基于YOLOv5的機耕船雙目視覺障礙感知研究
2024-12-31 00:00:00陳泉淦陳新元曾鏞程志文
中國農機化學報 2024年7期
關鍵詞:機器視覺








摘要:為滿足機耕船自動駕駛功能,設計一套YOLOv5融合SGBM算法的機器視覺障礙感知系統。首先,以人、機耕船和農具為對象拍攝和收集圖片得到水田障礙數據集,將圖像輸入YOLOv5網絡模型迭代訓練得到最優權重,隨后將最優權重用于測試,并且與YOLOv4和Faster R-CNN網絡進行比較;將雙目相機拍攝的左右圖像輸入YOLOv5模型中進行檢測,將輸出的目標障礙檢測框信息經校正變換后用SGBM算法進行視差計算,完成對目標障礙的識別和深度估計。結果表明,YOLOv5的平均精度均值穩定在87.25%比YOLOv4高1.55%,比Faster R-CNN高4.04%,單幅圖像檢測時間為0.017 s比YOLOv4快0.081 s,比Faster R-CNN快0.182 s且模型大小僅為13.7 MB比YOLOv4小236.4 MB;在檢測機耕船、人和農具時,YOLOv5網絡模型的置信度分別為0.91、0.99、0.95。YOLOv5+SGBM的深度估計在2 m內,精度達到98.1%。基于YOLOv5和SGBM的水田深度估計,能滿足帶旋耕無人駕駛作業的機耕船實際需求。
關鍵詞:機耕船;障礙感知;機器視覺;YOLOv5;深度估計
中圖分類號:S24
文獻標識碼:A
文章編號:20955553 (2024) 070261
08
Research on binocular visual impairment perception of a cultivator boat based on YOLOv5
Chen Quangan1, 2, Chen Xinyuan1, 2, Zeng Yong1, 2, Cheng Zhiwen3
(1. School of Mechanical Automation, Wuhan University of Science and Technology, Wuhan, 430081, China;
2. Key Laboratory of Metallurgical Equipment and Control of Ministry of Education, Wuhan University of Science and
Technology, Wuhan, 430081, China; 3. Wuhan Huayou Tianyu Technology Co., Ltd., Wuhan, 430210, China)
Abstract:
In order to satisfy the automatic driving function of the boat tractor, this paper designed a set of YOLOv5 integrated SGBM algorithm machine vision obstacle perception system. Firstly, people, machine-tiller and farm tools were taken as objects to shoot and collect images to get paddy field obstacle data set. The images were input