科研大數據迷霧模型的建構與解構
2023-07-20 17:36:26豐佰恒杜寶貴
現代情報 2023年7期
豐佰恒 杜寶貴
關鍵詞:科研大數據;科研大數據迷霧;模型;生態系統;數據治理
DOI:10.3969/j.issn.1008-0821.2023.07.001
[中圖分類號]G203 [文獻標識碼]A [文章編號]1008-0821(2023)07-0003-11
科研大數據是隸屬于大數據,產生于科研,輔助于科研,具有規模性、高速性、價值性、多樣性、高維性、錯綜性等特征,反映自然與社會現象的一種數據類型。在數據價比黃金的時代,科研大數據作為國家基礎性戰略資源引起多國(地區)關注。美國以《大數據研究發展倡議》等率先拉開科研數據治理的序幕,并在《大數據研究與發展計劃》中提及醫療、航天等眾多領域的科研數據管理,英國在《把握數據帶來的機遇:英國數據能力戰略》中警醒數據機遇,日本在《大數據時代的人才培養》中倡議培養專業化人才,中國亦在《科學數據管理辦法》中制定科研大數據管理規范。各國(地區)均聚焦于科研大數據的發展,使得數據量激增的同時,也帶來了科研大數據造假、科研大數據維度錯亂、科研大數據冗余等一系列“迷霧”問題,影響數據質量,危害數據安全。現有研究多集中在科研大數據共享、科研大數據時效、科研大數據質量管控模型、科研大數據維度災難、科研大數據安全等方面,對科研大數據迷霧的專項探析還存在些許不足。此外,在各國(地區)的科學數據交流愈加頻繁、數據維度急劇攀升的今天,科研人員的迷霧甄別能力愈發關鍵。在構建科研大數據迷霧模型基礎上,進一步了解科研大數據迷霧的類型、路徑及機理有助于科研人員走出“迷霧叢林”,維護科研大數據生態系統的和諧穩定。因此,本文以識別迷霧數據、規避科研風險為主要研究目的,以科研大數據生態系統中不斷演化的迷霧型科研大數據為主要研究對象,以科研大數據庫建設、科研決策、科研大數據政策制定為主要應用場景,創造性地建構了科研大數據迷霧模型,以期在豐富科研大數據相關理論的同時,對解決科研大數據冗余、科研大數據造假、劣質科研大數據傳播管控、科技政策制定等現實問題提供有益啟示。
1科研大數據迷霧概念的提出
“迷霧”的概念緣起于氣象學,后廣泛運用于其他領域。在經濟學領域,迷霧指干擾經濟發展方向、阻礙經濟發展的不穩定性因素;在政治學領域,迷霧指與本質相悖、掩蓋目的、迷惑敵方決策的一種政治行為;在新聞學領域,迷霧指脫離事實真相甚至與事實相反的扭曲報道等;在情報學領域,信息迷霧是信息戰的重要手段,指不真實、政治相關、隱藏目的、精心設計、以進攻為目標的虛假情報。數據迷霧是指用于誘騙、隱真的虛假、有毒、垃圾數據。與“信息迷霧”相比較,“科研大數據迷霧”是“信息迷霧”的重要核心內容;信息迷霧是數據迷霧的“外殼”,為“科研大數據迷霧”的產生提供了環境。信息迷霧越多,其產生科研大數據迷霧的可能性越大,反之,科研大數據迷霧越多,并經加工后產生信息迷霧的程度越大,故二者是相輔相成、相互促進的關系。“信息迷霧”與“科研大數據迷霧”兩者之間又存在區別:首先是本質屬性不同,科研大數據作為一種特殊的數據類型,本質上仍是具有即時高價值性的數據,而信息是對數據的反映,是對數據所記錄事實的傳遞;其次是人為干預程度不同,單一數據誕生初期并不具有迷惑性,當人員將數據應用于某一目的時,多重屬性的疊加,使其具有特殊含義,迷惑性逐漸顯現,而信息迷霧的迷惑性從信息產生初期便有大量的人為干預;最后是應用領域不同,信息迷霧最早出現于軍事領域,而科研大數據迷霧往往伴隨科研活動產生。由于數據包含著科研大數據這一種特殊類型,因此,數據迷霧與科研大數據迷霧緊密相關,是科研大數據迷霧的外延和上位集;換言之,科研大數據迷霧包含于數據迷霧,是數據迷霧的子集。與數據迷霧相比,科研大數據迷霧服務于技術壁壘,專指在不同科研大數據機構數據交流過程中,導致科研大數據質量與安全性降低,以及干擾科研人員決策的各類數據,其更集中體現科研域尺度,是“迷霧”在科研域的“直接而具體”的表現形式。
