考慮學習—遺忘效應的服裝縫制車間生產調度模型
2023-05-30 18:11:45董平軍俞佳安
現代紡織技術 2023年3期
關鍵詞:學習
董平軍 俞佳安


摘 要:面對訂單批量小、需求個性化等不確定性高的市場需求環境,結合服裝縫制生產中工序多、勞動密集、工人異質性等特點,構建考慮員工學習—遺忘效應的服裝縫制車間混合流水分批調度模型。模型以最小化最大完成時間和最小化工位空閑均方差為目標函數,設計非支配遺傳算法對模型求解,實現“工人—工序—工位”細粒度調度優化。用仿真實驗選出合適的批量大小作為實驗參數,并以標準加工時間為不考慮學習—遺忘效應的加工時間進行對比分析,結果表明考慮學習—遺忘效應比不考慮學習—遺忘效應更能適應工人的異質性和不穩定性,在目標函數值上表現更優,驗證了模型算法的有效性。
關鍵詞:學習—遺忘效應;縫制車間;生產調度;非支配遺傳算法;多目標優化
中圖分類號:TS941
文獻標志碼:A
文章編號:1009-265X(2023)03-0081-11
基金項目:國家自然科學基金項目(71872038)
作者簡介:董平軍(1973—),男,河北保定人,副教授,博士,主要從事企業數字化轉型方面的研究。
中國服裝產業目前已進入提質增效的關鍵時期。服裝生產企業一方面需要面對客戶需求日益個性化、交貨周期短的激烈市場競爭環境,另一方面又要應對勞動力成本上升、一線員工流動性高等不確定性因素。因此,構建服裝生產車間考慮人員因素及適應小批量快返的生產調度模型及算法,在數字化轉型背景下,對縫制車間生產提質增效有重要意義。
縫制車間生產主要有3種模式,捆扎式、推框式以及吊掛式。當前吊掛式生產是行業內較為普及的數字化生產方式,在吊掛生產系統下,裁片掛在衣架上并根據系統事先設定被送到相應的工位加工。而縫制車間生產具有工序繁多、工序順序柔性、設備使用柔性、分批傳輸等特點;同時設備加工需要工人時刻操作,當工人離開,對應工位則相應喪失加工能力,具有強人工依賴性。在車間實際生產過程中,工人會因長時間加工相同或類似的任務,熟練度增加而加工效率提高,同樣亦會因為工序間的差異性以及加工過程的中斷而加工效率降低;前者被稱為學習效應,后者則為遺忘效應。Biskup[1]在研究兩類單機調度優化問題時,以工件加工位置為基礎構建學習效應模型,首次將學習效應引入生產調度研究中;杜貞等[2]基于加工位置的學習效應模型,以最小化最大完工時間為目標函數,構建基于學習效應的置換車間流水調度模型,并采用螢火蟲算法進行求解;李永林等[3]則在研究多目標流水車間調度問題時,利用經典對數—線性學習曲線模型表示工件的實際加工時間。他們的研究均假定了每臺機器具有相同的學習率,并未考慮機器或工人的異質性。葉春明等[4]則是以半導體最后測試階段為研究對象,構建了與加工位置和中斷時間相關的學習—遺忘效應模型,僅考慮了加工位置對學習效應的影響;董君等[5]對半導體晶圓制造車間調度研究時,考慮機器學習效應的異質性,構建了雙因素學習效應模型,并未考慮遺忘效應。對學習—遺忘效應的合理考慮,可使車間生產更加適應工人異質性與流動性,具有重要指導意義,但在縫制車間調度問題的研究中,極少考慮員工的學習和遺忘效應。因此,本文綜合上述車間生產特點,并基于員工技能水平與學習能力考慮學習與遺忘兩種效應,將縫制車間生產調度問題抽象為考慮學習—遺忘效應的混合流水車間調度(Hybrid flow shop scheduling,HFS)問題。
