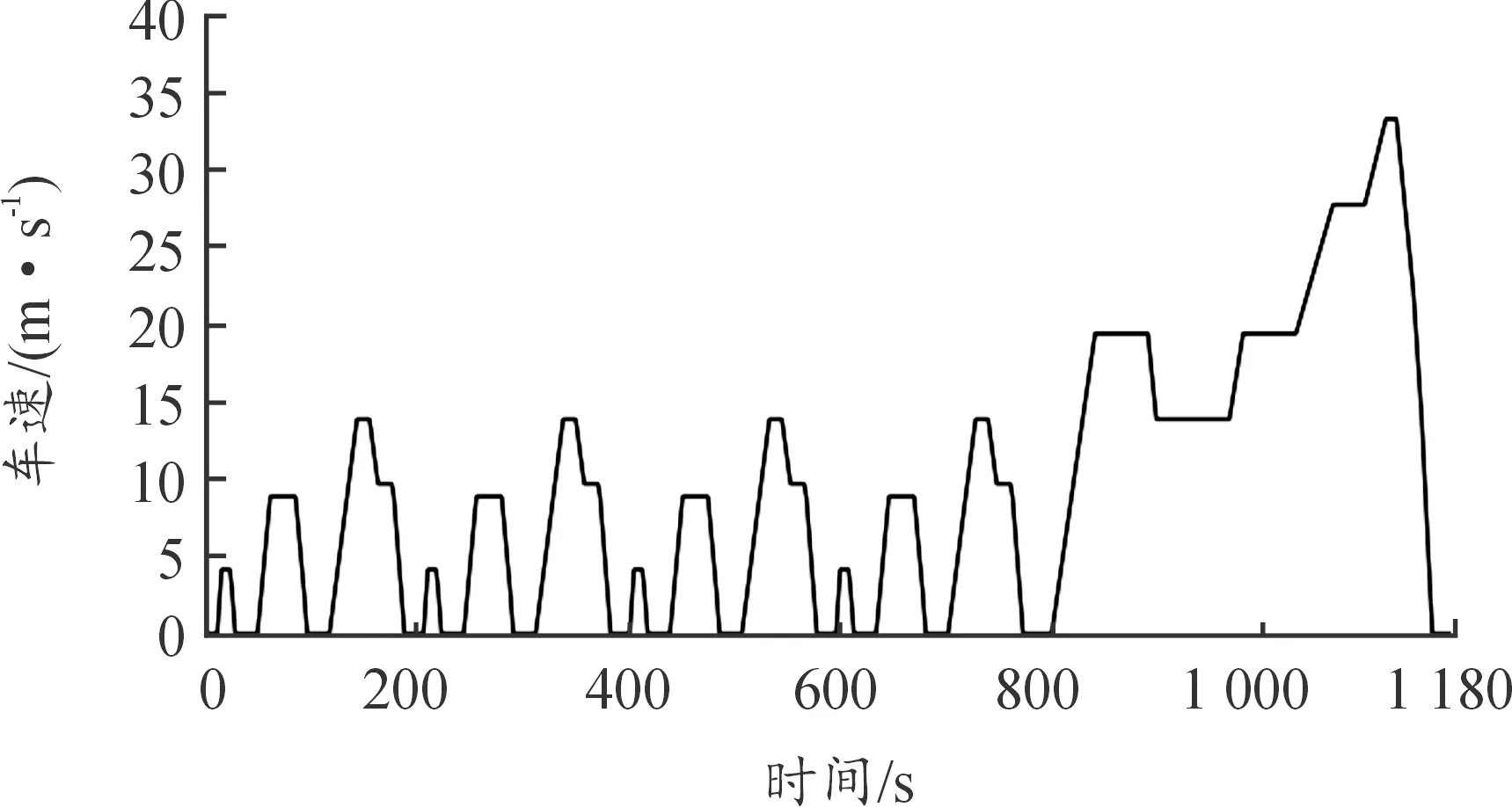
圖10 NEDC循環(huán)工況車速曲線
圖11是DDPG與DDPG微調的能量管理策略學習曲線。從圖11中可以看出,2種控制策略均能通過前期的探索然后收斂,但是兩者在收斂回合數(shù)和收斂時的獎勵均有所不同,具體細節(jié)如表3所示。
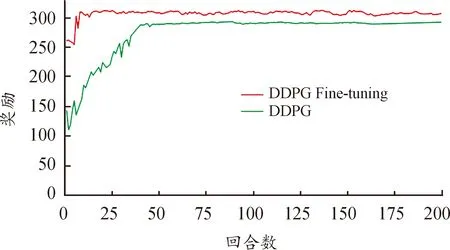
圖11 基于DDPG和DDPG微調的能量管理 策略學習曲線

表3 DDPG與DDPG微調學習曲線的細節(jié)
由表3可知,DDPG收斂時的回合數(shù)為40,DDPG微調收斂時的回合數(shù)為16,在訓練時間上效率提升60%;同時DDPG微調收斂時的獎勵值為308.6,相較于DDPG收斂時的獎勵值在動作優(yōu)化上提高了6.05%(選擇的動作越好,所獲得獎勵越高)。由此可知,將PID控制器的輸出動作作為輸入狀態(tài)的DDPG微調的控制策略能夠花更短的訓練時間得到更好的控制動作序列。
