基于主動學習貝葉斯算法在智能終端郵件過濾中的研究
2015-05-30 20:29:10朱強
儷人·教師版 2015年22期
關鍵詞:主動學習
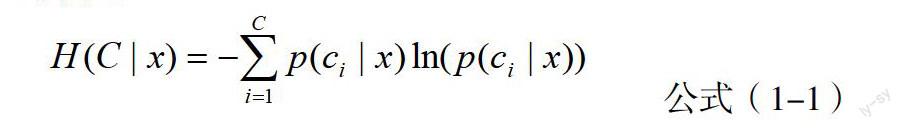
【摘要】對于貝葉斯算法,應該主動去了解,包括傳統算法和擴展算法。機器學習算法包括主動學習和被動學習兩種,樸素貝葉斯算法在樣本學習階段,一般采取被動學習,被動接受郵件集,這使得過濾器的過濾精度極大的依賴樣本的順序性。主動學習貝葉斯算法采取某種學習策略,主動從訓練集中挑選最合適的樣本加入學習模型,使模型參數更早達到最佳狀態,郵件過濾精度有所提高。
【關鍵詞】貝葉斯算法 被動學習 主動學習 郵件過濾精度
1 主動學習貝葉斯的原理
傳統的算法學習其實都是一些被動學習,用來學習的樣本材料都是經過處理的,它們的選擇往往是被動的,主要表現在所來學習的樣本都會被做上一些標注的,而且并不是所有的樣本都是真正獨立的,有一些可能并不獨立,只是被假定了獨立,雖然這樣也能達到學習的目的,但效果卻不是很好。而相對于被動學習來說,主動學習是一種真正的學習,它有以下幾個方面的特點:首先將使用很少量的帶有標注的學習樣本來訓練如何使用過濾器,在這個過程中也可以得到一些關于選擇怎樣的樣本對實驗結果更好的策略;然后就可以依照之前所得到的選擇策略從候選的樣本集中選擇出令人滿意的目標樣本;最后將這些認為最好的樣本放入過濾器中,如此往復的測試,這樣符合標準的樣本就被選出來了。當然最初對于樣本選擇的多少將決定著學習的速度,同時好樣本當然也意味著后來學習的質量。
2 基于最大最小熵的主動學習
熵有一個很明顯的性質就是,要想獲得最大值,就必須含有均勻分布的隨機變量。取值的均勻分布是參數無信息分布的一個條件,而熵取得最大值也是在這種情之下,也就是先驗分布。無信息意味著不確定性,意味著信息的空白,那是一種一無所知的感覺,是一種最不確定性情況的出現。而熵恰好就是這樣一種來表示不確定的方法。在這里,用來衡量目前過濾器實例樣本分類確定性的標準,就是關于類條件后驗熵,公式如1-1所示。
公式(1-1)
由于在選擇學習樣本時,總是選擇那些類條件概率相近的樣本,達到了均勻分布的目的,但是這樣的選擇方式也暴露了很明顯的兩個缺陷,它們對分類效果是有影響的。這兩個缺陷分別是單一的處理手段對于眾多問題的無力性和分類誤差的累積進而進行阻止的無效性。不確定樣本的選擇造成了一定的誤差,而累積的誤差將導致更大的誤差,導致了分類的無效性。這些是不確定性抽樣學習中產生的不可克服的問題,而要解決誤差問題是很難得,但是可以盡量減少誤差的產生,提高分類正確性,最大最小熵的處理辦法就是這樣的方法。那就是分別選出類條件熵最大和最小的候選樣本并將這兩個樣本加到數據池選出的樣本集中,然后加入過濾器,找出一些特別信息,同時可以確定的是類條件熵最小是一個較為確定的樣本集,使分類更加準確同時阻止誤差蔓延擴大。