HFS問題可看作并行機調度與一般流水車間調度結合得到的擴展調度問題,是一類NP難(NP-Hard)問題,對此研究中多使用啟發式或元啟發式算法進行求解,如改進的混合遺傳算法[6]、改進的貪婪算法[7]、模擬退火算法[8]、多策略粒子群算法[9]等。針對HFS問題,學者們在不同生產背景下,考慮多種目標與約束,進行了廣泛研究,Cao等[10]以鋼管生產為研究背景,提出了帶批量調度的動態混合流水車間調度;軒華等[11]考慮工藝特殊性,以最小化總加權完成時間為目標,研究了帶運輸時間的多階段動態可重入HFS問題;黃輝等[12]則考慮序列設置時間,結合工序可跳躍的生產約束,建立以最大完工時間和負荷均衡指標為目標的混合流水車間多目標調度模型,所得結果經驗證有效且符合實際需求;袁慶欣等[13]則綜合考慮各機器緩沖區容積有限、工件以批量形式運輸、運載能力有限等多個約束條件,研究了帶有限緩沖區的混合流水車間問題,得出運輸時間越短緩沖區占用越均衡。HFS問題研究在不同領域取得不錯進展,但在服裝縫制領域研究較少,謝子昂等[14]提出一種服裝吊掛流水線的自適應滾動窗口機制,綜合考慮服裝生產中的多種約束條件,建立以最小化完工時間和設備等待時間為目標的多目標動態調度模型,但并未考慮工序順序柔性以及員工的學習—遺忘效應;黃珍珍等[15]結合拓撲方法和遺傳算法,構建工序編排模型,模型僅適用于大訂單生產,且缺乏對工人異質性的考慮。
本文結合縫制車間實際生產情況,考慮學習—遺忘效應、工序順序柔性、設備使用柔性、分批傳輸以及工人異質性等條件,構建考慮學習—遺忘效應的服裝縫制車間分批調度模型,并設計非支配遺傳算法對模型求解,以提高縫制車間生產效率及工位空閑均衡。
1 問題描述及建模
1.1 考慮學習—遺忘效應的調度問題描述
縫制車間生產調度是分批將各裁片及對應工序分配到不同工位上加工,并使最大完成時間等指標達到最優。具體可以描述為:某時刻到達訂單O,要求生產Q件服裝,將其分成n個大小相同的子批Oi(i=1,2,…,n)進行加工。可調度工位集W={w1,w2,…,wu,…,ww};子批Oi按照給定的工藝流程加工,流程由若干工序{pij|j=1,2,…,m}構成,并以鄰接矩陣Z表示工藝流程中各工序間的順序關系,矩陣Z如式(1):
每個工人依據過往經驗和崗前培訓等被分配到不同工位,根據分配工人的技能、學習能力等特征,工位相應具有不同的加工能力與效率;對已分配工位的工人,定義初始技能生疏系數矩陣Ai與學習率矩陣Li,Ai表征各工人對子批Oi不同工序的操作能力,Li則表示各工人對子批Oi不同工序的學習能力,具體如式(2):
同一類型的設備不同時刻可承擔多道工序的加工,因此,根據工位內的設備類型以及所分配工人的加工技能,每道工序pij有其可指派工位集Wij,WijW,工序pij可被Wij內任意工位加工;設定pij所需的標準加工時間為tij,即熟練度100%的一般工人加工pij所需時間。考慮上述條件,將子批的各工序分配到不同工位上加工,并使最大完成時間以及工位空閑均方差達到最優。
1.2 基本假設
為明確與簡化考慮學習—遺忘效應的縫制車間調度問題,本文做出以下基本假設:
a)同一子批內的工序一旦開始加工則不可中斷;
b)一個工位同一時刻只能加工一個子批的工序;
c)同一子批的某道工序只能在一個工位上加工;
d)子批之間無優先級,子批內部工序之間存在優先級。
1.3 學習—遺忘效應