into the YOLOv5 network model for iterative training to get the optimal weight. Later, the most weight was used for testing and compared with YOLOv4 and Faster R-CNN networks. The left and right images taken by the binocular camera were input into the YOLOv5 model for detection. After correcting and transforming the output information of the target obstacle detection box, the SGBM algorithm was used for parallax calculation to complete the target obstacle recognition and depth estimation. The results show that the average accuracy of YOLOv5 is stable at 87.25%, 1.55% higher than that of YOLOv4, 4.04% higher than that of Faster R-CNN, and the detection time of a single image is 0.017 s, 0.081 s faster than that of YOLOv4. It is 0.182 s faster than Faster R-CNN, and the model size is only 13.7 MB, 236.4 MB smaller than YOLOv4. The confidence of the YOLOv5 network model is 0.91, 0.99 and 0.95 respectively when detecting the boat tractor, man and farm tools. The depth estimation of YOLOv5+SGBM within 2 m, and the accuracy reaches 98.1%. The paddy field depth estimation based on YOLOv5 and SGBM can meet the actual requirements of unmanned boat tractor with rotary tillage.
Keywords:
boat tractor; obstacles perception; machine vision; YOLOv5; depth estimation
0 引言
我國是一個盛產水稻的國家,在宜種水稻的田地中,多數為漚田、湖田和海涂田等。與旱田不同,其土地承壓能力差,土質稀軟[1],為了適應以上田地,機耕船應運而生。機耕船到現在已有60余年的歷史,不僅提高了水稻田的種植效率,也為沿海地區用機械法去除互花米草做出了貢獻[2]。機耕船雖然性能可靠,售價親民,但是其駕駛難度大且駕駛的危險系數高導致多數消費者購買后不敢駕駛,還需聘請專業的駕駛員,無形中增加了成本。據調查,多數機耕船駕駛人員反映機耕船在經過斜坡和田埂時最為危險,容易發生側翻和側滑,嚴重威脅到了駕駛人員的安全,且2011年以來機耕船基本沒有大的技術革新,已經越來越不適應現代農業機械的發展需求[3, 4],所以研發一款有自動駕駛功能的機耕船迫在眉睫。
