GFS系統架構及設計要點
2020-06-08 17:18:53孫偉
中國電氣工程學報 2020年1期
關鍵詞:設計策略
摘要:本文主要闡述關于分布式文件系統GFS,它是一個可擴展的分布式文件系統,用于大型的、分布式的、對大量數據進行訪問的應用。通過詳細介紹其一致性模塊以及讀寫流程,針對GFS的大塊的邏輯和設計理念及相關要點都進行了詳細的分析。
關鍵詞:云儲存系統;GFS系統架構;設計策略;
一、GFS設計思路
1.組件/機器失效
GFS包括幾百甚至幾千臺普通的廉價設備組裝的存儲機器,同時被相當數量的客戶機訪問。GFS組件的數量和質量導致在事實上,任何給定時間內都有可能發生某些組件無法工作,某些組件無法從它們目前的失效狀態中恢復。例如谷歌遇到過各種各樣的問題,比如應用程序bug、操作系統的bug、人為失誤,甚至還有硬盤、內存、連接器、網絡以及電源失效等造成的問題。所以,持續的監控、錯誤偵測、災難冗余以及自動恢復的機制必須集成在GFS中。
2.谷歌處理的文件都非常巨大。(大數據):
這點跟NEFS的場景既有相似性又不完全一致,NEFS上層對接的是NOS對象存儲,基本都是大量的小文件(100MB以下),總體量比較大,對象個數比較多,因此也需要考慮元數據管理的成本,因此NEFS采用了小文件合并的設計思路(不詳細展開)。
谷歌系統中數GB的文件非常普遍。每個文件通常都包含許多應用程序對象,比如web文檔。當我們經常需要處理快速增長的、并且由數億個對象構成的、數以TB的數據集時,采用管理數億個KB大小的小文件的方式是非常不明智的,盡管有些文件系統支持這樣的管理方式。因此,設計的假設條件和參數,比如I/O操作和Block的尺寸都需要重新考慮。
3.絕大部分文件的修改是采用在文件尾部追加數據,而不是覆蓋原有數據的方式。(讀寫模型:順序寫,大部分順序讀,小部分隨機讀):
對文件的隨機寫入操作在實際中幾乎不存在。一旦寫完之后,對文件的操作就只有讀,而且通常是按順序讀。大量的數據符合這些特性,比如:數據分析程序掃描的超大的數據集;正在運行的應用程序生成的連續的數據流;存檔的數據;由一臺機器生成、另外一臺機器處理的中間數據,這些中間數據的處理可能是同時進行的、也可能是后續才處理的。對于這種針對海量文件的訪問模式,客戶端對數據塊緩存是沒有意義的,數據的追加操作是性能優化和原子性保證的主要考量因素。
4.應用程序和文件系統API協同設計,簡化對GFS的要求(靈活性):
例如一致性模型要求放松了,這樣就減輕了文件系統對應用程序的苛刻要求,大大簡化了GFS的設計。并且引入了原子性的記錄追加操作,從而保證多個客戶端能夠同時進行追加操作,不需要額外的同步操作來保證數據的一致性。
二、GFS接口:
GFS提供了一套類似傳統文件系統的API接口函數,文件以分層目錄的形式組織,用路徑名來標識。GFS支持常用的操作,如創建新文件、刪除文件、打開文件、關閉文件、讀和寫文件。但是要理解一點:文件塊被存儲在linux硬盤上,GFS只是一個管理器而已,這些文件操作API也只是個對這些抽象文件的管理而已。也就是說GFS層級比底層文件系統以及虛擬文件系統層次要高。注:這點跟NEFS也比較像,NEFS也是對文件粒度進行管理的,而不是針對塊設備,因此也是在底層文件系統及虛擬文件系統之上。
四、GFS設計架構:
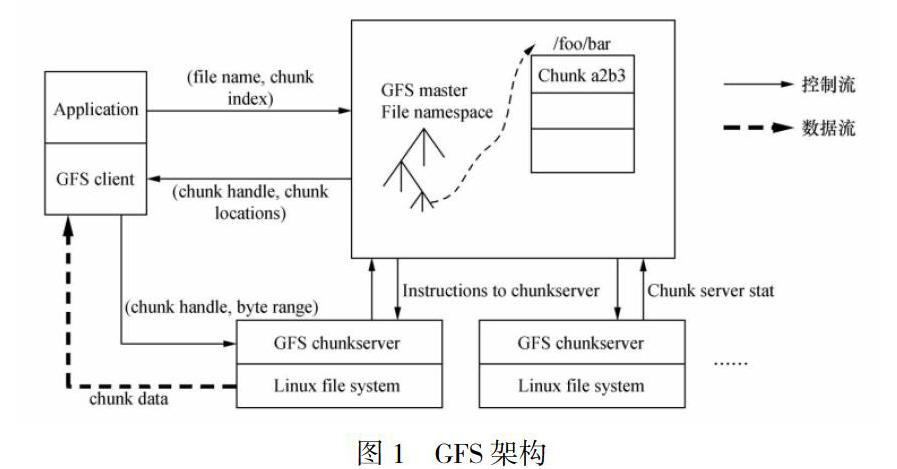