從空間角度看,“迷霧”入侵至科研大數據鏈后,以鏈帶狀在科研大數據生態系統中傳播,可新生、流通于科研大數據生態鏈的任意節點,由此可見其具有全鏈性;從時間角度看,其出現可大致劃分為濃淡兩期,隨時間而波動,在一定趨勢線上重復可預測,但迷霧數據的催生因素復雜,有時亦會出現突變情況,因此可認為其具有不嚴格波動性;從形態角度看,當出現相互引用錯誤、失效等數據時,迷惑性數據彌散形成迷霧,在科研大數據生態系統中久久不能消散,處于縹緲懸浮、動態演化的狀態,因此其具有霧化性特征;從人員分布角度看,學者間相互的數據引用使其擴散,但學科間存在一定的壁壘,對數據的引用也存在強弱關系的差異,因此迷霧數據的出現往往聚焦于特定的學科,各學科或主題間存在派系的關聯,可見其具有派系性特征;科研活動有著高精確度的要求,迷霧數據迷惑科研工作人員行為、加大實驗誤差、使指標失真、影響科研進程,甚至導致災難性后果,因此其具有災難性。
綜合以上分析,本文認為科研大數據迷霧( Sci-entific Research Big Data Fog,SRBDF)是指衍生于數據迷霧,以科研域虛假、有毒、垃圾、冗余數據為基本組成,以全鏈性、不嚴格波動性、派系性、霧化性、災難性為基本特征,在利益驅動下流轉于科研大數據生命周期,降低科研大數據質量、干擾科研決策、引發數據災難進而擾亂科研大數據生態穩定的一類數據的集合。2科研大數據迷霧模型的建構
科研大數據作為基礎性科技資源,引起諸多學者關注,并從數據共享與數據治理等不同角度構建了科研大數據相關模型。例如聚焦于科研大數據再生、科研大數據共生、科研大數據變異的科研大數據生態模型,以生態學的視角介紹了科研大數據復雜的生命周期;基于尖點突變理論、病毒傳播理論有科研大數據治理模型,側重于對科研大數據的宏觀治理;從數據倫理、科研誠信等不同視角出發的科研大數據共享模型,則致力于促進科研大數據的共享,以及關注科研大數據服務模式、服務系統的科研大數據服務模型等。綜上可以看出,以往的模型較多關注科研大數據生態系統的宏觀治理,鮮有迷霧型科研大數據的專項研究,針對“迷霧”問題的深度探索仍略顯不足。
科研大數據迷霧在科研大數據生態系統中逐漸演化生成,從“科研大數據生態系統”對“科研大數據迷霧”的作用角度看:在科研大數據生態失調下(即發生異常時)產生科研大數據迷霧,科研大數據生態系統是科研大數據迷霧的客觀環境,迷霧的生消都必須在系統內發生。科研大數據量激增使數據庫得以豐富的同時,也為“科研大數據迷霧”的產生提供了“土壤”。從“科研大數據迷霧”對“科研大數據生態系統”的影響角度看:“科研大數據迷霧”作為一種獨特的風險,是科研大數據生態系統的高危域。迷霧濃度影響系統穩定性,當迷霧濃度越大時生態系統越不穩定。科研大數據迷霧與科研大數據生態系統息息相關。
科研大數據迷霧作為干擾科研大數據生態穩定的一類數據的集合,本質依然是數據,仍具有數據的周期性生命特征,數據生命周期模型將數據管理劃分為生產、傳播、消費、分解等階段,同樣,科研大數據迷霧亦會經歷初生、激增、消散等過程。由此可見,數據生命周期理論對科研大數據迷霧的階段劃分具有較強的適用性。
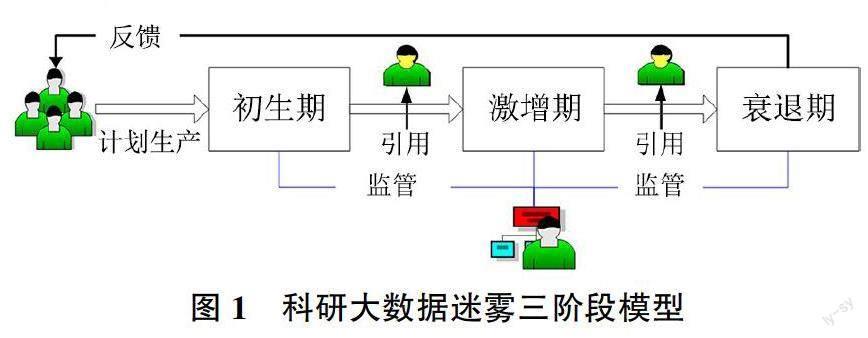
因此,本文基于科研大數據生態系統理論與數據生命周期理論,將科研大數據迷霧模型劃分為初生期、激增期、衰退期,并將模型內相關人員劃分為生產者、消費者、監管者、傳遞者,以建構科研大數據迷霧三階段模型,如圖1所示。
1)階段一:SRBDF初生期