隨著無人駕駛汽車的發展,用自動駕駛代替人工駕駛已成為一種趨勢。自動駕駛農機最重要的就是目標障礙識別[5, 6]和深度估計[7, 8]。自從2012年以來,卷積神經網絡以其具有能自主學習能力,分類準確率高的特點,在計算機視覺、語義識別等領域備受青睞。目標檢測算法分為基于區域生成的卷積神經網絡和對圖像整體生成的卷積神經網絡兩類。基于區域的CNN:其中查志華等[9]用Faster R-CNN實現田間紅提葡萄果穗的檢測,黃華毅等[10]將Fast R-CNN與無人機結合實現對病樹和枯死樹的識別;基于整體圖像的CNN:Shi等[11]提出了一款基于YOLOv的道路檢查站機器人系統,王淑青等[12]使用YOLOv完成對瓷磚表面缺陷的檢測,劉建政等[13]提出了一種基于SSD算法的一階段目標檢測器,提升了對小目標檢測的精度。在深度估計方面,齊繼超等[14]用單目相機與激光雷達融合的SLAM方法提高了定位精度與魯棒性,魏建勝等[15]使用YOLOv3與雙目相機建立了一個農業車輛障礙感知系統。其中單目視覺測距只有在移動情況下才能推測深度,并且深度值可信度并不高;激光雷達只能檢測掃描線以內的目標,對于水田和灘涂等不平整路況測量效果不理想;深度相機對于外界干擾十分敏感,更加適用于室內場景;雙目相機相較于以上傳感器,雙目相機利用兩部相機的視差計算得到深度信息,采用立體匹配算法提升測距精度并且能通過增大基線距離來增加測試距離,成本也相對較為便宜,更加適用于戶外中低速農機場合。
本文提出一種基于YOLOv5的機耕船障礙檢測方法,將檢測框中心點近似為障礙物,通過視差法將雙目相機左右鏡頭圖像坐標系中障礙物的視差值轉換為空間坐標系的目標深度距離,將機器視覺技術與機耕船結合,以提高其可靠性、安全性和效率性。
1 機耕船系統介紹
1.1 機耕船外形結構
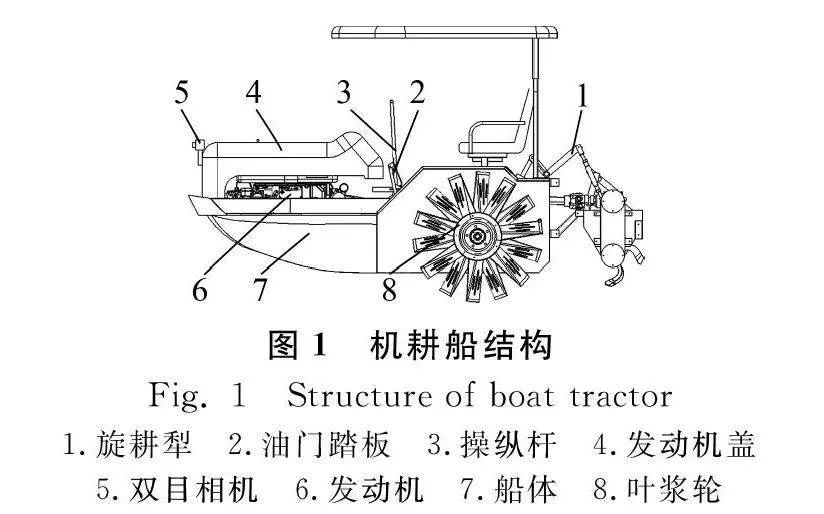
自動駕駛機耕船采用“浮式”原理,選用16~24 kW柴油機為動力源,全液壓驅動,其結構如圖1所示。在發動機蓋前方安裝雙目相機實時拍攝前方圖像,操縱桿負責控制機耕船的轉向,油門控制機耕船的速度,后載有旋耕犁,安裝與普通膠輪不同的葉槳輪增加在水田中的推進力。
1.2 機耕船操作系統介紹
機耕船點火啟動,雙目相機開始拍攝前面道路的實時圖像,再將圖像輸入YOLOv5模型進行檢測識別;判斷障礙物類別后,計算目標障礙物的深度信息;讀取計算到的深度信息,判斷是否超過預警值,超過就會松掉油門,推動操縱桿實現轉向;工作結束后,關閉點火開關,機耕船停止工作。機耕船操作流程如圖2所示。
2 YOLOv5檢測算法
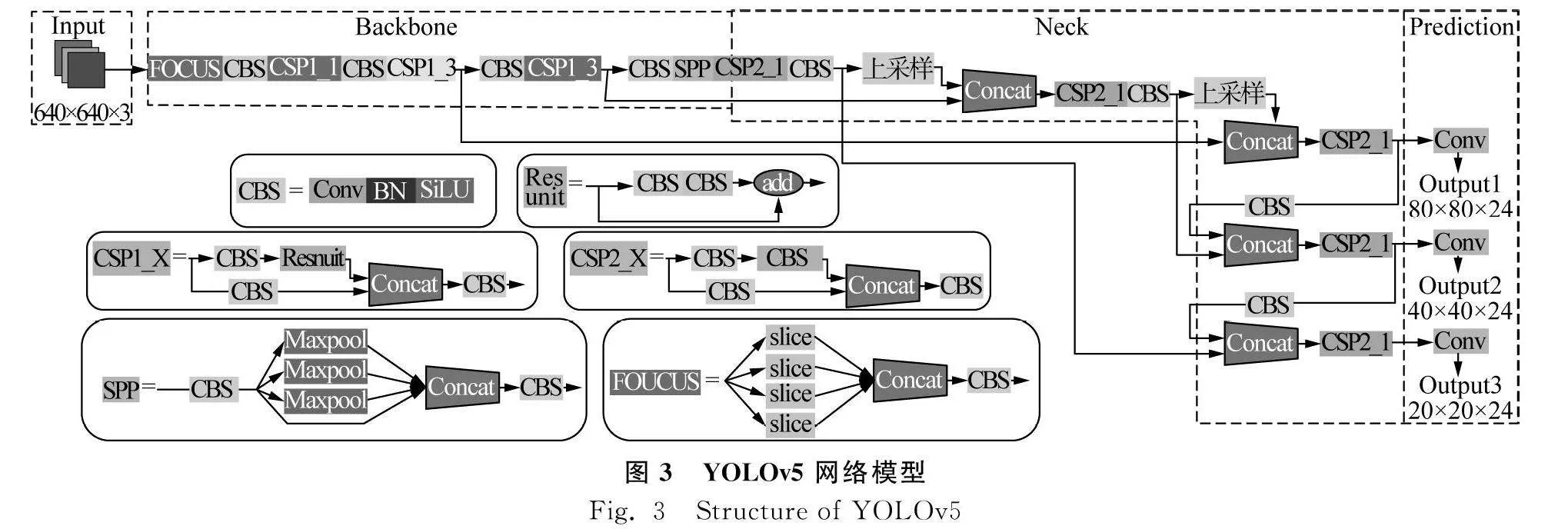
本文的應用背景為水田自動駕駛,更看重推理的速度,所以本文以YOLOv5s網絡為主。由圖3可以看出,YOLOv5s網絡由Input、Backbone、Neck、Prediction四個部分組成。
