
基于主動維保的城軌列車停車精度數據分析方法研究
2019-01-10 06:57:35李沃
科技視界 2019年35期
關鍵詞:數據分析
李沃
【摘 要】通過對城軌運營主動維保模式的研究,提出了一種列車停車精度的分析方法。該方法通過對停車精度歷史數據的分析和對比,可以精準定位和預判停車精度發生偏差的列車和站臺,以及停車精度發生偏差的嚴重程度。一定程度上達到了停車精度的預警,為主動維保提供信息化智能化的支持。
【關鍵詞】主動維保;停車精度;數據分析
中圖分類號: U239.5 文獻標識碼: A文章編號: 2095-2457(2019)35-0014-002
DOI:10.19694/j.cnki.issn2095-2457.2019.35.006
0 引言
隨著各行業的數據爆發增長,傳統的數據處理技術已經不能夠滿足業務的要求,信息行業隨之推出的各種針對海量數據處理的技術-大數據技術。大數據技術經過幾年的發展已經成為成熟的技術,最初在金融行業應用,現在已經擴展到了各行各業。在大數據技術的基礎上,國家層面提出了智慧城市的發展方向。交通是城市運轉的重要組成部分,其中的軌道交通每時每刻都產生大量的運行數據。數據規模已經達到了大數據的標準,可以應用大數據技術對軌道交通的數據進行分析處理。停車精度時ATO(列車自動駕駛系統)所采集的重要的數據,是關系到軌道運營安全的關鍵數據,通過大數據技術對停車精度數據進行分析,可以對停車精度趨勢進行預測,綜合提升軌道運營和維護的水平。
1 研究背景和意義
車停車精度是城軌列車運行時的關鍵指標,停車精度的準確性,關系到列車乘客上下車速度,列車制動性能等指標[1],關系到行車安全和列車的運載能力,停車精度頻繁發生過標,欠標或者停車精度不穩定的情況,會導致列車頻繁進行自動運行調整,增加了ATO系統的負擔,增加了軌道運營的風險。列車停車精度數據是通過ATO系統實時采集上來[2],以支撐列車和信號設備的實時監測系統的顯示,但是目前建設的線路對這些數據的利用程度有限,主要包括以下幾方面:
(1)數據多作為歷史數據存儲起來,沒有進一步的整理和挖掘。
(2)數據格式繁多,維度不統一難以支撐數據分析。
(3)用戶和供應商對數據本身價值的認識程度不高。
(4)用戶只關注停車嚴重過標和欠標的情況,不關注整體列車停車精度的變化情況以及變化趨勢。
所以有必要通過對歷史數據的研究來發掘數據的價值,通過歷史數據的分析得出有趣的趨勢和預警的結論,從未提升運營和維護的水平,提升運維的主動性。
2 主動維保模式介紹
城市軌道交通系統主動運維決策支持技術是指一系列能夠讓城市軌道交通系統由被動運維(定期、事后維護保養)變事前基于系統狀態進行運維決策的技術,包括實時監測、關鍵信息特征識別、故障演變規律、狀態評估預警等一系列的技術[3]。傳統的運營的維保工作主要是基于線路和列車設備發生的具體故障來進行,屬于故障修的范疇。主動運維技術應用到軌道運營和維保工作當中后,會整體提升軌道運營維護的水平,將故障修全面提升到狀態修,提升整體城軌運維的自動化和智能化水平,將維保工作由被動轉化為主動。
3 列車停車精度介紹
停車精度是由列車自動停車控制,作為ATO系統的一項關鍵技術。為保證乘客安全,現在越來越多的站臺都帶有屏蔽門[4]。停車精度不準確會對乘客上下車造成影響,還會對列車的通信造成影響,嚴重影響城軌列車的運行效率,還會影響乘客的上下車,從而降低交通系統的運行效率。列車標準的停車精度設定的范圍為±30cm,列車ATO系統會根據列車和環境的一系列參數和因素,去調整列車制動的精確性,從而保證列車停車精度的準確性。當列車出現了不準確的停車精度記錄時候,說明ATO系統在制動控制方面出現了誤差。然而更多的時候列車停車精度是在標準的范圍之內,但是停車精度數值會出現周期性或者規律性的變化,具有偏離標準值的趨勢,這種變化就要通過數據分析的方法去研究分析,得出一定的結論,在列車停車精度出現偏差之前,發現其趨勢,及時檢修維護,達到主動維保的目標。
4 大數據分析方法
大數據分析典型的分析方法的基礎都是通過數據比較而進行的,經典的算法有以下幾種,聚類分析,關聯分析,矩陣分析,多維度分析等。其中的聚類分析是大數據分析眾多方法當中,使用的最為廣泛的一種分析方法,該方法可以將各種零散不連續的數據通過數據之間的距離進行科學的分類,每一類數據都具備相同的特性[5]。
對這些歷史的設備狀態數據進行數據分析可以得到許多有趣的結果。聚類分析是數據分析方法中發展比較早,相對成熟的方法,它將一個數據集合按照空間距離分為幾個不同的子集合,是一種經典的分類算法。該算法的原理是隨機選定子集的中心點,然后計算集合中每個元素之間的相對距離,通過不斷的迭代和計算,調整每個子集的中心點,將每個離中心點空間距離最近的元素形成新的集合,直到子集不再發生變化,從而形成分類的子集,也就是最終的聚類。
5 停車精度大數據分析方法研究