3實現流程
最大最小熵主動學習的實現流程如下:
(1)從訓練集中隨機選擇一組郵件作為候選樣本集。
(2)對候選樣本集中的每一個樣本,利用公式1-1來計算樣本熵值的大小。
(3)取熵值最大和最小的兩個樣本加入到分類模型。
(4)從候選集合中刪去這兩個樣本。
4實驗結果及分析
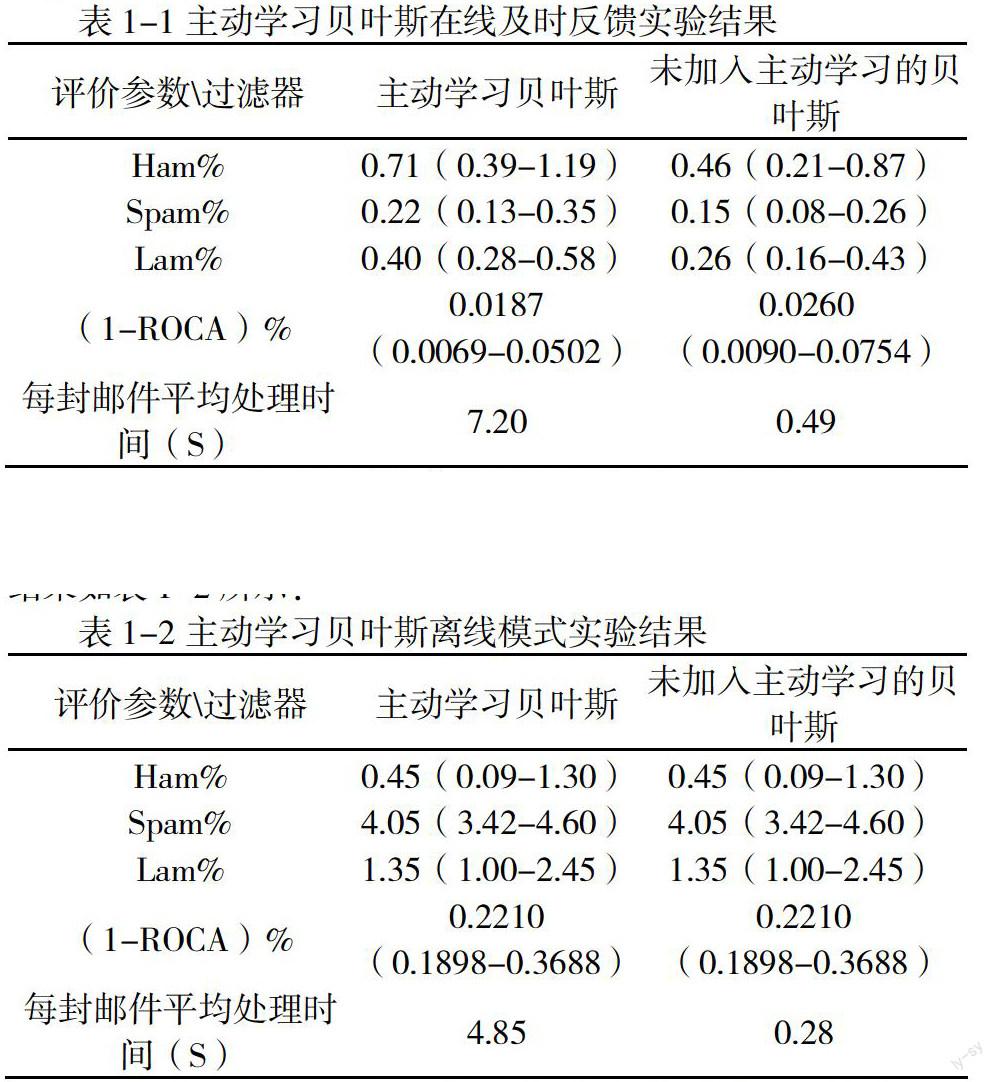
對主動學習過濾器本文進行在線和離線兩個模式下的過濾實驗。首先,在trec07p郵件集上進行在線及時反饋過濾,其過濾結果如表1-1所示。
在sewm 2008公開數據集上進行離線過濾,且取sewm 2008公開數據集前30000封進行訓練,后40000封進行測試,其實驗結果如表1-2所示:
從實驗結果可以看到,在在線立即反饋模式下,主動學習過濾器在(1-ROCA)%參數,都取得了更小的值。但是在離線模式下,過濾器是先進行過濾器訓練,再進行測試且這個過程沒有反饋學習,所以主動學習算法并不能起作用。而且另一方面,加入主動學習的過濾器在算法中加入了候選集計算熵的過程,使得郵件過濾效率比未加入主動學習學習的算法要低。加入主動學習的過濾器相對于未加入主動學習的過濾器來說,ROCA參數雖然有所降低,但是過濾速度太慢,每封郵件的處理時間比未加入主動學習過濾器10倍還要大。
【參考文獻】
[1]王輝.基于知識積累型的樸素貝葉斯垃圾郵件過濾算法研究 [D].湖南大學,2013
[2]劉建封,呂佳.融合主動學習的改進貝葉斯半監督分類算法研究[J]. 計算機測量與控制,2014(6)
(課題項目:吉首大學張家界學院重點科研課題項目資助。)
作者簡介:朱強,1983.3,男,湖南韶山人,本科學歷碩士學位,講師,研究方向軟件工程智能信息處理
猜你喜歡
文藝生活·中旬刊(2016年11期)2016-12-13 23:52:18
成才之路(2016年36期)2016-12-12 14:17:24
文藝生活·下旬刊(2016年11期)2016-12-12 09:49:36
新教育時代·教師版(2016年27期)2016-12-06 16:03:32
新課程·中旬(2016年9期)2016-12-01 11:51:59
中學課程輔導·教師教育(上、下)(2016年20期)2016-12-01 01:40:53
東方教育(2016年16期)2016-11-25 03:06:31
化學教與學(2016年10期)2016-11-16 13:29:16
人間(2016年28期)2016-11-10 22:12:11
計算機教育(2016年7期)2016-11-10 08:44:58