從圖12可以看到,動作的隨機選取概率隨著訓練回合數(shù)的增加逐漸減小并趨近0。在訓練的前期,由于初始化的神經(jīng)網(wǎng)絡參數(shù)基本相同,因此需要較大的概率去探索獲取更多有用經(jīng)驗,加快收斂速度。在訓練的后期,因為當前智能體已經(jīng)學習到較好的策略,不適合使用較大的動作探索,所以選擇較小的動作探索。當概率逐漸趨近于0時,表示智能體所執(zhí)行的動作基本上都是由DDPG控制器給出,但仍然有極小的隨機概率,所以導致獎勵曲線在收斂后仍有小波動。

圖12 訓練過程中動作隨機選取概率變化曲線
圖13是5種能量管理控制策略在FTP75工況上的SOC的變化曲線。可以看出,5種能量管理策略均能夠在一個工況結束后將SOC控制在目標值附近。
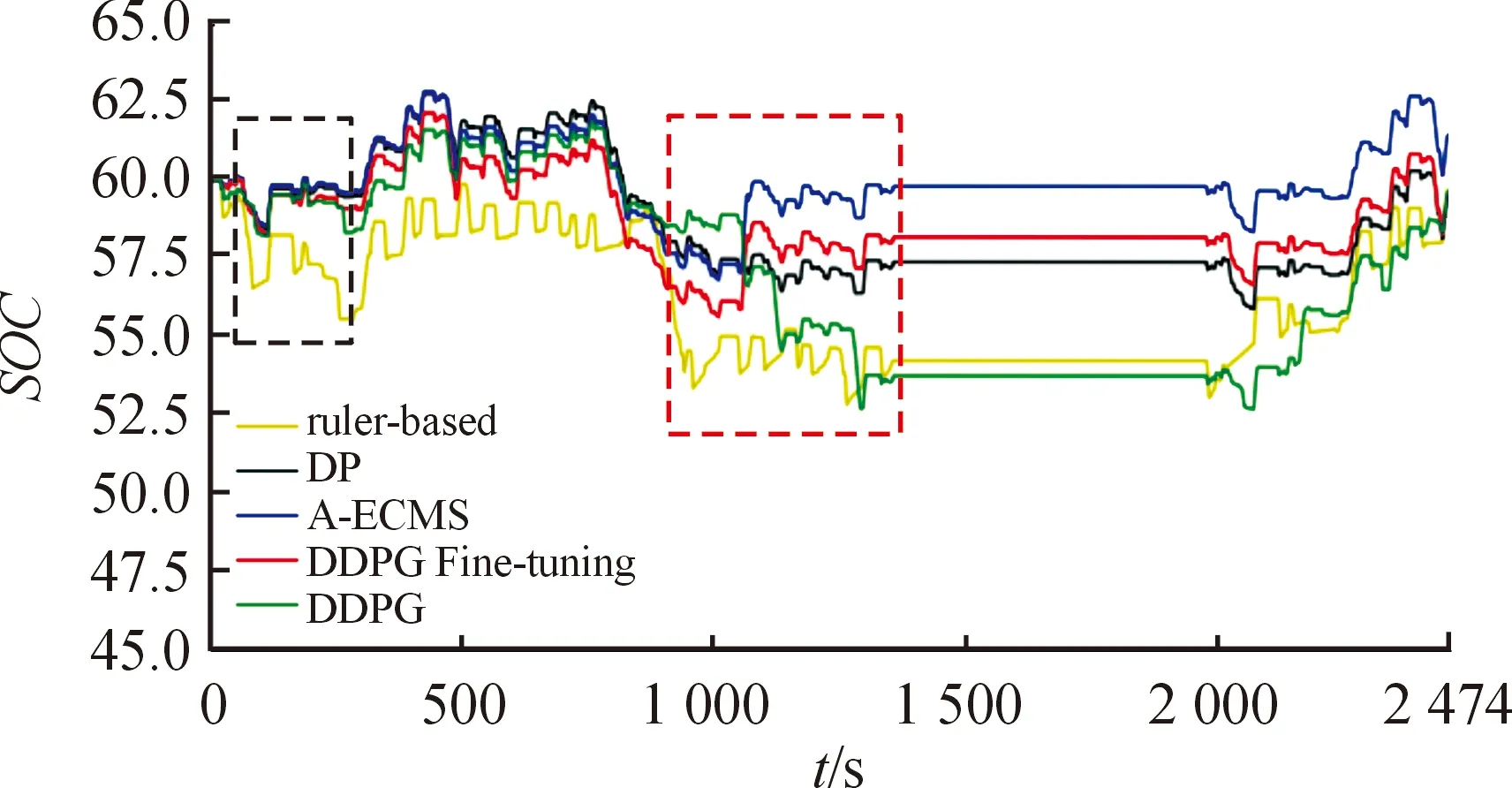
圖13 不同能量管理策略在FTP75工況的 SOC變化曲線
從表4可以看出,5種能量管理策略的SOC終止值都不相同,因為不同控制策略在控制時會選取不同的等效因子,所以導致控制策略對發(fā)動機與電機的扭矩分配不同,最終導致了SOC的差異。