在輸入端包括Mosaic數據增強、自適應錨框計算和自適應圖片尺寸縮放。Mosaic數據增強法是將4張圖片通過隨機排布、縮放、裁剪的方式重新拼接,豐富數據集的同時還增加了網絡的魯棒性,減少訓練的時長。自適應圖片縮放能將任意尺寸的輸入圖像按一定的比例縮放成大小為640像素×640像素的固定尺寸圖像,對于非正方形輸入圖片,YOLOv5運用了改進letterbox函數,對原圖自適應添加最少的黑邊,改進后推理速度提升37%。相較YOLOv3和YOLOv4在計算圖像的初始錨框需要通過單獨的程序運行,YOLOv5則是將初始錨框的計算并入代碼,簡化了網絡訓練過程。
Backbone模塊由Focus和CSP結構組成。將輸入的原始分辨率為640×640×3的圖片輸入Focus中,通過切片計算后得到320×320×12 Feature map,經過32次卷積運算,得到320×320×32 Feature map,用上述的Focus結構可以減少參數計算和CUDA的內存。CBS模塊不同于之前的CBL模塊,激活函數由LeakyReLU改成了SiLU函數即Conv+BatchNormal+SiLU。CSP結構借用了CSP網絡思想,通過對特征圖像的提取,獲得豐富的信息,減少計算量并且增強梯度的表現。SPP模塊為空間金字塔池化,將任意大小的特征圖轉化為大小固定的特征向量,增加了網絡的感受野。
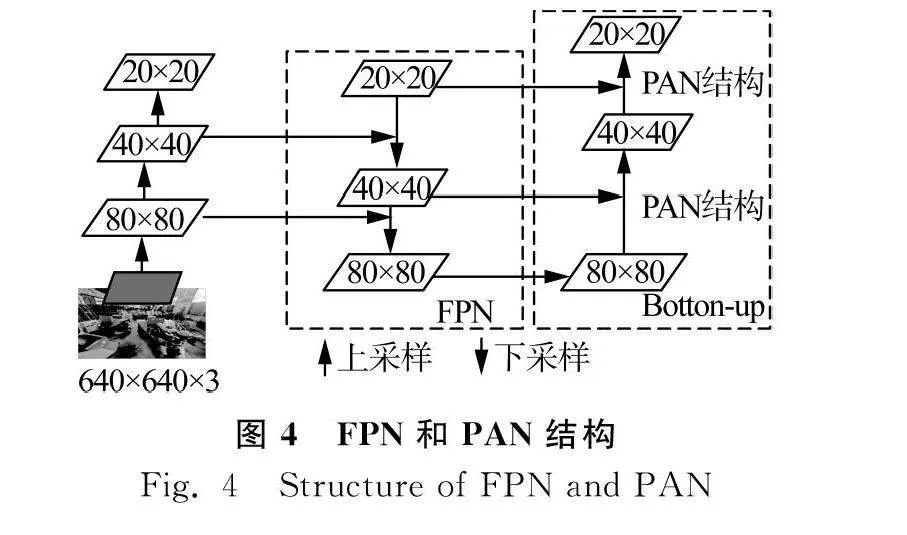
在特征融合階段,主要采用了FPN+PAN結構,其中FPN層負責將頂層豐富的語義特征傳往底層,PAN層負責將底層的精確定位信息傳往頂層,兩者互相補充既提高了模型預測框位置的精度又提高了預測框類別的準確度,如圖4所示。YOLOv5的Neck模塊采用CSP2結構,加強網絡特征融合的能力。
在預測輸出端,YOLOv5使用bounding box損失函數和NMS非極大值抑制。邊界損失函數用GIOU_Loss替換了以往的IOU_Loss,解決了IOU_Loss不能制可以消除多余的框,得到最佳的檢測框。非極大值抑制是通過計算候選錨框與目標類別置信度最高錨框的交集和并集得出交并比,若該值大于設置的閾值則放棄該錨框,該過程能消除多余的錨框得到最佳的檢測框。
3 雙目相機標定和深度估計
3.1 雙目相機深度估計原理
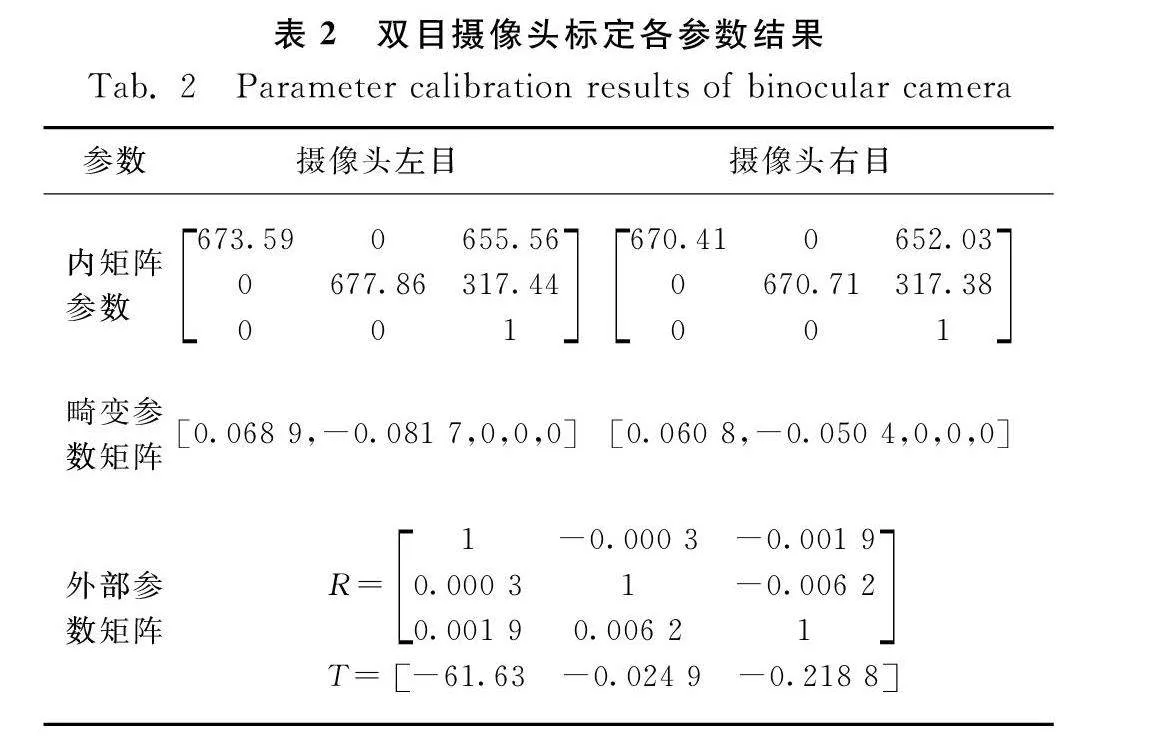
雙目相機立體成像模型如圖5所示,L和R為左、右照相機位置、O表示光心、I表示成像平面、C為攝像平面主點、f表示焦距、b為基線、P為目標點、PL和PR分別表示對應成像平面上的投射點、Z是目標值表示目標點的深度信息。PL在IL上的橫坐標為l,PR在IR上的橫坐標為r,則CLPL=l,CRPR=-r,PLPR=b-l-(-r),由三角形相似可知
Z=fbl-r=fbd
(1)
式中:
d——視差,d =l-r。
Z只與f、b、d有關,其中基線b和焦距f為定值,可由標定得出。因此,只要知道視差值d就可以得出P點的深度信息,以上就是視差法求深度信息的原理。但是在實際情況下很難使兩部相機的Z軸完全平行,且X軸的共線也不能保證,多數情況下兩部相機之間不但存在平移而且存在旋轉關系,當知道兩個相機坐標系的旋轉和平移關系后就可以將其轉換為理想狀態。因此,對于雙目視覺的標定不但需要確定兩部相機各自的內參矩陣和畸變系數,還要確定兩部相機之間的相對旋轉向量和平移向量。
3.2 相機坐標系轉換
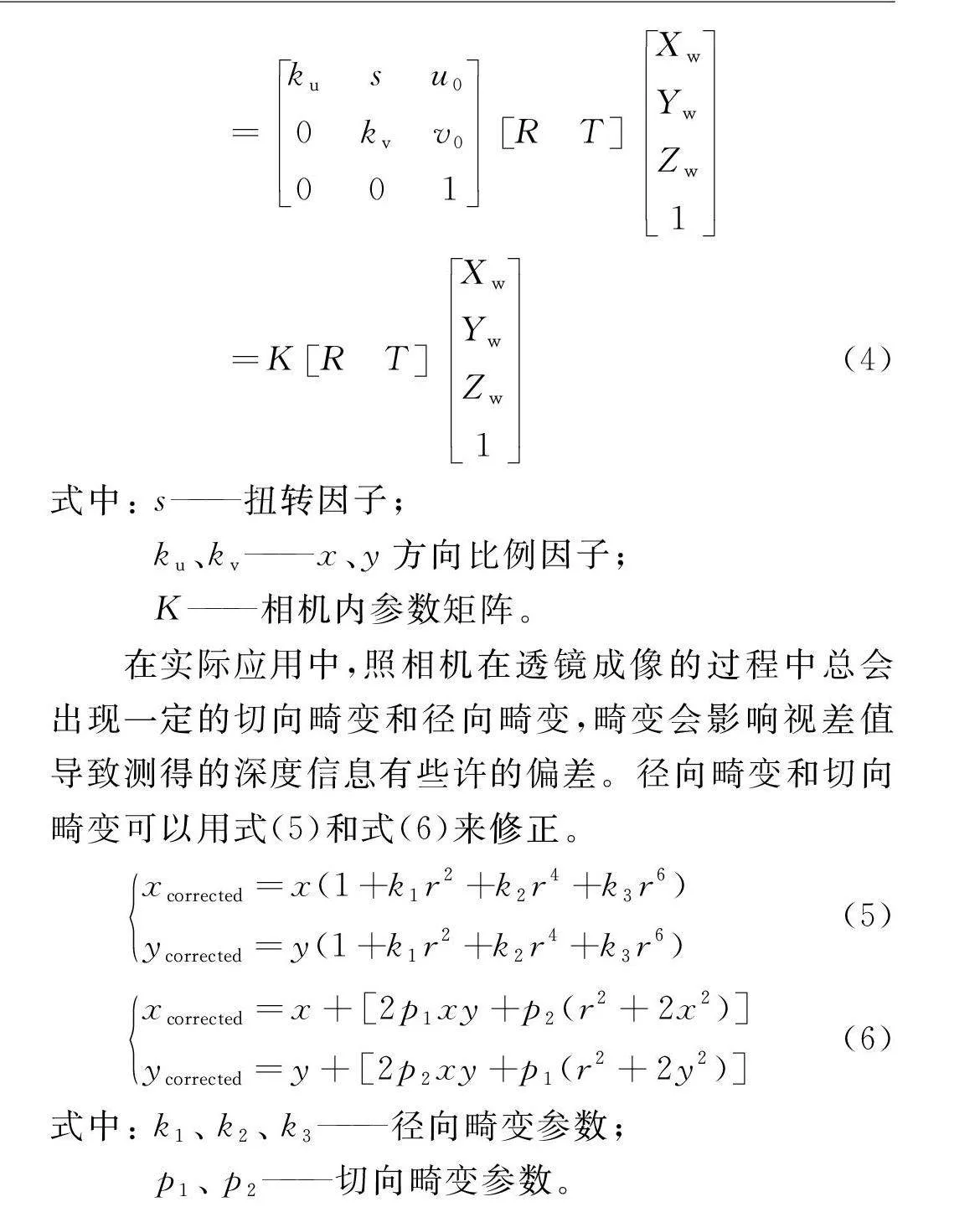