在生產調度研究中,學者們經常基于兩種因素考慮學習效應,一是基于工件位置,二是基于累積加工時間;在實際加工過程中,已加工時間與工件加工位置都會對實際加工時間產生影響,且員工具有不同的技能生疏系數與學習率。文獻[5]基于預加工工件位置和已加工時間兩種因素構建了學習效應模型,本文借鑒該模型,基于重復加工次數和累積已加工時間考慮學習效應,以技能生疏系數矩陣與學習率矩陣體現員工的異質性,并引入不可壓縮因子保證效應的合理性。對于遺忘效應,文獻[16]中以中斷時間的指數函數來表示,本文借鑒該函數,考慮工人的非連續加工會使加工效率降低,以加工中斷時間的指數函數來表示遺忘效應。綜合上述考慮,構建了基于技能、學習能力與中斷時間3個因素的學習—遺忘效應模型,具體如下:
1.4 考慮學習—遺忘效應的多目標模型建立
1.4.1 目標函數
本文以調度決策單元最小化最大完成時間以及工位空閑均方差為目標,建立優化目標函數如式(6)、式(7)所示。
1.4.2 約束條件
本文的縫制車間生產調度模型,引入上文的學習—遺忘效應,同時考慮加工設備、加工工藝、工序順序以及批量容量等相關約束,具體如下所示:
a)加工時間約束
式中:Rij表示pij的優先標志,取值范圍為{0,1},1表示第j-1道工序與第j道工序有嚴格優先關系,0則表示沒有;Rij的取值規則:基于LPT規則(Longest processing time rule,LPT),優先選擇加工時間最長的工序;根據矩陣Z,對工序j后具有嚴格先后關系的所有工序的標準加工時間加總計算得出優先級數,對前后工序的優先級數比較大小確定優先標志;若前項工序優先級數較高,取1,反之,則取0。Ej為特殊工序標識,表明子批的第j道工序是否為交匯處工序,取值范圍為{0,1},若為交匯處工序,值為1,反之為0。式(12)保證非柔性工序在前項工序完成后才可加工,也保證柔性工序無需等待前項工序便可加工;式(13)保證了在交匯工序前所有工序均已完成。
d)批量大小約束
式中:Q表示訂單O所需生產的總數量;Dh、Dl分別表示批量容量的上限與下限,子批的大小不可超過或低于該參數;其中,式(14)表示批量劃分約束,子批的數量總和等于訂單總量;式(15)表示批量容量約束,保證子批的大小在批量容量限制范圍內。
2 算法設計
非支配遺傳算法(NSGA-II, non-dominated sorting genetic algorithm II)是Deb等[17]在NSGA算法的基礎上提出的。NSGA-II算法作為常用的多目標優化算法,不僅運行速度快,且解集的收斂性良好,因此本文利用該算法求解考慮學習—遺忘效應的多目標調度模型。算法具體流程如圖1所示。
2.1 編碼、解碼和初始種群生成
本文算法中的染色體以自然數編碼,采用工序鏈/工位鏈雙層編碼結構,染色體長度為調度的工序總數。工序鏈染色體中基因代表子批的編號,數字出現次數表示該子批對應的工序號;工位鏈按子批進行組織排序,鏈中基因編碼為工序所選的加工工位。在解碼過程中,同時考慮加工時間約束、加工唯一性約束、工序順序柔性以及學習與遺忘效應,以確定所有子批的工序完工時間及加工工位。另外,對于初始種群,采用隨機生成方式,首先獲得子批總數和子批工序數量;重復生成每個子批的子批編號,編號重復次數為每個子批的工序總數,形成一個序列;然后對該序列隨機打亂得到染色體工序鏈。根據子批編號次序,依次找到工序鏈中相同編號的位置,在工序對應的可用工位集內隨機選擇一個工位,將該工位編號插入到工位鏈的對應位置;重復該步驟直至所有工序均分配對應加工工位,形成完整的染色體工位鏈。
2.2 快速非支配排序和擁擠比較算子