從SOC變化曲線可以看出,DDPG微調十分接近最優(yōu)的動態(tài)規(guī)劃曲線,SOC整體變化較為平緩,對電池有益。而基于規(guī)則和DDPG的SOC的變化較為劇烈,前者對電池的利用明顯沒有后者完善,電池一直在目標值之下工作。
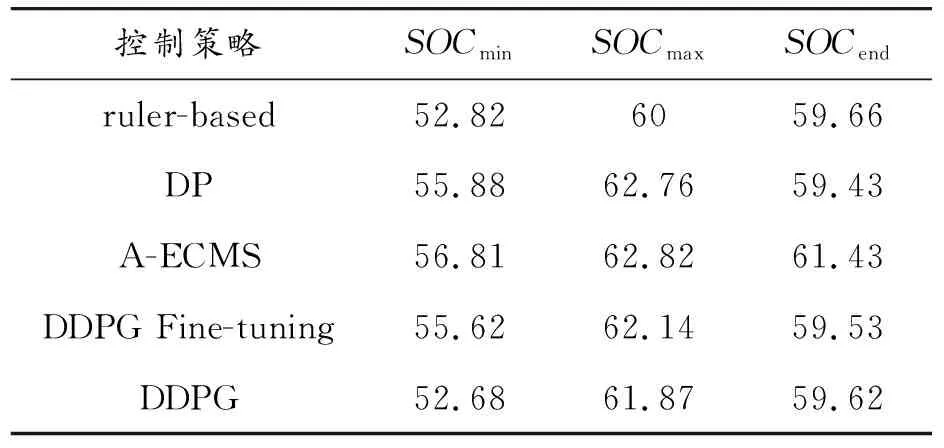
表4 不同能量管理策略在FTP75工況SOC曲線的特征參數(shù)
SOC曲線的差異主要在0~250 s(圖13黑色虛線方框)和800~1 350 s(圖13紅色虛線方框)。為了進一步解釋SOC曲線的差異,通過導出5種控制策略的發(fā)動機與電機扭矩分配圖來說明原因。從扭矩分配圖可知,基于規(guī)則的能量管理策略的發(fā)動機多數(shù)情況下提供較小的扭矩,剩下的扭矩完全靠電機提供,這導致了整個工況過程中SOC均在目標值之下。從圖14(a)黑色方框可以看到,這段時間內幾乎全靠電機提供扭矩,對應SOC在0~250 s和800~1 350 s的2次快速下降。