雙目視覺測距是將三維環境向二維平面映射的過程,具體過程分成了4個步驟,即世界坐標系與相機坐標系的轉換,相機坐標系與圖像坐標系的轉換,圖像坐標系與像素坐標系的轉換。像素坐標系是所拍攝圖像的M×N的陣列矩陣,橫縱坐標平行與成像面,坐標值為(u,v),單位為像素;圖像坐標系是描述了成像物體在成像面的位置的二維坐標系,坐標值為(x,y),單位為mm;相機坐標系以相機光心為原點,是描述被拍攝物體與攝像頭的空間位置的三維坐標系,坐標為(Xc,Yc,Zc);世界坐標系以左目光心為原點,是目標與相機之間的參考坐標系,坐標為(Xw,Yw,Zw),如圖6所示。
像素坐標系與圖像坐標系滿足式(2)。
x
y
1
=
dx0-u0dx
0dy-v0dy
001
u
v
1
(2)
世界坐標系與相機坐標系滿足式(3)。
Xc
Yc
Zc
=
R
Xw
Yw
Zw
+T
(3)
式中:
dx——
像素在圖像平面x方向的物理尺寸;
dy——
像素在圖像平面y方向的物理尺寸;
R——正交單位矩旋轉陣真;
T——三位矢量平移矩陣。
由式(1)~式(3)可得
Zc
u
v
1
=
fdxsu0
0fdyv0
001
RT
Xw
Yw
Zw
1
=kusu0
0kvv0
001
RT
Xw
Yw
Zw
1
=KRT
Xw
Yw
Zw
1
(4)
式中:
s——扭轉因子;
ku、kv——x、y方向比例因子;
K——相機內參數矩陣。
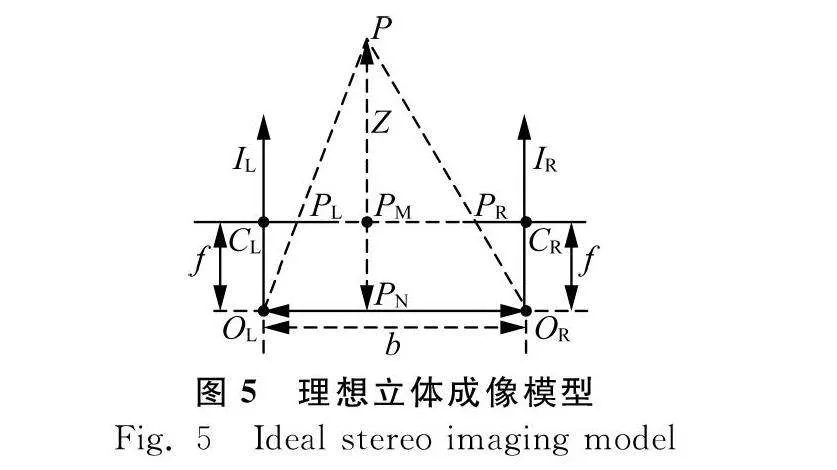
在實際應用中,照相機在透鏡成像的過程中總會出現一定的切向畸變和徑向畸變,畸變會影響視差值導致測得的深度信息有些許的偏差。徑向畸變和切向畸變可以用式(5)和式(6)來修正。
xcorrected=x(1+k1r2+k2r4+k3r6)
ycorrected=y(1+k1r2+k2r4+k3r6)
(5)
xcorrected=x+[2p1xy+p2(r2+2x2)]
ycorrected=y+[2p2xy+p1(r2+2y2)]
(6)
式中:
k1、k2、k3——徑向畸變參數;
p1、p2——切向畸變參數。
3.3 SGBM立體匹配算法
本文將目標檢測和深度算法SGBM融合進YOLOv5,在完成目標檢測的同時計算出深度信息,一次性完成對障礙物的定位和測距,流程如圖7所示。
先由左右兩部相機獲取圖像信息,將圖像分別輸入YOLOv5模型,檢測出障礙目標A,并且校正圖像后得到校正的目標圖像A,由SGBM算法計算出圖像的深度信息,最后得到雙目成像的深度模型。
SGBM[16]作為一種立體匹配算法,匹配效果遠勝于BM匹配算法,該算法通過選取每個像素點的視差,組成視差圖,設置一個全局能量函數見式(7),使每個像素點的視差值達到最優。
E(D)=
∑p[C(p,Dp)+∑q∈NpP1I(|Dp-Dq|=1)+∑q∈NpP2I(|Dp-Dq|gt;1)]
(7)
式中:
D——
當前的視差空間,即是該視差空間的能量函數值;
p、q——
圖像中的兩任意相鄰像素點;
Dp、Dq——該像素點的視差;
Np——
像素點p的領域空間,在二維圖像上,以最小的3×3區域為例,中心點p的相鄰像素為8,即有8個方向;
C(p,Dp)——
像素點p在視差為Dp時的匹配代價值。
I()——
邏輯函數,如果函數中的參數為真返回1,否則返回0。
其中最重要的兩個參數值為P1和P2,系懲罰因子,具體作用:當|Dp-Dq|=1時,P1作用;當|Dp-Dq|gt;1時,P2作用,一般P1和P2的值越大,視差越平滑,但是要求P2gt;P1。上述過程在二維圖像平面尋求最優解時屬于NP-hard問題,計算復雜,因此考慮動態規劃分解,降為8個鄰域方向的一維問題,見式(8)。