此階段是科研大數據迷霧的計劃階段,迷霧生產者在利益驅動下生產迷霧數據,初生期科研大數據迷霧樣本較少,“迷霧”還沒有大范圍傳播,此時的科研大數據迷霧聚集現象較為明顯,即在初生期科研大數據迷霧往往集中在單一學科領域,因此階段一的迷霧較弱。
2)階段二:SRBDF激增期
在激增期迷霧數據量急劇增加,已擴散至相關領域,影響范圍逐漸增大,因此這一時期的科研大數據迷霧多呈彌散型狀態。此時迷霧強度將會出現峰值且短期內迷霧型數據會有爆發式增長的可能,對科研人員與政府來說最難控制,危害性也最大。對于迷霧生產者而言此階段獲益頗豐。
3)階段三:SRBDF衰退期
在第三階段,科研大數據監管者嚴格監管,科研大數據迷霧強度逐漸降低。對科研大數據消費者來說,此階段科研大數據迷霧災害性逐漸減弱。對于迷霧生產者而言,科研大數據迷霧的得益將會反饋,為下一步的科研大數據迷霧計劃提供參考。
科研大數據迷霧的存在給科研大數據生態系統帶來極大的安全隱患,其不僅僅會影響科研結果,還會影響政府決策,導致科技政策的制定出現偏差,甚至影響公眾對科研結果以及科技政策的認同感。與已有模型不同的是,科研大數據迷霧模型(Scientific Research Big Data Fog Model, SRBDF-M)以迷霧型科研大數據為主要研究對象,以幫助相關人員認識迷霧、了解迷霧、走出迷霧、科學決策進而維護科研大數據生態穩定為目的,以初生期、激增期、衰退期為主要劃分階段,專注于迷霧型數據的溯源與演化分析,側重于深入剖析科研大數據迷霧的生成、類型、作用路徑等,是科研大數據治理模型中對虛假、有毒、垃圾、冗余數據專項研究的子模型。
3科研大數據迷霧模型的解構
3.1科研大數據迷霧的組成類型分析
基于前文對SRBDF-M建構的基礎,在時間、空間、強度、利益、繁育等維度,對科研大數據迷霧的組成類型進一步闡述分析。
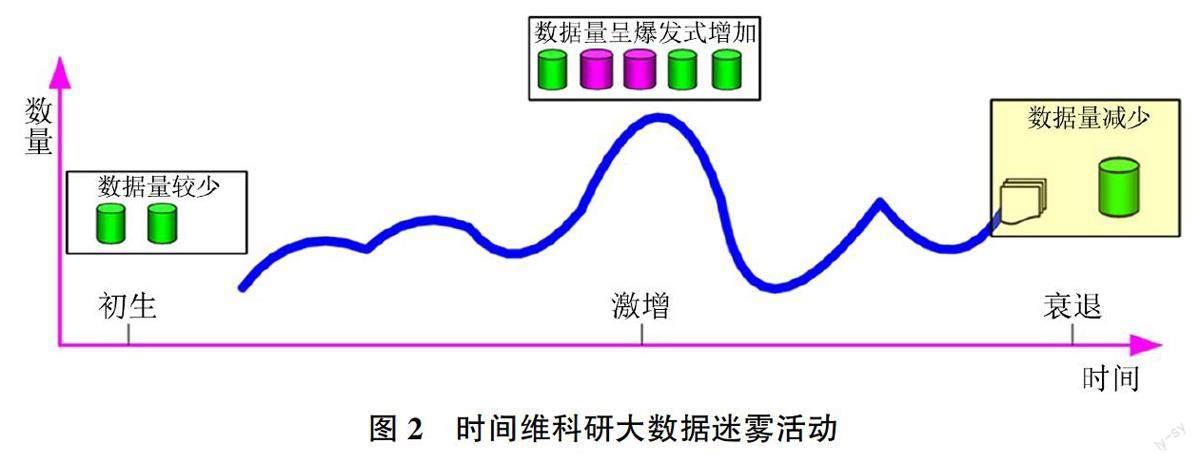
3.1.1時間維
結合科研大數據迷霧的波動性特征,在時間維度上,可分為“初生型”“激增型”“衰退型”3種類型,如圖2所示:
1)初生型(Primary Type)是指在初生期SRB-DF覆蓋范圍較小、影響力度較弱,此時其具有可辨、可減、可祛除的特點,科研大數據工作者可根據多年工作經驗及積累的技術辨別SRBDF,并采用相應措施祛除迷霧,減少其危害,例如《數據管理能力成熟度評估模型》定義的8個能力域中就包含了“數據質量”,并明確指出通過數據質量檢查來促進數據質量提升[38]。
2)激增型(Surge Type)是指在SRBDF初生期并未得到有效的控制,以致后續仍有大量相關的科研活動直接引用此部分數據,或是對此類數據次級引用,造成大范圍高強度的影響,此時其有范圍廣、強度高、難控制的特點,相關科研工作者除了需要投入大量的時間與精力來辨別迷霧,還需要掌握專業的技術,例如《土壤水分自動站逐小時資料質量控制方案》為甄別疑誤數據增加內部一致性檢驗。
3)衰退型(Recession Type)是指SRBDF在數據質量控制下其影響范圍與影響力度逐漸減小,呈現衰敗的特點,但仍具有死灰復燃的可能性,此類數據流轉至科研大數據流中易成為新一輪迷霧的催生動力。從SRBDF的“初生”到“激增”再至“衰退”體現了其周期性與波動性特征。
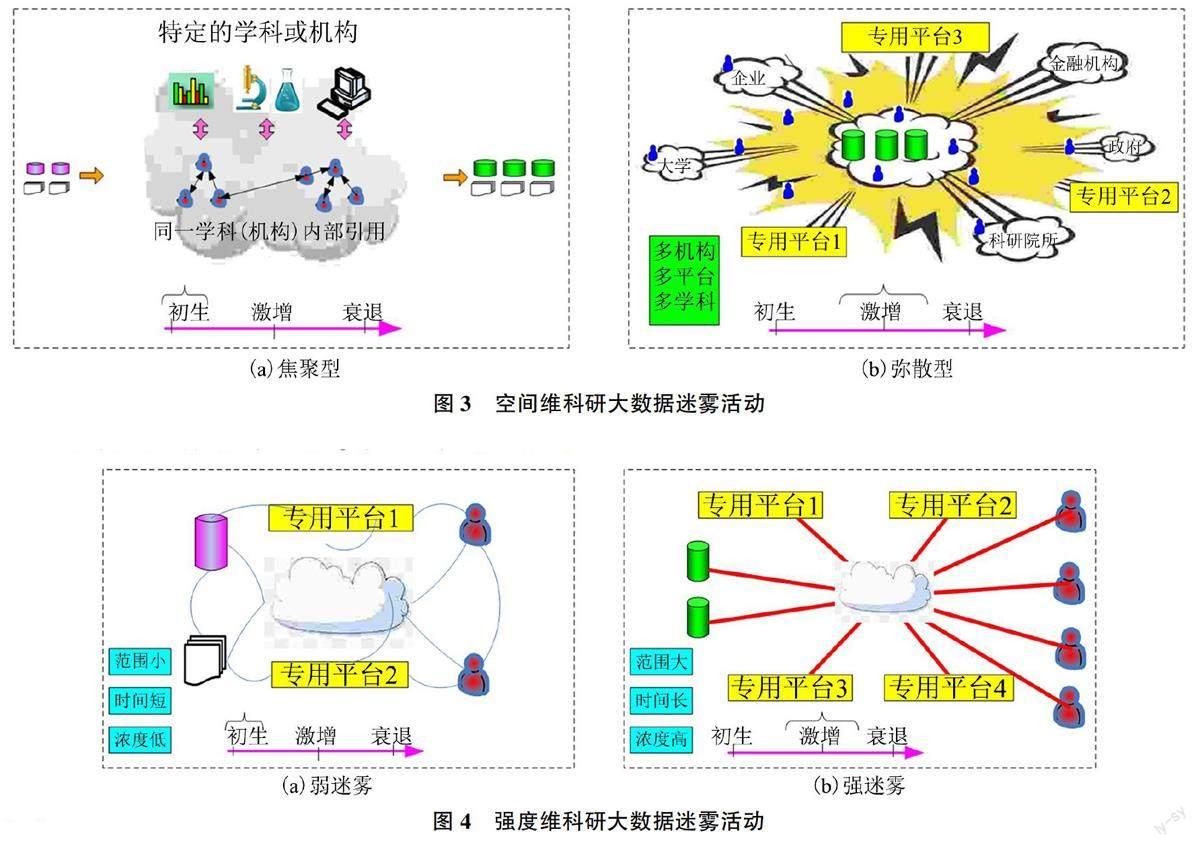
3.1.2空間維
結合SRBDF的派系性與全鏈性特征,在空間維上,可分為焦聚型迷霧和彌散型迷霧,如圖3所示:
1)焦聚型( Focus Type)是指SRBDF往往聚集于某一的領域,科研人員在自己所屬學科領域進行數據引用,生成迷霧的現象,本屬學科間的數據引用情況遠高于跨學科引用,如圖3(a)所示。焦聚型迷霧具有集中性(數據集中、領域集中、人員集中)的特征。例如,隨生物學領域的“丁香實驗”、醫學領域的“梅斯醫學”、經濟管理領域的“經管之家”等交流平臺的興起,產生的迷霧更為聚集,這是其派系性的典型體現。隨時間演化焦聚型迷霧在科研大數據生態系統中擴散開來,逐漸轉變為另一種類型。