圖14(d)中黑色方框里發(fā)動機與電機的轉矩分配則解釋了800~1 350 s基于DDPG能量管理策略的SOC曲線連續(xù)2次快速下降。從圖14(a)-(e)可以看出,不同的能量管理策略對發(fā)動機與電機扭矩分配存在較大的差別,DDPG微調的控制效果與動態(tài)規(guī)劃十分接近。
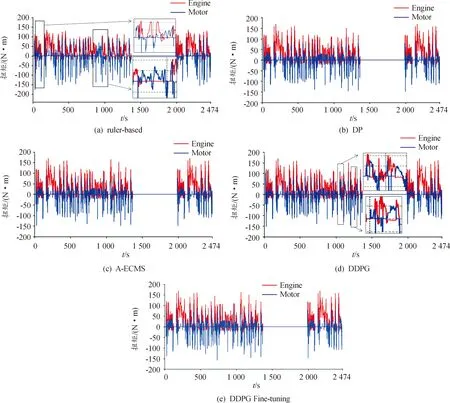
圖14 不同能量管理策略的發(fā)動機和電動機扭矩分配曲線
圖15給出DDPG微調控制過程中實際的車速曲線,DDPG能夠很好地滿足汽車的動力性要求,只有在最高車速附近時才與參考車速有一點差距,最大差值為0.79 m/s,與參考車速的均方誤差為0.03。
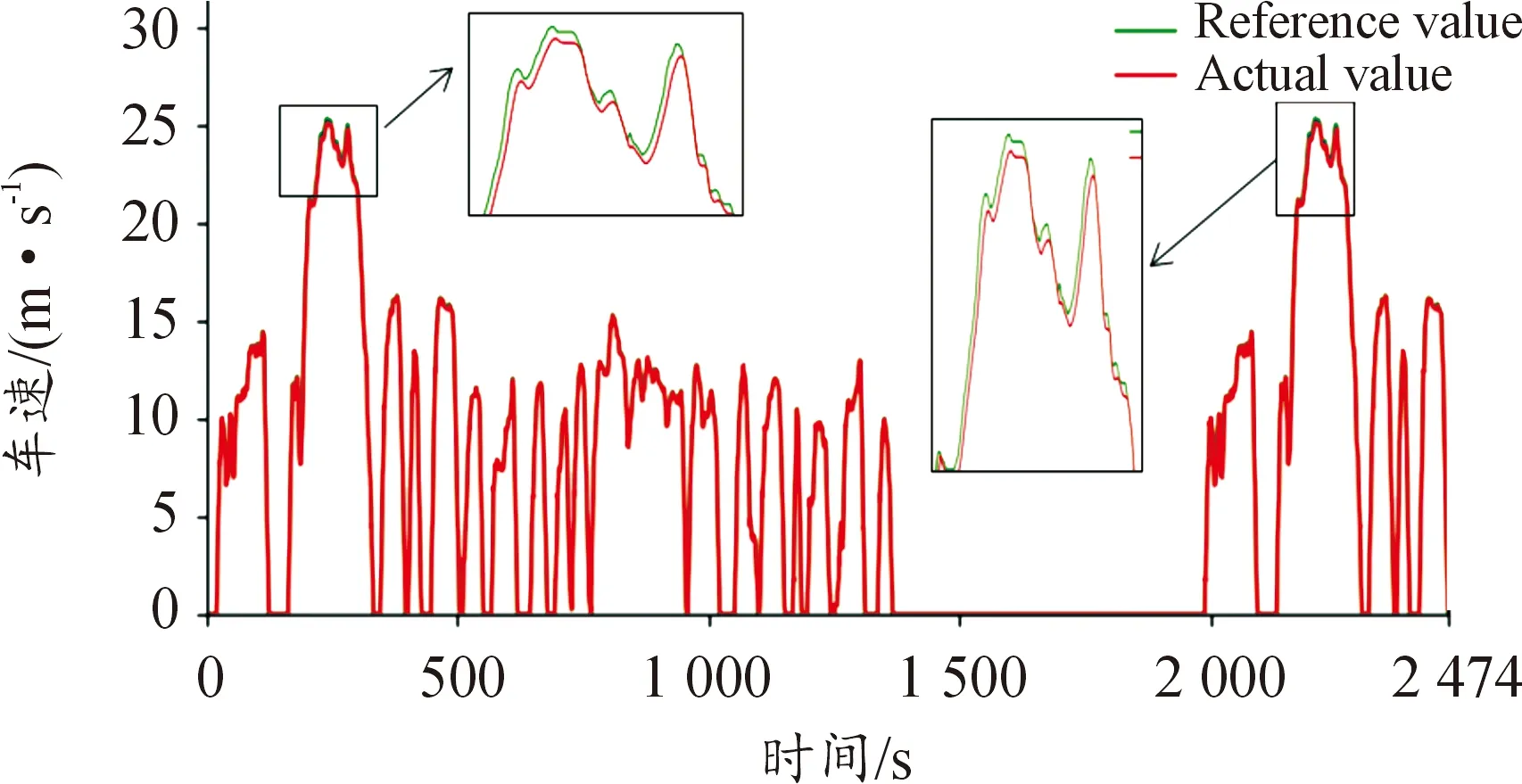
圖15 基于DDPG微調的能量管理策略的車速曲線
為了進一步證明本研究提出的基于DDPG能量管理策略的優(yōu)異性,表5給出了5種控制策略在FTP75循環(huán)工況上的等效油耗。