Lr(p,d)=C(p,d)+
min
Lr(p-r,d)
Lr(p-r,d-1)+P1
Lr(p-r,d+1)+P1
miniLr(p-r,i)+P2
-
minkLr(p-r,k)
(8)
式中:
r——
當前的方向,當視差為d時,Lr(p,d)即是當前r方向的最小代價值。
式(8)最后減去的一項minkLr(p-r,k)是為前一像素的最小代價值,目的是防止計算溢出。另外C(p,Dq)的計算如式(9)、式(10)所示。
C(p,Dp)=
min[d(p,p-d,IL,IR),
d(p-d),p,IL,IR)]
(9)
d(p,p-d,IL,IR)
=
minp-d-0.5≤P-d+0.5|IL(p)-IL(q)|
(10)
式中:
d——像素點p與q之間的視差。
從式(9)、式(10)可知,C(p,Dq)的最后取值為各部分中的最小值。通過式(8)完成對各方向計算之后再對所有方向進行累加,之后選取最小值作為最終的視差值。累加計算如式(11)所示。
S(p,d)=∑rLr(p,d)
(11)
對圖像中的像素遍歷上述步驟,即可獲得整個視差圖。
4 試驗
4.1 試驗環境
本次試驗的運行環境,CPU為Intel(R)i7-6700HQ-2.6 GHz,系統內存為16 G,GPU為NVIDIA GeForce GTX 1060 6 G,操作系統為Windows 10,加速環境為CUDA11.6,編程語言為Python3.8,深度學習框架為Pytorch1.7,雙目相機型號為HBV-1780-2 S2.0,基線60 mm,焦距2.1 mm。
4.2 YOLOv5網絡訓練
由于現今還沒有公開的水田障礙數據集,本文以水田常見障礙:人、機耕船、農具等作為檢測目標。在2022年,通過網上搜索下載和現場拍攝相關的障礙圖片,其中包括不同角度,不同場景和多目標混合的各種目標障礙物,保存格式為.jpg。采用Labelimg對上述數據集進行了標注,最終得到訓練集960張,驗證集120張,測試集120張。
本文深度學習網絡基于Pytorch學習框架,設置圖片輸入尺寸為640像素×640像素,初使學習率為0.003 2,權重衰減系數為0.000 36,迭代批次大小為16,動量為0.843,迭代次數為300次。
本文采用4個主要指標對YOLOv5訓練結果進行評估,分別為損失函數[17]、準確率P、召回率R、平均精度均值mAP,4個指標計算見式(12)~式(15)。
LGIoU=LIoU-AC-UAC
(12)
P=TPTP+FP
(13)
R=TPTP+FN
(14)
mAP=∑N1PRN
(15)
式中:
TP——實際為正樣本,檢測為正樣本的數量;
FP——實際為負樣本,檢測為正樣本的數量;
FN——實際為正樣本,檢測為負樣本的數量;
AC——
預測框和真實框的最小閉合矩形面積;
U——預測框和真實框的并集的面積;
LIoU——預測框和真實框的交并比;
N——該圖片不同類別目標的總和。
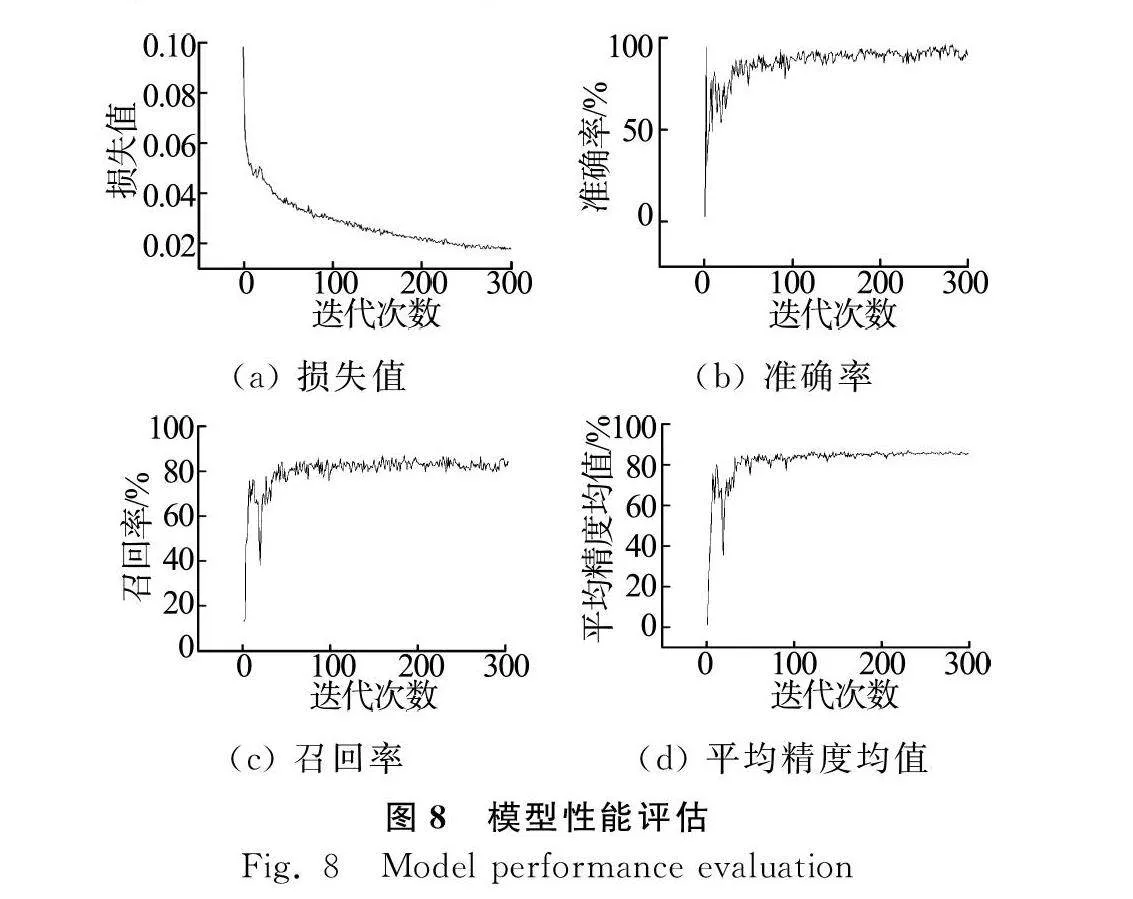