2)彌散型(Diffuse Type)是指SRBDF逐漸擴散影響相鄰學科,造成跨學科影響的現象。如圖3(b)所示,彌散性迷霧以現代信息技術與相關政策漏洞為滋生土壤,在多機構、多平臺、多學科內傳播,具有范圍廣、速度快、災害性強的特點。在當今《科協系統深化改革實施方案》等鼓勵跨學科合作相關文件頒布的背景下,跨學科合作迸發出前所未有的新活力,但與此同時,彌散型迷霧也廣泛分散在了科研大數據生態鏈。其縹緲難以捕獲,體現了SRBDF的全鏈性特性。
3.1.3強度維
結合SRBDF波動性特征,在強度維度其可分為強迷霧與弱迷霧,如圖4所示:
1)弱迷霧(Infirm Fog)指“迷霧”影響范圍相對較小,迷霧濃度較低,對數據接收者的危害程度較淺的一種數據形態。對于釋放者來說,盡管其濃度及影響范圍較小,但對于錯誤數據接收者而言,弱迷霧型數據與可用科研數據更相近,因此在面對弱迷霧時更容易受其迷惑。但是因其影響范圍有限、危害程度較小,相對而言也較容易處理。
2)強迷霧(Strong Fog)指在科研大數據生態系統中影響范圍大、作用時間持久、危害程度較深的一種數據形態,此形態多出于濃霧期。對于釋放者來說,強“迷霧”的釋放能夠更加有效地干擾競爭對手,削減其實力。對于接收者來說,強迷霧難以防控,迷霧中處處存在風險,接收者長時間面對大量魚龍混雜的科研數據,易造成學科發展停滯。
3.1.4利益維
結合SRBDF災難性特征,在利益維度可分為趨利型和趨害型,如圖5所示:
1)趨利型(Profit Type)是指在科研個體(微觀)、科研機構或企業(中觀)、國家或地區(宏觀)等競爭的驅動下,以迷惑競爭對手提高自身競爭力為目的,以故意加大實驗誤差生產錯誤數據為手段,對于釋放者來說,造成的最終結果是有利的一種數據形態。如圖5(a)所示,迷霧釋放者通過釋放科研大數據迷霧干擾競爭對手,提高自身競爭力。趨利型迷霧對于釋放者來說具有可見、可防、可控的特點。
2)趨害型(Hasten to Harm Type)是指同是在競爭驅動下產生的,與趨利型相對的,對數據接受者來說可造成傷害的一種數據形態。如圖5(b)所示,趨害型相對于趨利型來說,只是接受主體不同,對于自身來說是趨害型的對于競爭對手來說有可能是趨利型的,但將會影響接收方自身決策分析,造成決策失誤。趨害型迷霧對數據接收者來說具有難捕捉、難評估、難控制的特點,繼而可造成災難性后果。
3.1.5繁育維
結合SRBDF派系性特征,在繁育維度科研大數據“迷霧”現象可分為雜育型和寡育型,如圖6所示:
1)寡育型( Oligonucleotides Type)是指只在特定的領域內出現的,易切斷阻隔的SRBDF類型。如圖6(a)所示,此類型具有學科單一(往往出現在高精尖領域亦或是冷門學科)、主體單一(在特定的科研人員范圍間傳播)、類型單一(數據類型單一,很少存在結構化、半結構化、非結構化數據混雜的情況)、數據一脈相承(科研大數據迷霧易溯源)、易控制的特點。
2)雜育型(Mixed Type)是指多學科、多領域、多人員、多地域的各類科研數據相互引用而出現的SRBDF。如圖6(b)所示,跨學科、跨地域、跨時空的科研人員在方法論、知識論、價值判斷等方面存在一定的差異,導致學科交流不通暢,從而產生SRBDF,此類迷霧更具有縹緲、懸浮的霧化性特征,且涵蓋知識范圍較廣,因此往往較難控制,易引發數據災難。
綜合以上分析知SRBDF組成類型多樣,在時間維可劃分為初生型、激增型、衰退型,在空間維可劃分為焦聚型、彌散型,在強度維可劃分為強迷霧、弱迷霧,在利益維可劃分為趨利型、趨害型,在繁育維可劃分為雜育型、寡育型。