動態(tài)規(guī)劃的等效油耗最低為7.61 L/100 km,本研究所提出的DDPG微調的等效油耗為7.62 L/100 km,十分接近最優(yōu)的動態(tài)規(guī)劃,與基于規(guī)則的相比,油耗減少了7.07%,與基于A-ECMS和DDPG相比,油耗減少了0.52%。從表5可以看出,DDPG通過訓練能夠取得與A-ECMS相近的控制結果,由于只保留了小數(shù)點后面兩位,但是實際結果是DDPG略微優(yōu)于A-ECMS。圖16給出不同能量管理策略的發(fā)動機工作點圖。從圖中可以看出,基于規(guī)則的能量管理策略的發(fā)動機大多數(shù)情況下工作在低扭矩高油耗區(qū)域。基于DDPG的能量管理策略與最優(yōu)的動態(tài)規(guī)劃較為相似,發(fā)動機多數(shù)情況下在高扭矩低油耗區(qū)域工作,而且發(fā)動機的扭矩輸出比基于規(guī)則的輸出范圍更大。
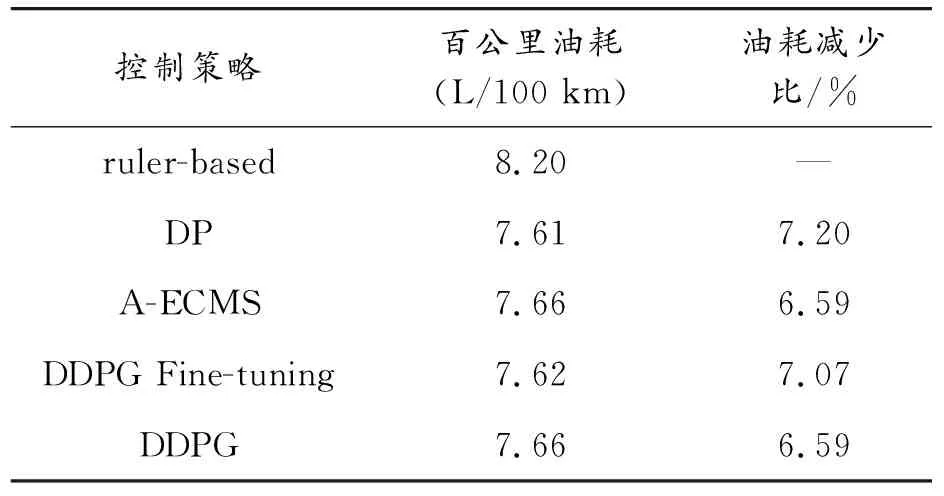
表5 不同能量管理策略在FTP75工況的等效油耗
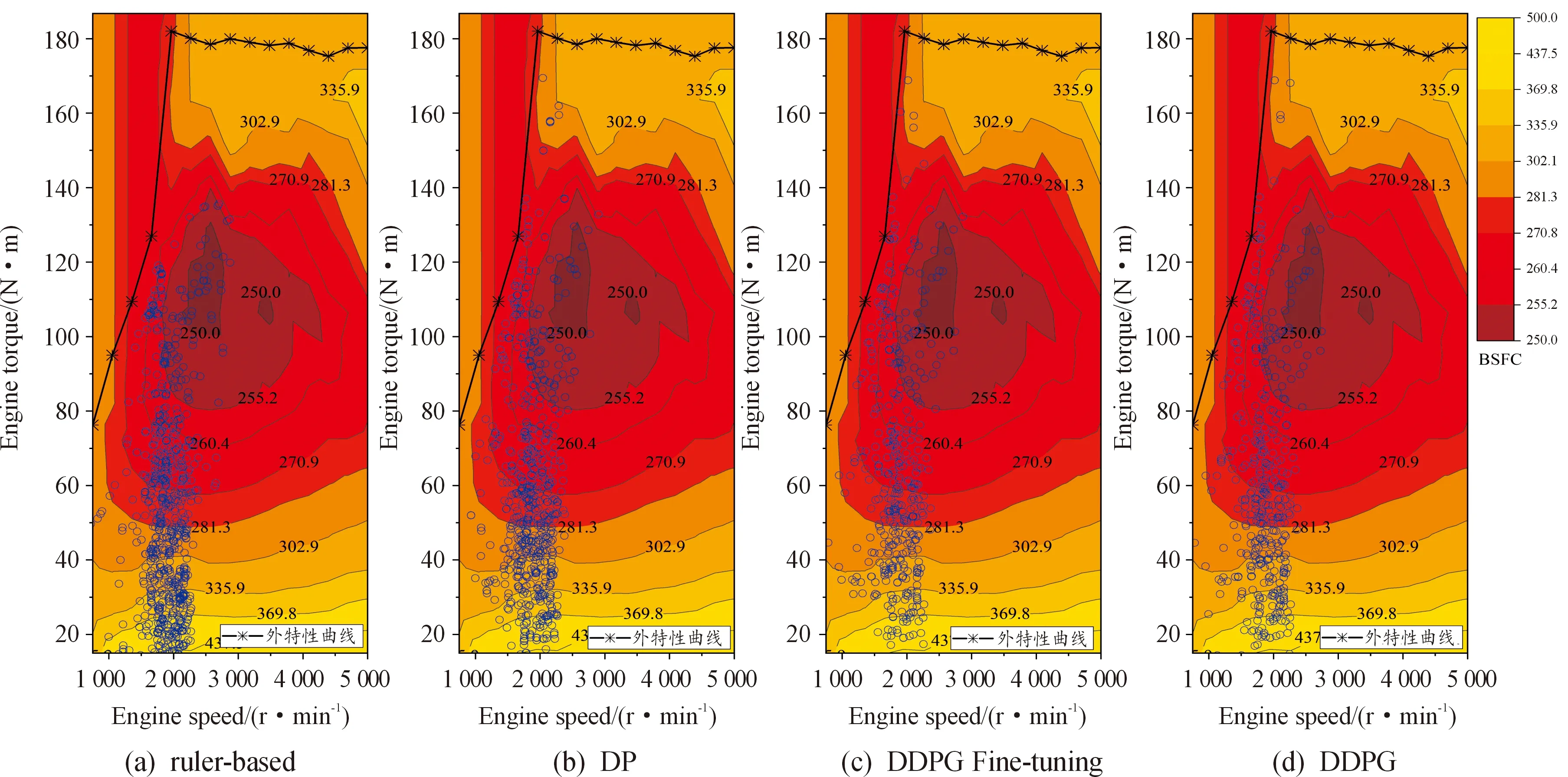