擁擠度是指種群中給定個體與周圍個體間的密度,可表示個體與其相鄰個體在不同目標函數上的聚類距離,個體的擁擠度由其在各目標函數上的擁擠度分量構成,具體計算如下:
擁擠比較算子基于個體的非支配等級以及擁擠度對不同個體進行比較,若個體i所處非支配層級高于個體j,選擇個體i;反之則選擇個體j;若個體i,j處于同一非支配層級,但個體i具有更大的擁擠度,選擇個體i;反之則選擇個體j。
2.3 遺傳算子和終止條件
交叉與變異:考慮工序數量約束,本文對工序鏈采用POX交叉以及兩點變異的方法,通過對工序的隨機分組與交叉繼承,形成合法子代,然后在子代中隨機選取兩個基因進行互換操作,完成變異,得到滿足合法性約束的新工序鏈。對工位鏈采用MPX交叉以及單點變異方法,通過隨機生成的0-1 Rand序列,對兩個可行的父代工位鏈進行交叉,對應Rand序列為1則互換基因,為0 則保持不變,以此方式生成可行子代,然后在子代鏈中選擇單個變異點,到其對應可用工位集選擇工位變異,以此保證工位鏈的可行性。
自適應交叉與變異概率:算法求解過程中,采取固定交叉與變異概率容易使算法陷入局部最優,因此,本文采用自適應交叉概率Pc與變異概率Pm,將個體擁擠距離與個體所在Pareto前沿的個體平均擁擠距離比較,引入迭代因子,確定交叉與變異概率,具體計算公式如下:
式中:Pc,max、Pc,min分別表示種群內交叉概率的最大值與最小值;Pm,max、Pm,min則表示種群內變異概率的最大值與最小值;Pc,avg、Pm,avg分別表示平均交叉概率與平均變異概率;G、i分別表示總迭代次數與當前迭代次數; dj(i)表示個體j在第i次迭代時的擁擠距離;dagv(i)第i次迭代時種群平均擁擠距離。
終止條件:本文采用混合終止條件來判斷算法結束,一是以最大迭代次數Imax作為算法終止條件之一,以保證算法必然會在執行Imax次后停止;二是在連續θ次獲得的隔代Pareto最優集的種群距離小于給定的閾值時,算法即可停止。當兩個Pareto最優集是前后代的關系,則稱這兩個種群為隔代種群;設P、Q為隔代種群,對P中每個個體求其到Q中每個個體的歐式距離,將求出關于P中某個體的所有距離中的最小值作為P中該個體到Q的距離;對P中所有個體到Q的距離求和取平均,該平均值即為P、Q間的種群距離。閾值則是根據初始種群設定,首先確定各目標中絕對值相對較小的目標,確定該目標中的最大值,以最大值的1%(或更小)作為閾值。
3 仿真與分析
3.1 參數設置
本文基于無錫某服裝集團縫制車間生產數據,編制如下案例。假設某時刻到達一小批量生產訂單,該訂單要求生產圓領襯衫300件,其具體工藝流程如圖2所示。
該訂單分配到車間一生產組加工,組內工人共9人,一人分占一個工位,且各工位安排一臺設備,其中,包縫機、平縫機與壓條機分別為4臺、3臺和2臺。每個工人—設備組合對應不同的學習率,工人—設備分配以及對應學習率參數設定情況如表1所示。各工序可用工位集以及工人對各工序的技能生疏系數詳情設置如表2、表3所示。另外,由于工位場地、傳輸容量與資源等限制,批量容量上限為30,下限為5。
3.2 仿真結果與分析
本實驗算法采用Python3.7編程實現,所有實驗均在Intel(R) Core(TM) i5-1135G7@2.40 GHz,運行內存為16.0GB的計算機上進行,對NSGA-II算法求得的Pareto最優方案集,利用Topsis法對解集中所有方案進行綜合評價,獲取其中一個調度方案作為求解結果;實驗以算法運行10次的平均結果做記錄。算法的初始參數設置如下:種群規模P=100;最大迭代次數300;初始交叉率與變異率分別為0.8和0.1,θ=30;模型部分參數設定ε=0.5、λ=0.7、ω=0.5、B0=600,b=0.01。