3.2科研大數據迷霧的演化路徑分析
SRBDF在科研大數據生態系統中逐漸演化生成,如圖7所示,基于數據生命周期理論,以A機構醫療科研數據造假事件為例,以時間維度為主路徑綜合考慮利益維度、空間維度、強度維度、繁育維度對SRBDF的演化路徑進行分析。
3.2.1路徑節點一
1)從空間維看初生期SRBDF,其多以焦聚型呈現。例如在A機構注冊初期,科研數據樣本較少,“迷霧”還沒有大范圍傳播,此時的SRBDF焦聚現象較為明顯,即在初生期SRBDF往往是集中在醫療健康學科領域。盡管彌散現象在這一時期也會出現,但僅限于大規模的急性突發事件,但是這類情況爆發速度較快,初生期轉瞬即逝,將會很快步入下一時期——激增期。
2)從強度維看初生期SRBDF,因為其大部分處于萌芽時期,所以此時的迷霧較弱,如果短期內爆發高強度的迷霧,此時的迷霧數量定會發生激增,因此將此類型劃分至激增期,即研究認為科研大數據迷霧初生期強度較弱。
3)從利益維看初生期SRBDF,此階段是迷霧的計劃階段,A機構注冊便以盈利為主要目的,利益維充滿了人的主觀能動色彩,在迷霧誕生初期早已被人為籠罩上了利益的面紗,即便是A機構最終受到了自己釋放的迷霧的影響,但在迷霧釋放初期對釋放者來說是趨于有利的,并且在整個過程都是趨利向演化的。同理對科研人員及政府來說,在迷霧初生期便伴隨著擾亂其決策的目的,在整個演化過程都是趨害的。
4)從繁育維看初生期SRBDF,A機構的虛假科研數據還并未進行大量的傳播繁育,故很難直接判斷出此時的迷霧究竟是雜育型還是寡育型,對于前期多類型、多機構、多學科交叉產生的SRBDF可以將其直接劃分為雜育型,但現實情況中不乏在中期乃至后期才出現跨學科的科研數據,此時便需要將其重新分類。
3.2.2路徑節點二
1)從空間維看激增期SRBDF,在激增期極易出現迷霧大規模擴散的情況,此時A機構已與“北京煥一醫學檢驗實驗室”“北京普通醫學檢驗實驗室”成為房山區三大機構,科研數據量急劇增加,影響范圍逐漸增大,此時期的科研大數據迷霧多呈彌散型狀態,已擴散至醫療健康相關領域,即在短期迷霧數據會有突然爆發式增長的可能。
2)從強度維看激增期SRBDF,隨著該機構核酸檢測數量增加,與之產生的科研大數據數量勢必進一步增加,因此在激增期迷霧強度將會達到第一個峰值,此時的科研大數據迷霧最難控制,對科研人員與政府決策的危害性也最大。
3)從利益維看激增期SRBDF,此階段是干擾對手的主要時期,在激增期SRBDF的意圖已經基本暴露,對何種機構有利或是有害極易判斷,此時的A機構獲益頗豐,對于政府與科研機構而言,其決策判斷已受影響。
4)從繁育維看激增期SRBDF,隨A機構規模擴大,實驗員等崗位大規模招聘,此時的科研大數據已影響至監管部門、藥物生產商等,隨之產生的迷霧以雜育型為主。迷霧的爆發式增長,大部分迷霧形態逐漸明確,此階段的中后期迷霧是雜育型還是寡欲型已經基本確定。
3.2.3路徑節點三
1)從空間維看衰退期SRBDF,隨北京市公安局通報,衛健部門已吊銷A機構《醫療機構執業許可證》,彌散在整個科研大數據生態系統的迷霧逐漸回籠,彌散在邊緣學科或是弱相關學科的迷霧逐漸淡化直至消失,再次呈現焦聚的狀態(可聚集特定的學科、機構、地區),因此從空間維度看衰退期的迷霧,此時期的迷霧以焦聚型為主。
2)從強度維看衰退期SRBDF,因市場監管部門已立案查處,在此時期非核心迷霧逐漸消散,此時的迷霧空間覆蓋范圍逐漸縮小,在數據治理的作用下迷霧的災害性逐漸減弱,因此迷霧在衰退期強度逐漸降低。
3)從利益維看衰退期SRBDF,衰退期屬最終時期,是否提高了自身的核心競爭力、干擾了對手的決策,或者是否受迷霧影響造成決策失誤,從而影響了自己的競爭地位,其利益目的早已明確。科研大數據人員可準確判斷此時的“迷霧”是趨利型的還是趨害型,但在競爭雙方的僵持作用效果下,衰退期的迷霧盡管在逐漸變弱,但還未完全消失,因此在科研大數據迷霧衰退期仍是趨利型與趨害型兩種“迷霧”混雜。