圖16 不同能量管理策略的發(fā)動機工作點圖
通過將訓練好的控制策略用于沒有接觸過的全新工況上對比控制結果,看是否能與訓練的控制結果一樣來驗證基于DDPG微調的能量管理策略的適用性。從圖17和表6可以看出,不同的能量管理策略在NEDC工況上的控制效果是不同的,但都能將SOC的終止值控制在目標值附近。發(fā)動機能長時間工作在高效區(qū)間,持續(xù)地加速和快速地制動減速,控制策略頻繁使用發(fā)動機提供扭矩,同時利用多余的扭矩和制動能量給電池充電。
在等效油耗上,本研究提出的基于DDPG微調的能量管理策略在測試工況上一樣取得了優(yōu)異的省油效果。在NEDC工況上,基于DDPG微調等效油耗為7.74 L/100 km,與基于規(guī)則的比較油耗減少2.27%,與基于A-ECMS的相比油耗減少0.77%(見表7)。
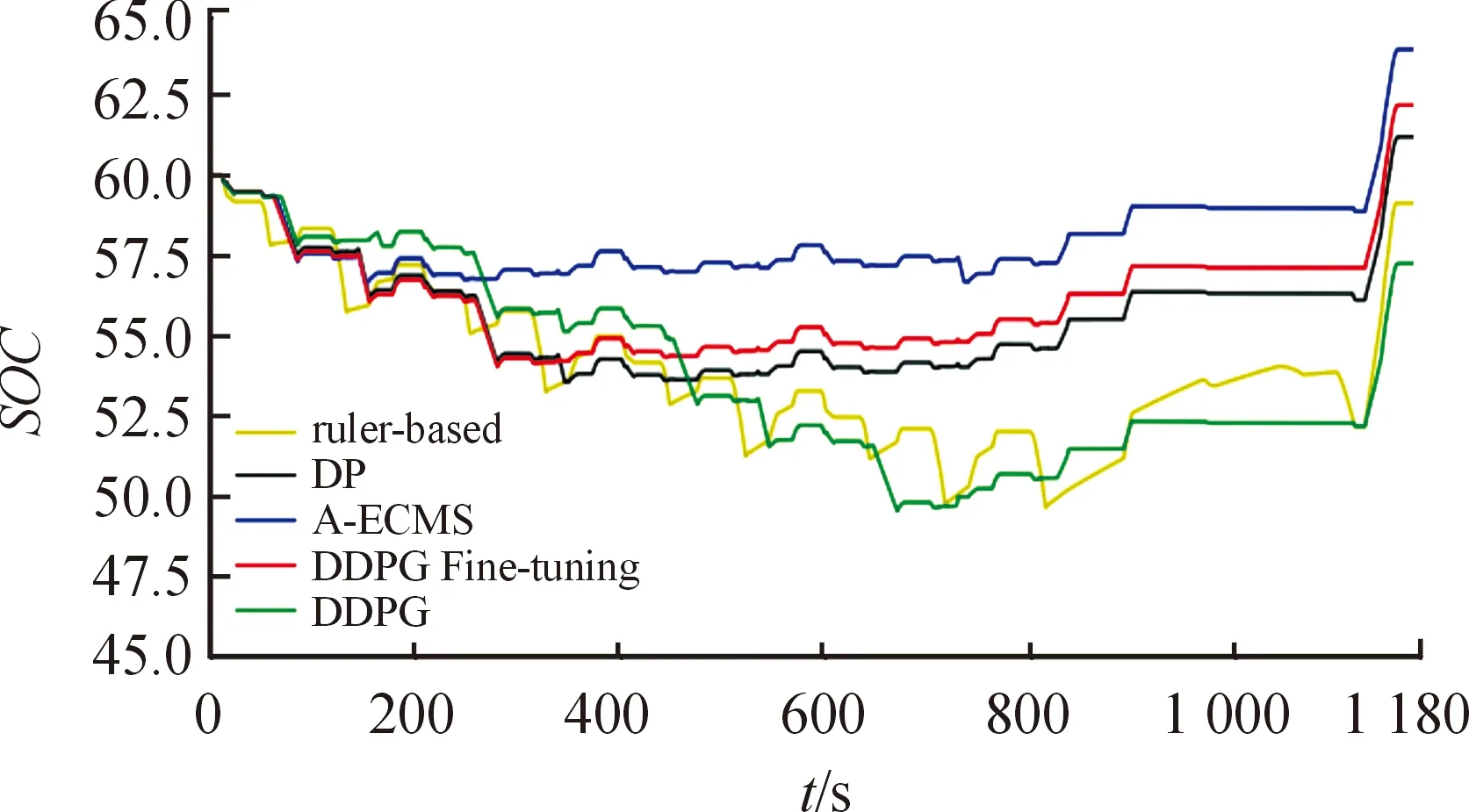
圖17 不同能量管理策略在NEDC工況的SOC變化曲線
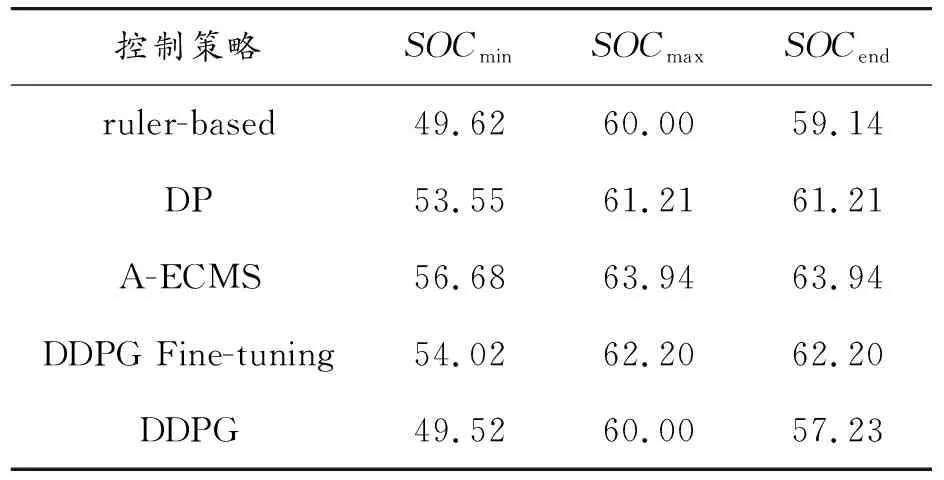