3.2.1 批量規模選擇
為選出合適的批量大小進行后續仿真,本文在批量容量范圍內以5遞增改變批量規模進行實驗,實驗結果如表4所示。由表4可得,當批量規模為5時,工位空閑均方差目標明顯變差,工位間負荷不均;當批量規模為30時,最大完成時間明顯增大,工位空閑均方差并未明顯增加,說明批量規模變大,單個批次的加工時間增大,工位間的等待時間均有所增大;而批量規模為20時,最大完成時間、工位空閑均方差、工位平均空閑時間、工位負荷率等指標均表現更優,由此說明批量規模的設定,不宜過大或過小,適當的批量規模,可以獲得更優的目標值。在本文批量容量范圍內,各目標在批量規模為20時表現更優,因此,本文將以20作為后續實驗的批量規模大小。
3.2.2 算法收斂性分析
以批量規模20進行實驗,圖3展示了NSGA-II算法在求解案例時的進化曲線。由圖3可知,該算法具有快速收斂的特點,在種群進化初期,最大完成時間與工位空閑均方差兩個目標值快速下降;最大完成時間與工位空閑均方差分別在迭代了約150與200次時趨于穩定,并收斂至一個穩定值。圖4展示了NSGA-II算法求解得到的調度方案結果圖,此算例中調度方案最大完成時間為13618 s左右,工位平均空閑等待時間約為4800 s,工位負荷率約64.5%。
3.2.3 學習—遺忘效應相關仿真對比分析
a)不同學習率與不同遺忘因子對最大完成時間和工位空閑均方差兩個目標的影響分析:由表5數據可見,當遺忘因子b不變時,隨著學習率l的增加,最大完成時間呈下降趨勢,工位空閑均方差也明顯降低;當l固定不變時,隨著b的增大,最大完成時間與工位空閑均方差兩個目標均呈明顯上升趨勢。工人學習率的升高,意味著車間生產中學習效應的增強,由此工序的加工時間縮短,實際生產周期也相應減小;而遺忘因子的增大,意味著對學習效果的減弱作用增大,工序實際加工時間增大,最大完成時間也相應增大。
b)是否考慮學習—遺忘效應的仿真對比:在不考慮學習—遺忘效應的情況下,工人的實際加工時間為工序標準加工時間,不隨加工次數與累積加工時間等變化;除前述算例外,改變每件服裝的加工工序及相應標準加工時間、并改變工人數,另設3個算例進行求解對比;其中,算例規模由子批大小、工序數以及工位數組成,如20*10*9表示每個加工子批的批量大小為20、每個子批有10道工序以及共有9個可加工工位。從表6可知,在目標f1、 f2上,4個算例均在考慮學習—遺忘效應情況下求得的結果更占優;從整體上比較,考慮學習—遺忘效應的結果較之不考慮學習—遺忘效應的結果,在f1、 f2上分別平均優化了27%、26%,驗證了本文模型的有效性。另外發現,考慮學習—遺忘效應的模型不僅能縮小調度方案的最大完成時間,在工位空閑均方差上也改善明顯,這對于計時工資制生產下的員工有重要意義,更優的工位空閑均方差可以更好的維持他們的心理平衡,進而增強員工穩定性,提高車間生產環境的穩定性。
c)優化目標對權重系數ω的敏感性分析:研究設計的學習—遺忘效應模型中,ω表示基于累積加工時間的學習效應權重系數,當ω=0時,表示工序實際加工時間由累計重復加工次數以及加工中斷時長決定;ω=1表示工序實際加工時間由累積已加工時間以及加工中斷時長決定;若ω取(0,1)之間,則表示工序實際加工時間由累計重復加工次數、累積已加工時間以及加工中斷時長三者共同決定,表7為權重系數ω取不同值時所對應的案例仿真結果。