4)從繁育維看衰退期SRBDF,此時期迷霧繁育能力降低,很少出現大范圍繁殖的情況,但前期因跨學科、跨機構、跨地域引用而產生了多種雜育型迷霧,并伴隨多代寡育型迷霧,科研大數據生態系統中雜育型與寡育型迷霧并存,在短期內難以完全消除。
3.3科研大數據迷霧機理分析
3.3.1生成機理
由SRBDF-M知,“迷霧”的生成需經歷初生期、激增期、衰退期3個階段,迷霧的生成機理是一個整體化的機體,其過程是一個動態復雜的過程,在迷霧生命周期內,生產者、傳播者、消費者、監管者等主體均有參與。對迷霧的生成機理進行闡述,有助于科研人員掌握其演化規律,走出“迷霧叢林”。因此,本文主要從利益機理(催生)、擴散機理(傳播)、管控機理(阻隔)3個維度結合迷霧生命周期,對其內在邏輯進行剖析,如圖8所示。
1)利益機理:科研大數據生態系統內部存在優質與劣質兩種類型數據,優質科研大數據可信度高、生產成本高、可利用價值高;劣質科研大數據(迷霧數據)可信度低、生產成本低、可利用價值低。初生期迷霧生產者(以營利性企業或數據生產商為代表)受利益驅使計劃制造大量的迷霧數據,此時數據類型單一,呈現為焦聚型的弱迷霧,在迷霧型數據流出且獲益后會進一步刺激迷霧的生產。監管者為保護消費者利益在迷霧出現后會介入進行監管。
2)擴散機理:激增期迷霧傳播者(數據共享平臺、數據中介組織、數據產商等)對迷霧進行擴散,消費者(高校、企業、科研機構等)對迷霧數據進行引用,此時的傳播者一部分來自于先前趨利的生產者,另一部分則是受擴散機理影響自發地擴散迷霧的消費者,迷霧擴散機理指的是受大量的迷霧數據的反復刺激,消費者對迷霧數據的鑒別產生自我懷疑,開始引用高迷惑性迷霧數據,使得迷霧數據量激增,此階段的科研大數據迷霧為數據類型復雜的彌散型強迷霧,隨數據量的激增,生產者收益增加,進一步刺激劣質數據產出。
3)管控機理:大量的迷霧數據流入科研大數據生態系統中引起監管者(政府監管部門等)注意,開始干預生產者行為,對迷霧數據進行管控,隨科研經歷的增加,科研工作者數據鑒別能力逐步提升,開始對迷霧數據進行剔除與舉報,生產者利益受阻,迷霧數據量逐漸減少,此時的迷霧呈現數據類型趨于單一的焦聚型弱迷霧特點。
3.3.2機理間的內在聯系
科研大數據迷霧催生因素多樣、生成過程復雜,但利益機理、擴散機理、管控機理并不是孤立存在的,內部具有一定的邏輯聯系,如圖9所示。
擴散機理與利益機理的關聯關系。消費者的策略選擇通常有消費與不消費兩種。生產者對高品質科研大數據通常有保留和流出兩種策略,對科研大數據迷霧通常有保留和流出兩種策略。因此在科研大數據生態系統中存在的4種數據流轉策略:第一種是高價優質科研大數據;第二種是低價優質科研大數據;第三種是高價迷霧數據;第四種是低價迷霧數據。在利益機理下,科研大數據生產者會向消費者索要高回報。當消費者選擇消費時,可能高價買到優質數據或迷霧數據,也可能低價買到優質數據或迷霧數據,此時存在迷霧擴散的可能;消費者的收益為數據價值與獲取數據成本的差值;當選擇不消費時,消費者的得益為0,此時不存在迷霧擴散的可能。
管控機理與利益機理的關聯關系。監管者對于生產者的各種行為存在監管與不監管兩種策略。當監管者在利益機理作用下,為降低監管成本,即松懈檢測時,存在優劣科研大數據混合。消費者在明確要付出較大成本獲取數據時的得益應該不小于不獲取數據的得益。由管控機理知,當監管者選擇監管松懈時,生產者流出迷霧數據,但當流出迷霧數據加大時,監管者會再次選擇監管嚴厲。當生產者提供優質數據時,監管者又會選擇監管松懈以減低監管的成本支出。