訓練完成,使用origin對結果進行可視化繪圖,得到損失函數、準確率、召回率和平均精度均值的線形圖如圖8所示。由圖8可得,損失值隨迭代次數下降,迭代次數達到50次時,損失值下降至0.036,同時準確率,召回率,mAP急劇上升達到了0.82,接下來的250個迭代,損失值持續下降至0.018,mAP則緩慢上升。最終在迭代300次時,準確率穩定在91.13%,召回率穩定在83.95%,平均精度均值mAP穩定在87.25%。將樣本與其他目標檢測算法包括Faster R-CNN[18]、YOLOv4進行試驗對比,結果如表1所示,與YOLOv4的檢測效果對比如圖9所示。
由表1可知,YOLOv5的mAP值為87.25%比YOLOv4高1.55%,比Faster R-CNN高4.04%,單幅圖像檢測時間為0.017 s,比YOLOv4快了0.081 s,比Faster R-CNN快0.182 s,且模型大小僅為13.7 MB,比YOLOv4小236.4 MB。
由圖9可知,以人、機耕船和農具作為識別目標,分別選取手拿農具的人和駕駛機耕船在水田工作的人為試驗目標,YOLOv4在檢測圖9(a)的人和農具時置信度只有0.89和0.90,YOLOv5的置信度則有0.99和0.95,分別比YOLOv4高了0.1和0.05;在檢測圖9(b)的駕駛中的機耕船時,YOLOv4對于人和機耕船的置信度分別為0.74和0.79,YOLOv5的置信度則有0.97和0.91,分別比YOLOv4高出了0.23和0.21,由此可見,YOLOv5的檢測效果明顯高于YOLOv4。
4.3 雙目相機標定試驗
本文利用MATLAB中的Stereo Camera Calibrator工具對雙目相機進行標定,用得到的標定結果做校正變換[19]。
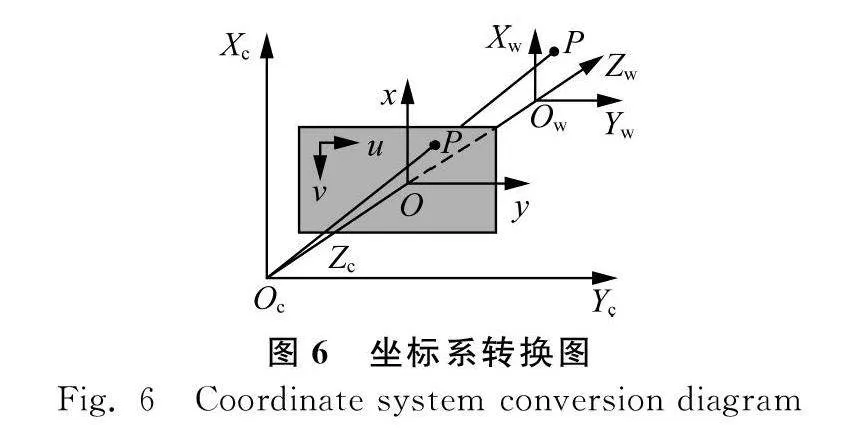
共拍攝20組標定圖像,除去誤差大于0.25的圖像后,剩余11組,經計算后得到雙目相機的標定結果如表2所示。
4.4 測距精度試驗
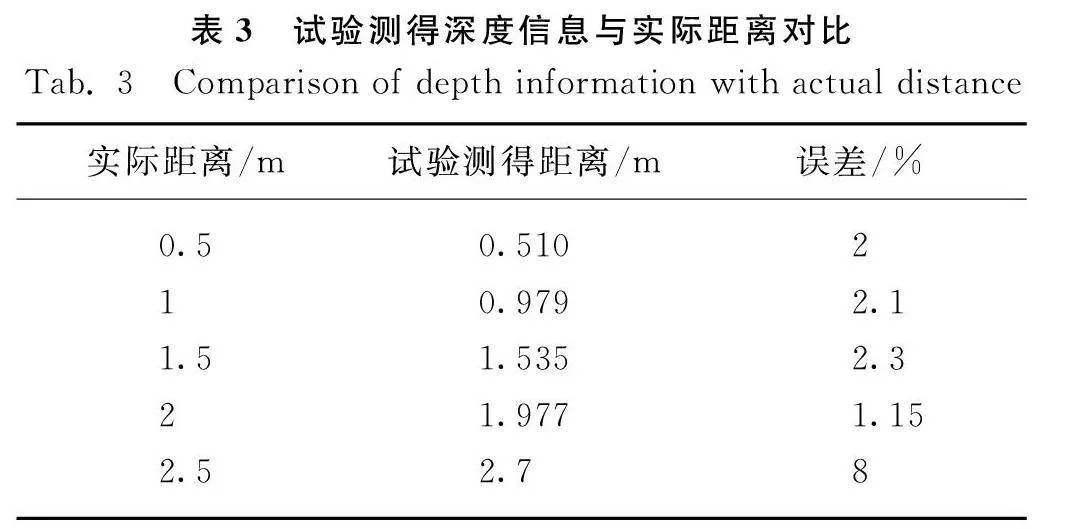
為測試上述方法的定位精度,設定人為障礙物,每間隔0.5 m進行一次距離檢測,人工采用紅外測距儀測量相機與人之間的深度距離(Z方向)。重復5次,將5次試驗的均值作為實測數據并且計算出相對誤差大小,得到結果如表3所示,第5次的試驗過程如圖10所示。
由表3可以看出,距離障礙物0.5 m處的誤差為2%,2 m的誤差值逐漸上升至2.1%,1.5 m的誤差值上升至2.3%,2 m處誤差為1.15%,當測試距離達到2.5 m時誤差值達到8%。
因機耕船搭載旋耕機工作時,為高負載的低速運動,運動速度在3 km/h左右,故測試距離只需達到1.5~2 m即可滿足實際需求,本文提出方案的測試距離在1.5~2 m處平均誤差值只有1.9%,故滿足具體要求。
5 結論
1)" 針對機耕船自動駕駛障礙物識別需求,本文提出一種基于YOLOv5s神經網絡對常見水田障礙進行訓練學習,經試驗測得該模型的理論平均精度均值穩定在87.25%,且檢測速度相對于其他主流檢測算法平均快0.1 s,基本可以滿足實時性要求。
2)" 將YOLOv5網絡結構融合SGBM算法的方法作為自動旋耕機耕船的測距系統。試驗表明,在2 m內平均誤差值只有1.9%,可以為無人駕駛機耕船提供可靠的目標障礙物深度信息,在后續的研究中可以選擇基線更長的雙目相機所測得的準確的深度信息范圍更大,嘗試使用AD-Census和PatchMatch算法進一步增強測距精度。
參 考 文 獻
[1]夏俊芳, 張國忠, 許綺川, 等. 多熟制稻作區水田旋耕埋草機的結構與性能[J]. 華中農業大學學報, 2008, 27(2): 331-334.