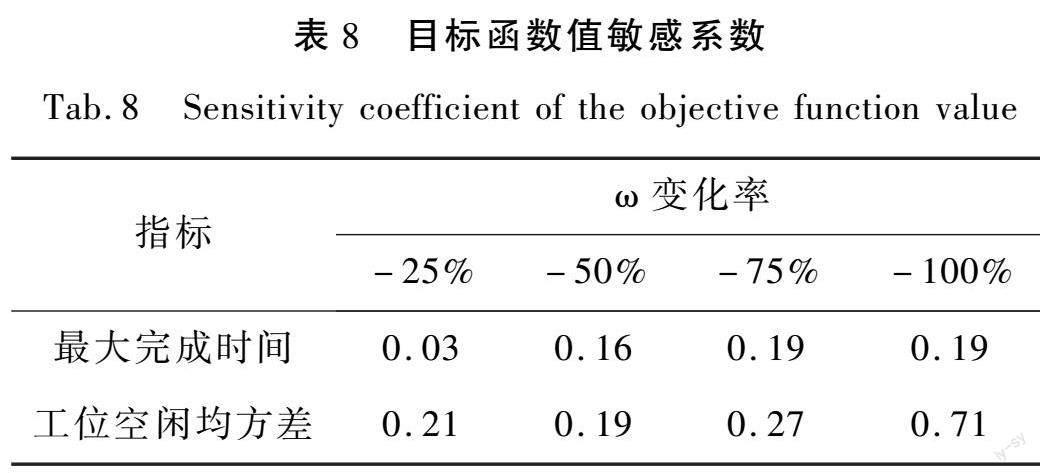
表8為利用敏感性分析方法[18],根據表7數據得到的目標函數敏感系數表,分析了權重系數ω對兩個目標的重要程度。由表8可知,隨著ω變化率的增大,其對最大完成時間的影響程度在增大;同時,表中敏感系數值均大于0,表明權重系數ω與最大完成時間、工位空閑均方差兩個目標同方向變化。另外,工位空閑均方差目標的敏感系數均大于最大完成時間對應的敏感系數,可見權重系數ω的變化率對于工位空閑均方差的影響大于其對最大完成時間的影響。
4 結論與展望
本文圍繞服裝縫制車間生產調度問題展開研究,考慮工人認知與學習差異性,基于工序順序柔性、設備使用柔性、分批傳輸、員工異質性等特點,構建了考慮學習—遺忘效應的混合流水多目標調度模型,并根據企業實例設計仿真案例,進行仿真實驗分析,主要結論如下:
a)通過實驗對比,選出合適批量大小,進行算法收斂性分析,得出NSGA-II算法在解決考慮學習—遺忘效應的縫制車間多目標優化調度問題上具有良好的收斂性,并以調度甘特圖展示部分求解結果。
b)進行一系列學習—遺忘效應相關仿真分析:首先,對比得出考慮學習—遺忘效應的調度相較于不考慮學習—遺忘效應的調度,能夠更好地體現員工間的差異性,均衡工位負荷,適應生產環境中的變化,得到更優的調度方案。其次,在不考慮工人異質性的情形下實驗,得出學習率與遺忘因子共同影響最大完成時間和工位空閑均方差,且學習率越高,車間生產中學習效應即越強,加工時間越短;而遺忘因子越大,對學習效應的減弱作用越大,最大完成時間越長。最后,通過不同權重系數ω對比實驗,發現工位空閑均方差目標對于權重系數ω的敏感度更高。
未來下一步研究:將結合生產現場實驗數據或生產歷史數據探究員工—工序組合的學習率分類規律,期望以此進一步提升動態環境下生產調度的個性化、實時性和適應性。
參考文獻:
[1]BISKUP D. Single-machine scheduling with learning consi-derations[J]. European Journal of Operational Research, 1999, 115(1): 173-178.
[2]杜貞,葉春明,凌遠雄.應用螢火蟲算法求解基于學習效應的PFSP問題[J].計算機工程與應用,2015,51(16):248-251,258.
DU Zhen, YE Chunming, LING Yuanxiong. Permutation flow-shop scheduling problem with learning effect based on firefly algorithm[J]. Computer Engineering and Applications, 2015, 51(16):248-251, 258.
[3]李永林,董明,ZHANG Yufeng.考慮學習效應的多目標流水車間調度問題[J].系統管理學報,2017,26(6):1071-1080.
LI Yonglin, DONG Ming, ZHANG Yufeng. Multi-objective flow-shop scheduling problems with a learning effect[J]. Journal of Systems & Management, 2017,26(6):1071-1080.