擴散機理與管控機理的關聯關系。監管者對數據質量嚴格監管時,生產者減少迷霧型數據的生產,消費者獲取迷霧數據的可能性降低,迷霧擴散的概率隨之降低。監管者對數據質量監管松懈時,生產者加大迷霧型數據的生產,更多的迷霧數據流轉到消費者的手中,加大了迷霧的擴散。
利益機理、擴散機理與管控機理的關聯關系。如果監管者嚴格監管科研大數據生態系統中數據流通行為,生產者會向消費者索要較低的報酬,消費者得益大于0時會選擇接受科研大數據迷霧;否則生產者索要高報酬,生產者高低報酬比例使消費者接受的得益大于不接受得益。在管控機理作用下,生產者若仍選擇流出迷霧數據,此時監管者將會實施系統內部混合策略。當監管者對于生產者所產數據檢測不到位時,消費者無法根據生產者對所放出的報酬要求來判斷科研大數據的優劣,此時迷霧擴散的概率加大。利益機理、擴散機理與管控機理分別發揮著催生、傳播、阻隔的作用,維持著科研大數據生態系統內部的動態平衡。
3.4科研大數據迷霧模型的應用分析
1)應用過程。第一步,確定對象。確定科研大數據所屬的領域及模型的運用者。不同領域甚至同一領域的科研決策者、一線人員以及科技政策制定者的關注側重點各有不同。第二步,從科研大數據庫中獲取相關數據。此步驟應注意科研大數據迷霧發現機制的實現問題(是對已知數據的判斷還是對未知數據的挖掘)。第三步,開展綜合分析。對科研大數據迷霧的類型、路徑、機理進行分析。從不同維度對科研大數據迷霧進行類型劃分,并探索其作用路徑及所處階段,為后續數據治理提供啟示。同時還應注意數據的格式問題以及人員間、人員與模型間的協同性問題。第四步,形成結論,即對科研大數據的評價結果。第五步,將結論反饋決策者,提交數據質量報告,為科研大數據治理提供合理化建議。
2)應用場景。SRBDF-M具有較強的實用性,在科研大數據庫建設、科研決策、科研大數據政策制定等場景中均可使用,具體分析如下:①應用場景一:科研大數據庫建設。隨著科技發展,科研人員對科研大數據的需求日益增加,科研大數據庫逐漸興起。將SRBDF-M引入到科研大數據庫建設,可起到優化數據存儲(通過SRBDF-M進行數據篩選分類,剔除劣質數據、無效數據、冗余數據)、加強數據保護(通過SRBDF-M進行迷霧型數據生產者溯源,減少劣質數據的產出,如已有的科技資源標識符與數字對象唯一標識符)、促進數據共享(數據共享成為科研大數據治理的重要任務之一,SRBDF-M可控制劣質數據的流入,提高科研效率,加快科研大數據流轉,同時保障數據權益使更多的科研成果參與共享)的作用;②應用場景二:科研決策。SRBDF-M有助于實時、全面、準確、專一的科研大數據清洗平臺的建設,科研人員通過SRBDF-M獲取高精度數據使科研決策更加科學。大數據時代背景下大量冗余數據使得科研決策環境發生變化,SRBDF-M可有效評價數據優劣、剔除冗余數據,更好滿足管理者決策需求,為領導層的決策制定提供高價值、高精度的支撐數據;③應用場景三:科研大數據政策制定。從2008年的《中華人民共和國科技進步法》到2015年的《促進大數據發展的行動綱要》,再至2018年的《科學數據管理辦法》,科研大數據的共享與利用不斷推進,然而由前文機理分析知科研大數據政策的制定過程是一個博弈行為,SRBDF-M可幫助政府分析系統內部其他主體的選擇行為,了解科研大數據發展態勢,提高科研大數據政策科學性。
4結語
1)科研大數據迷霧模型較好地描述了科研域迷霧數據出現、聚集、消散的演化過程。本研究提出了“科研大數據迷霧”的概念,并在科研大數據迷霧模型的建構與解構的過程中,從時間、空間、強度、利益、繁育等維度對科研大數據迷霧的類型、路徑與生成機理進行了詳盡剖析。研究得出科研大數據迷霧是指衍生于數據迷霧、貫穿于科研大數據生命周期,以科研域虛假、有毒、垃圾數據為重要組成部分,以全鏈性、不嚴格波動性、派系性、霧化性、災難性為基本特征,以初生型、激增型、衰退型、焦聚型、彌散型、強迷霧、弱迷霧、趨利型、趨害型、雜育型、寡育型為基本類型,降低科研大數據質量、干擾科研人員決策、引發數據災難進而擾亂科研大數據生態穩定的一類數據的總稱。