Xia Junfang, Zhang Guozhong, Xu Qichuan, et al. Research on the mechanized technology of rotary tillage and stubble-mulch for paddy field under multiple rice cropping system [J]. Journal of Huazhong Agricultural University, 2008, 27(2): 331-334.
[2]譚芳林. 機械法治理互花米草效果及其對灘涂土壤性狀影響研究[J]. 濕地科學, 2008, 6(4): 526-530.
Tan Fanglin. Effect of the method combining cutting with machine boat on controlling spartina alterniflora and its impact on wetland soil characteristics [J]. Wetland Science, 2008, 6(4): 256-530.
[3]王峰. 淺析現代農機裝備技術發展與農機維修工程[J]. 南方農機, 2022, 53(10): 165-167.
[4]許綺川. 加快湖北省機耕船產業發展的建議[J]. 湖北農機化, 2014(4): 9-11.
[5]姬長英, 沈子堯, 顧寶興, 等. 基于點云圖的農業導航中障礙物檢測方法[J]. 農業工程學報, 2015, 31(7): 173-179.
Ji Changying, Shen Ziyao, Gu Baoxing, et al. Obstacle detection based on point clouds in application of agricultural navigation [J]. Transactions of the Chinese Society of Agricultural Engineering, 2015, 31(7): 173-179.
[6]薛金林, 董淑嫻, 范博文. 基于信息融合的農業自主車輛障礙物檢測方法[J]. 農業機械學報, 2018, 49(S1): 29-34.
Xue Jinlin, Dong Shuxian, Fan Bowen. Detection of obstacles based on information fusion for autonomous agricultural vehicles [J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(S1): 29-34.
[7]李樂, 張茂軍, 熊志輝, 等. 基于內容理解的單幅靜態街道景圖像深度估計[J]. 機器人, 2011, 33(2): 174-180.
Li Le, Zhang Maojun, Xiong Zhihui, et al. Depth estimation from a single still image of street scene based on content understanding [J]. Robot, 2011, 33(2): 174-180.
[8]丁偉利, 李勇, 王文鋒, 等. 基于輪廓特征理解的城市道路圖像深度估計[J]. 光學學報, 2014, 34(7): 173-179.
Ding Weili, Li Yong, Wang Wenfeng, et al. Depth estimation of urban road image based on contour understanding [J]. Acta Optica Sinica, 2014, 34(7): 173-179.
[9]查志華, 周文靜, 吳杰. 基于遷移學習Faster R-CNN模型田間紅提葡萄果穗的識別[J]. 石河子大學學報(自然科學版), 2021, 39(1): 26-31.
Cha Zhihua, Zhou Wenjing, Wu Jie. Identification of red globe grape cluster in grapery with Faster R-CNN model based on transfer learning [J]. Journal of Shihezi University (Natural Science), 2021, 39(1): 26-31.
[10]黃華毅, 馬曉航, 扈麗麗, 等. Fast R-CNN深度學習和無人機遙感相結合在松材線蟲病監測中的初步應用研究[J]. 環境昆蟲學報, 2021, 43(5): 1295-1303.
[11]Shi Q, Li C, Guo B, et al. Manipulator-based autonomous inspections at road checkpoints: Application of faster YOLO for detecting large objects [J]. Defence Technology, 2022, 18(6): 937-951.
[12]王淑青, 頓偉超, 黃劍鋒, 等. 基于YOLOv5的瓷磚表面缺陷檢測[J]. 包裝工程, 2022, 43(9): 217-224.
Wang Shuqing, Dun Weichao, Huang Jianfeng, et al. Ceramic tile surface defect detection based on YOLOv5 [J]. Packaging Engineering, 2022, 43(9): 217-224.
[13]劉建政, 梁鴻, 崔學榮, 等. 融入特征融合與特征增強的SSD目標檢測[J]. 計算機工程與應用, 2022, 58(11): 150-159.
Liu Jianzheng, Liang Hong, Cui Xuerong, et al. SSD visual target detector based on feature integration and feature enhancement [J]. Computer Engineering and Applications, 2022, 58(11): 150-159.
[14]齊繼超, 何麗, 袁亮, 等. 基于單目相機與激光雷達融合的SLAM方法[J]. 電光與控制, 2022, 29(2): 99-102, 112.
Qi Jichao, He Li, Yuan Liang, et al. SLAM method based on fusion of monocular camera and Lidar camera and Lidar [J]. Electronics Optics amp; Control, 2022, 29(2): 99-102, 112.
[15]魏建勝, 潘樹國, 田光兆, 等. 農業車輛雙目視覺障礙物感知系統設計與試驗[J]. 農業工程學報, 2021, 37(9): 55-63.
Wei Jiansheng, Pan Shuguo, Tian Guangzhao, et al. Design and experiments of the binocular visual obstacle perception system for agricultural vehicles [J]. Transactions of the Chinese Society of Agricultural Engineering, 2021, 37(9): 55-63.
[16]Yu Zihao, Liu Jin, Yang Haima, et al. Three-dimensional surface reconstruction based on edge detection and reliability sorting algorithm [J]. Laser amp; Optoelectronics Progress, 2020, 57(24).
[17]Rezatofighi H, Tsoi N, Gwak J Y, et al. Generalized intersection over union: A metric and a loss for bounding box regression [C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[18]Ren Shaoqing, He Kaiming, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[19]Zhang Z Y. A flexible new technique for camera calibration [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(11): 1330-1334.
猜你喜歡
軟件導刊(2016年11期)2016-12-22 21:52:17
電腦知識與技術(2016年28期)2016-12-21 12:13:14
科技視界(2016年26期)2016-12-17 17:31:58
科技視界(2016年25期)2016-11-25 19:53:52
科技視界(2016年25期)2016-11-25 09:27:34
科教導刊(2016年25期)2016-11-15 17:53:37
軟件工程(2016年8期)2016-10-25 15:55:22
科技視界(2016年20期)2016-09-29 11:11:40
科技視界(2016年6期)2016-07-12 09:12:40
科技視界(2016年15期)2016-06-30 19:03:30