ATO系統是一個全自動駕駛系統,系統在運行過程中會輸出各種運行過程中的狀態值。狀態值包含了,速度,牽引,制動,停車精度,開關門,司機駕駛等各種狀態值信息。這些狀態值信息中有一部分信息具備都離散的特點,是適合做聚類分析的樣本數據。聚類分析是數據分析當中最為有效的一種分析方法。該方法可以通過數學的方式對樣本進行科學分類,具有相似性的樣本會聚集在一類。通過聚類分析很快就可以明確數據樣本當中所具備的群組,然后再對每個群組進行有效的分析,可以對一類問題進行統一的定位和處理。
大數據聚類分析的過程以2017年9月16日到2017年10月16日MSS系統采集上來的ATO系統識別的停車精度數據來說明問題。該數據的采集地點是北京7號線全線站臺的停車精度,時間跨度為一個月,共計采集的樣本數據為149342條數據,數據量近15萬條數據,適合初步進行大數據分析的數據規模。
數據中針對停車精度包含了三個維度的屬性。分別為停車時刻,車輛號和站臺三個屬性。可以針對這三個屬性進行數據分析。
首先通過K-MEANS算法對停車精度的采集數據進行分類,根據維保經驗,將停車精度的聚類分析深度定義到8個群組。經過10次迭代計算,最終得到了8個群組。分類結果中可以得出聚類分析已經可以將樣本劃分為8個群組,所有的樣本都是有效的樣本,沒有的無效樣本。樣本聚類過程成功,說明停車精度數據確實在特定的條件下,存在不同程度的數據聚集。
將樣本數據帶入群組當中。得出每一個群組的中心點。中心點可以簡單理解為每一組數據的二維平均值。計算結果為:1號樣本,中心點為66.47,樣本數量為36個;2號樣本,中心點為1.12,樣本數量為7737個;3號樣本,中心點為-16.06,樣本數量為71979個;4號樣本,中心點為-9.28,樣本數量為34714個;5號樣本,中心點為32.45,樣本數量為622個;6號樣本,中心點為-22.7,樣本數量為31381個;7號樣本,中心點為2633,樣本數量為7737個;8號樣本,中心點為125.89,樣本數量為240個。計算完成樣本的中心點以后,可以明顯看出有兩個群組是不正常停車點的狀態,分別是:
1號樣本,中心點為66.47,樣本數量為36個。
8號樣本,中心點為125.89,樣本數量為240個。
根據過標的標準,這兩個群組樣本數據已經嚴重的過標了,雖然都是嚴重過標,但是經過數據分析以后,嚴重過標的數據形成了兩個群組中心,所以極有可能是由于兩種原因引起的過標數據。這樣就需要針對兩個數據樣本做進一步的維度分析一確定問題的根源。
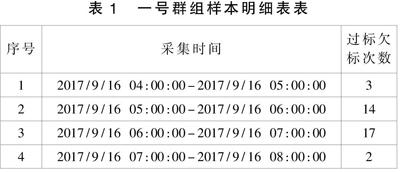
表1 一號群組樣本明細表表
因為1號群組的樣本數據不多,所以可以通過直接觀察數據的方法進行問題的排查,經排查,車號,日期和站臺數據都沒有明顯的集中,經過對數據的仔細比對以后,發現出現問題的時間都集中在早上的5點-7點。這樣就發現了問題的規律。可以給維護人員和設備研發人員發出明確的關注信號,要其關注每天早上5點-7點之間的列車制動數據和停車精度數據,以分析停車精度出現少量過標的問題。
8號樣本的中心點是125.89,其樣本數量為240個。這個樣本的數據量很大,而且125.89的停車精度也說明了停車過標問題極為嚴重,一定是需要重點排查和解決的問題。通過數據分析和對比,其他站臺的過標欠標次數都是3個以內,焦化廠下行站臺過標次數為220次。
通過智能化的分析,最終在站臺維度上看到了問題的發生集中在焦化廠下行站臺。
6 總結
通過對停車精度數據進行相應的數據分析,可以快速定位停車精度出現偏差的位置和時間,極大程度上提高了城軌運維的主動性,為主動運維提供了有效的數據支持。
【參考文獻】
[1]羅巖.預測控制在列車自動駕駛系統中的應用研究[D].上海交通大學,2015.
[2]侯贊.ATO系統綜合性能評價與列車多目標優化操縱方法研究[D].北京交通大學,2012.
[3]蔣益沖.軌道交通電源網管監控系統設計與開發[D].西南交通大學,2017.
[4]陳東.城軌列車停車控制算法及仿真研究[D].蘭州交通大學,2018.
[5]游麗平,陳德旺,陳文,劉林.聚類集成技術在地鐵站點類型研究中的應用[J].小型微型計算機系統,2019,40(01):236-240.
猜你喜歡
職工法律天地·下半月(2016年10期)2016-11-30 11:52:57
商情(2016年40期)2016-11-28 11:28:07
商(2016年32期)2016-11-24 17:39:41
科技資訊(2016年18期)2016-11-15 18:05:53
考試周刊(2016年84期)2016-11-11 23:57:34
科技視界(2016年18期)2016-11-03 22:51:40
體育時空(2016年8期)2016-10-25 18:02:39
現代經濟信息(2016年19期)2016-10-20 17:46:29
中國科技博覽(2016年18期)2016-10-19 10:30:11
中國市場(2016年36期)2016-10-19 04:31:23