2)科研大數據迷霧模型的建構與解構對于科研大數據治理具有重要的理論價值與實踐價值,主要體現在以下幾個方面:
①對科研大數據治理目標的新安排。科研大數據迷霧概念的提出要求構建科研大數據治理優勢互補新布局,發現新優勢、發掘新動能、制定新規制、應對“迷霧”新問題,穩科技研究預期、利創新發展長遠,堅持科研大數據良性轉化,健全科研大數據治理體制,優化科研大數據資源配置,提升科研大數據創新效能,擴大國際科研大數據共享,以完成開放、共享、創新、多樣、穩定、持續的科研大數據生態系統建設新目標。
②對科研大數據內涵的新豐富。科研大數據迷霧生成模型是對科研域虛假、有毒、垃圾數據運行機理的深度闡釋。研究提出的“科研大數據迷霧”的概念具有整體性、原創性、前瞻性、引導性,以全局性的眼光看待整個科學研究過程中出現的迷霧數據,并第一次系統地對科研域虛假的、有毒的垃圾數據進行歸納與總結,豐富了科研大數據理論,可為后續相關研究提供理論依據。
③對科研大數據治理價值旨歸的新構造。宏觀層面:在科研大數據蓬勃發展的時代背景下,厘清“迷霧”生成機理,是大數據發展中至關重要的一環,有利于打破數據壁壘、加強科研數據共享、鞏固科研大數據生態系統的和諧穩定,是對國家大數據戰略的積極響應。中觀層面:在科學發展過程中,“迷霧”的存在將會成為科研進步的絆腳石,揭露其存在是科學發展的“清朗”行動。微觀層面:有助于幫助科研機構、科研人員、企業更好地了解科研大數據迷霧,有效規避風險,提高決策效率,從而增強自身核心競爭力。
④對科研大數據治理風險的新研判。以生態系統的眼光探究“迷霧”,具有系統性、整體性、協同性、時效性的特點。在當今安全赤字與治理赤字的大背景下,科研合作筑墻設壘、數據共享脫鉤斷鏈,是對治理體系、治理能力、治理水平的新挑戰。科研大數據共享過程中應兼顧外部風險與內部風險、傳統風險與非傳統風險、自身風險與共同風險。多階段、多主體、多維度分析迷霧類型及演化,為整體有序地開展科研大數據治理提供了新思路。
⑤對科研大數據治理舉措的新闡述。科研大數據迷霧概念的提出不僅要求健全科研大數據治理體系、增強科研大數據治理能力、提高科研大數據治理水平,還要求革新科研大數據治理舉措,夯實科研大數據生態穩定基礎。主要包括治理框架的革新:構建科研大數據安全應急框架,實現全科研域數據、人才、環境聯動,立體高效地應對科研大數據迷霧。治理體系的革新:對科研大數據生態進行一體化保護、系統化治理,構建面向“迷霧”特性的全局化、整體化的應對性的科研大數據治理體系。治理過程的革新:以科研大數據生態系統內外雙循環為輔助,遵循“迷霧”生命周期規律,多階段、多主體協同治理,注重迷霧治理過程的規范化、程序化,增強科研大數據生態鏈韌性。
3)盡管本文構建了科研大數據迷霧模型,提出了科研大數據迷霧的概念,并對其特性、類型、路徑、機理進行了詳盡的剖析,但如何應對科研大數據迷霧問題、維持科研大數據生態的和諧穩定,后續仍需深入討論。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
新課程·中旬(2016年9期)2016-12-01 12:56:28
商情(2016年40期)2016-11-28 10:54:26
青年文學家(2016年30期)2016-11-22 19:02:32
科教導刊(2016年27期)2016-11-15 22:36:28
光學精密工程(2016年6期)2016-11-07 09:07:19
科技視界(2016年18期)2016-11-03 22:02:50
企業導報(2016年9期)2016-05-26 22:20:27
