Levelt 的言語產(chǎn)出模型及其對外語教學的啟示
2015-09-10 07:22:44吳頻
考試周刊
2015年64期
關鍵詞:啟示
吳頻
摘 要: 語言理解是聽者或讀者接受別人的語言刺激,把聲音或文字轉化成意義的過程,包括語言感知、詞匯提取、句法和語義分析、推理等過程。而語言生成則是說話人或作者把意義轉換成聲音或文字的過程。語言生成包括口頭言語生成和書面語生成。本文主要介紹Levelt的言語產(chǎn)出模型及其對外語教學的啟示。
關鍵詞: 言語生成 產(chǎn)出模型 外語教學 啟示
1.引言
語言理解(language comprehension)是聽者或讀者接受別人的語言刺激,把聲音或文字轉化成意義的過程,包括語言感知、詞匯提取、句法和語義分析、推理等過程。(董燕萍,2005)語言生成(language production)則是說話人或作者把意義轉換成聲音或文字的過程(同上)。語言生成包括口頭的言語生成和書面的語言生成(同上)。
心理語言學家對日常言語或出錯言語進行觀察分析,推導研究言語生成機制。1971年,以Fromkin為代表的心理語言學家首次提出看言語生成的典型模型——串行模型(Gleason&Ratner,1998: 328-331; 轉引自董艷萍, 2005)。與之相對另一個模型則把語言生成看成在個個不同層面同時發(fā)生的過程,該模型被稱之為并行模型或連接主義模型(Gleason&Ratner,1998: 337-338; 桂詩春,2000:547-549;轉引自董艷萍, 2005)。Levelt (1989) 的模型則同時具備這兩種模型的特點。本文主要介紹Levelt的言語產(chǎn)出模型及其對中國英語學習者的教學啟示。
2.Levelt言語產(chǎn)出模型
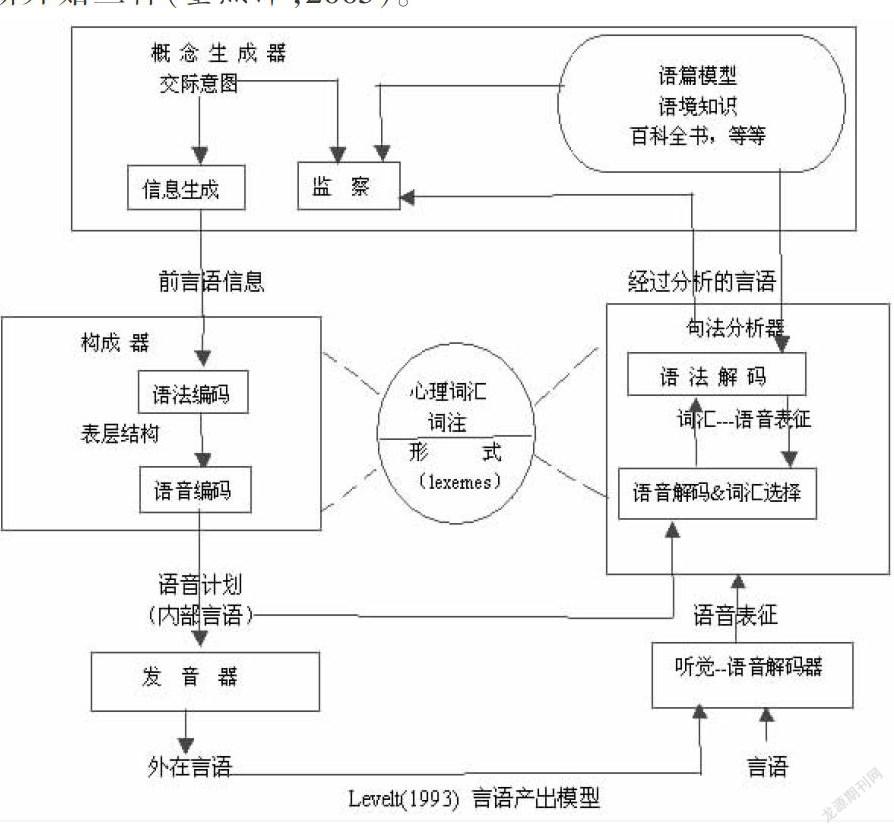
Levelt(1989,1993,1999)的言語生成模型主要由三個水平的表征關系構成的:概念層、詞目層和詞匯形成層(劉春燕, 2009)。該產(chǎn)出模型主要由五個成分組成,即概念形成器(conceptualizer)、構成器(formulator)、發(fā)音器(articulator)、聽覺語音解碼器(acoustic-phonetic processor)和句法分析器(parser)。……
登錄APP查看全文
猜你喜歡
人間(2016年26期)2016-11-03 19:19:44
人間(2016年26期)2016-11-03 17:46:10
人間(2016年26期)2016-11-03 16:30:18
青年文學家(2016年27期)2016-11-02 17:39:59
戲劇之家(2016年19期)2016-10-31 17:28:08
體育時空(2016年8期)2016-10-25 19:57:28
現(xiàn)代經(jīng)濟信息(2016年19期)2016-10-20 15:41:31
中國市場(2016年36期)2016-10-19 04:36:03
中國市場(2016年35期)2016-10-19 03:28:23
中國市場(2016年35期)2016-10-19 03:01:16