表6 不同能量管理策略在NEDC工況的SOC曲線特征參數(shù)
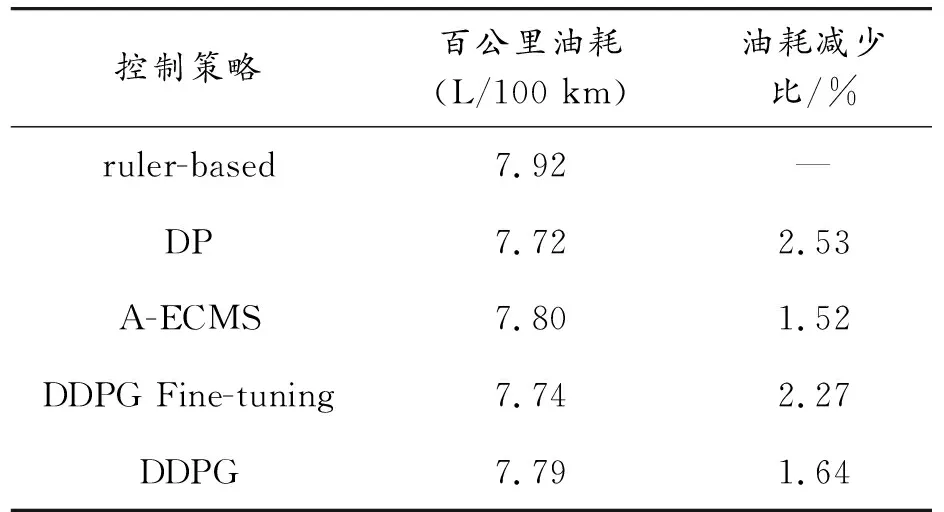
表7 不同能量管理策略在NEDC工況的等效油耗
6 結論
在A-ECMS的基礎上結合DDPG控制算法考慮更為全面的汽車狀態(tài),搭建了基于DDPG微調的能量管理策略,先進行了理論分析,然后通過仿真實驗進行驗證。由訓練過程可知,基于DDPG微調的能量管理策略可以在原有的強化學習的能量管理策略基礎上進一步優(yōu)化發(fā)動機和電機的輸出扭矩,優(yōu)化效果提升了6.05%,同時也能夠加快整個控制策略的收斂時間,效率提升了60%。在訓練工況FTP75以及工況NEDC和FTP72上均取得了優(yōu)于基于規(guī)則和A-ECMS的控制結果,證明了深度強化學習可以與其控制策略結合并取得優(yōu)于原來的控制結果。通過將訓練好的控制策略在不同工況上測試,從測試結果上可以得知,基于DDPG微調的能量管理策略能夠在保障優(yōu)異的控制結果的同時具備很好的可適用性。
本文的研究結果在混合動力汽車的控制策略優(yōu)化上有參考意義,同時也對強化學習用于優(yōu)化其他控制策略或者結合提供了思路。后續(xù)將會通過第三軟件獲取交通信息、平均車流速度等信息優(yōu)化控制策略的控制效果。未來,在有條件的情況下,將進行硬件在環(huán)驗證和實車實驗等。
猜你喜歡
能源工程(2020年6期)2021-01-26 00:55:22
民用飛機設計與研究(2019年2期)2019-08-05 01:33:40
山東冶金(2019年3期)2019-07-10 00:54:04
消費導刊(2018年10期)2018-08-20 02:57:02
兒童時代·快樂苗苗(2017年7期)2018-01-24 18:28:45
作文大王·低年級(2016年4期)2016-04-18 00:24:37
通信電源技術(2016年1期)2016-04-16 04:57:26
汽車與新動力(2015年1期)2015-02-27 12:11:01
決策探索(2014年21期)2014-11-25 12:29:50
汽車與新動力(2013年5期)2013-03-11 16:08:17