[4]葉春明,侯豐龍,趙靜.具有學習—遺忘效應的半導體批調度問題研究[J].運籌與管理,2019,28(7):192-199.
YE Chunming, HOU Fenglong, ZHAO Jing. Research on semiconductor batching scheduling problems with learning and forgetting effects[J]. Operations Research and Management Science, 2019, 28(7):192-199.
[5]董君,葉春明.具有學習效應的半導體晶圓制造綠色車間調度問題研究[J].運籌與管理,2021,30(4):217-223.
DONG Jun,YE Chunming. Research on green job shop scheduling problem of semiconductor wafers manufacturing with learning effect[J]. Operations Research and Management Science, 2021, 30(4):217-223.
[6]崔琪,吳秀麗,余建軍.變鄰域改進遺傳算法求解混合流水車間調度問題[J].計算機集成制造系統,2017,23(9):1917-1927.
CUI Qi, WU Xiuli, YU Jianjun. Improved genetic algorithm variable neighborhood search for solving hybrid flow shop scheduling problem[J]. Computer Integrated Manufacturing Systems, 2017, 23(9): 1917-1927.
[7]宋存利.求解混合流水車間調度的改進貪婪遺傳算法[J].系統工程與電子技術,2019,41(5):1079-1086.
SONG Cunli. Improved greedy genetic algorithm for solving the hybrid flow shop scheduling problem[J]. Systems Engineering and Electronic, 2019, 41(5):1079-1086.
[8]黎陽,李新宇,牟健慧.基于改進模擬退火算法的大規模置換流水車間調度[J].計算機集成制造系統,2020,26(2):366-375.
LI Yang, LI Xinyu, MOU Jianhui. Large scale permutation flowshop scheduling method based on improved simulated annealing algorithm[J]. Computer Integrated Manufacturing Systems, 2020, 26(2):366-375.
[9]湯可宗,詹棠森,李佐勇,等.一種求解置換流水車間調度問題的多策略粒子群優化[J].南京理工大學學報,2019,43(1):48-53,62.
TANG Kezong, ZHAN Tangsen, LI Zuoyong, et al. Multi-strategy particle swarm optimization for solving permutation flow-shop scheduling problem[J]. Journal of Nanjing University of Science and Technology, 2019, 43(1): 48-53, 62.
[10]CAO Y, XUAN H, LIU J. Dynamic hybrid flowshop scheduling with batching production[J]. Applied Mechanics and Materials, 2011, 65: 562-567.
[11]軒華,李冰,王薛苑,等.帶運輸考慮的多階段動態可重入混合流水車間調度[J].控制理論與應用,2018,35(3):357-366.
XUAN Hua, LI Bing, WANG Xueyuan, et al. Multi-stage dynamic reentrant hybrid flowshop scheduling with transportation consideration[J]. Control Theory & Applications, 2018, 35(3):357-366.
[12]黃輝,李夢想,嚴永.考慮序列設置時間的混合流水車間多目標調度研究[J].運籌與管理,2020,29(12):215-221.
HUANG Hui, LI Mengxiang, YAN Yong. Research on multi-objective scheduling of hybrid flow production shop considering sequence setting time[J]. Operations Research and Management Science, 2020, 29(12):215-221.
[13]袁慶欣,董紹華.帶有限緩沖區的混合流水車間多目標調度[J].工程科學學報,2021,43(11):1491-1498.
YUAN Qingxin, DONG Shaohua. Optimizing multi-objective scheduling problem of hybrid flow shop with limited buffer[J]. Chinese Journal of Engineering, 2021, 43(11): 1491-1498.
[14]謝子昂,杜勁松,趙國華.襯衫吊掛流水線的自適應動態調度[J].紡織學報,2020,41(10):144-149.
XIE Zi'ang, DU Jinsong, ZHAO Guohua. Adaptive dynamic scheduling of garment hanging production line[J]. Journal of Textile Research, 2020, 41(10): 144-149.
[15]黃珍珍,莫碧賢,溫李紅.基于遺傳算法及仿真技術的服裝生產流水線平衡[J].紡織學報,2020,41(7):154-159.
HUANG Zhenzhen, MOU Bixian, WEN Lihong. Garment production line balance based on genetic algorithm and simulation[J]. Journal of Textile Research, 2020, 41(7): 154-159.
[16]CHIU H N. Discrete time-varying demand lot-sizing models with learning and forgetting effects[J]. Production Planning & Control, 1997, 8(5): 484-493.
[17]DEB K,PRATAP A,AGARWAL S, et al. A fast and elitist multiobjective genetic algorithm: NSGA-II[J]. IEEE Transactions on Evolutionary Computation, 2002, 6(2): 182-197.
[18]侯豐龍,葉春明,耿秀麗.基于多目標螢火蟲膜算法的學習效應生產調度問題[J].系統管理學報,2018,27(4):704-711.
HOU Fenglong, YE Chunming, GENG Xiuli. Learning effect production scheduling problem based on multi-objective firefly membrane algorithm[J]. Journal of Systems & Management, 2018, 27(4): 704-711.
Abstract: With the deep integration of cutting-edge technologies, such as Internet of Things, artificial intelligence and 5G and manufacturing, the fourth industrial revolution, represented by intelligent manufacturing, is taking place. There is no exceptions of traditionally labor-intensive textile and garment industry, in which most value chain sections such as spinning and weaving are undergoing or have undergone profound changes. Nevertheless, in the sewing link of garment manufacturing and production, on the one hand, most manufacturers are forced by market demand to increasingly turn to the production mode of small batch and short delivery cycle; on the other hand, the sewing link itself involves many processes and changes quickly. In the foreseeable future, it is difficult for automatic machines to meet this highly flexible production environment, and manual density will remain an important feature of garment sewing production. At the same time, China's textile and garment industry is in a period of transfer and change, with rising labor costs and high turnover of front-line production employees, resulting in more complexity and uncertainty. In order to adapt to the general trend of manufacturing transformation and upgrading, and adapt to the complexity of garment sewing production, it is one of the potential directions to study a new management scheduling method that takes into account workers' cognitive and learning differences.
We proposed a hybrid flow batch scheduling model including employees' learning and forgetting effects for garment sewing workshops. We used minimizing makespan and minimizing idle mean square error as the objective function, and selected the non-dominated genetic algorithm as the solution tool, aiming to realize "worker-process-station" fine-grained scheduling optimization. According to the model, we carried out an algorithm simulation experiment on a real garment factory data, selected the appropriate batch size as the experimental parameter, and compared two kinds of scheduling optimization models with and without learning and forgetting effects. The simulation results show that model considering the learning and forgetting effects is more suitable for the production environment under heterogeneous scenarios of workers than not considering, which verifies the effectiveness of the model and algorithm.
We introduce the worker learning and forgetting factor matrix to optimize scheduling design for increasingly uncertain production environment. As for how to reasonably determine each worker's learning and forgetting factors, we can consider using the real-time big data of the MES system, ERP system and the Internet of Things system of the garment factory in the next step to build a dynamic model to fit and calculate factors such as the learning and forgetting rate of "employee-process-station", so as to achieve a real-time dynamic executable scheduling scheme.
Keywords: learning and forgetting effects; garment sewing workshop; production scheduling; NSGA-II; multi objective optimization
猜你喜歡
校園英語·上旬(2016年10期)2016-11-16 18:34:24
校園英語·上旬(2016年10期)2016-11-16 18:09:12
讀寫算·素質教育論壇(2016年21期)2016-11-14 05:53:56
文理導航(2016年30期)2016-11-12 15:23:38
人間(2016年28期)2016-11-10 22:12:11
戲劇之家(2016年20期)2016-11-09 23:55:31
農業與技術(2016年15期)2016-11-09 17:45:14
人間(2016年26期)2016-11-03 18:25:32
啟迪與智慧·教育版(2016年8期)2016-10-20 16:00:16
啟迪與智慧·教育版(2016年8期)2016-10-20 15:31:51