使用論文中的原圖如下:如圖所示,GFS主要由以下三個系統模塊組成:Master:管理元數據、整體協調系統活動。·ChunkServer:存儲維護數據塊(Chunk),讀寫文件數據。·Client:向Master請求元數據,并根據元數據訪問對應ChunkServer的Chunk。
三、GFS設計要點:
(1)chunk機制
chunk是GFS中管理數據的最小單元(數據塊),每一個chunk被一個64位的handle唯一標識,chunk被當做普通的文件存儲在linux系統中。每個chunk至少會在另一個chunkserver上有備份,而默認會為每個chunk做三個備份。chunk大小默認為64MB,比一般的文件系統的4kb的塊要大的多得多。Chunkserver一般不會緩存數據,因為chunk都是存儲在本地,故而linux已經將經常被訪問的數據緩存在內存中了。
chunk塊設置比較大(一般文件系統的塊為4kb)的優缺點如下:
優點:
1.減少元數據量,方便客戶端預讀緩存(filename+chunkindex->chunkhandle+chunkserverlocation),減少客戶端訪問的次數,減少master負載。
2.減少元數據量,master可以將元數據放在內存中。
3.客戶端取一次元數據就能讀到更多數據,減少客戶端訪問不同chunkserver建立tcp連接的次數,從而減少網絡負載。
缺點:
1.對于小文件的場景,容易產生數據碎片。
2.小文件占用chunk少,對小文件頻繁訪問會集中在少數chunkserver上,從而產生小文件訪問熱點(這個問題在后續的可靠性篇章中有相關的解決方案)。
(2)元數據管理
系統中三種元數據類型:·文件和chunk的名稱(命名空間)。文件和chunk之間的映射關系,比如說每個文件是由哪些chunk共同組成。每個chunk備份的位置。命名空間、文件和Chunk的對應關系的存儲方式:內存:真實數據;磁盤:定期Checkpoint(壓縮B樹)和上次CheckPoint后的操作日志;多機備份:Checkpoint文件和操作日志。Chunk位置信息的存儲方式:內存:真實數據磁盤:不持久存儲系統啟動和新Chunk服務器加入時從Chunk服務器獲取。避免了Master與ChunkServer之間的數據同步,只有Chunk服務器才能最終確定Chunk是否在它的硬盤上。
(3)Master單一性
單一的Master節點的策略大大簡化了FGS的設計。單一的Master節點可以通過全局的信息精確定位Chunk的位置以及進行復制決策。針對master宕機的處理和恢復在后續的高可用篇中詳細介紹。
(4)操作日志
操作日志包含了關鍵的元數據變更歷史記錄。這對GFS非常重要。這不僅僅是因為操作日志是元數據唯一的持久化存儲記錄,它也作為判斷同步操作順序的邏輯時間基線。文件和Chunk,連同它們的版本(可以看做是更新次數,以判斷chunk是否過期,低版本的認為過期),都由它們創建的邏輯時間唯一的、永久的標識。操作日志和chunk數據一樣,都需要復制到多臺機器,使用多副本保存。
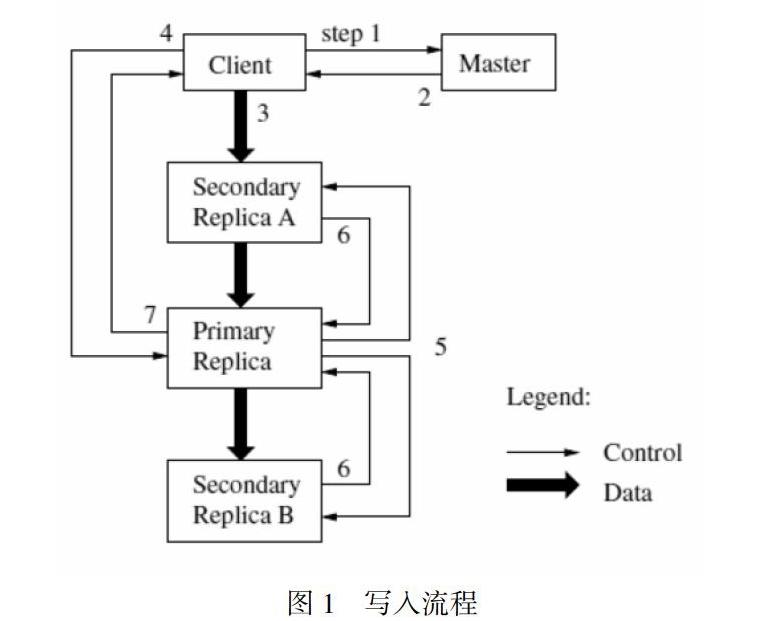
租約(lease)機制主要是為了保持多個副本間變更順序一致性的。Master節點為Chunk的一個副本建立一個租約,我們把這個副本叫做主Chunk。主Chunk對Chunk的所有更改操作進行序列化。所有的副本都遵從這個序列進行修改操作。因此,修改操作全局的順序首先由Master節點選擇的租約的順序決定,然后由租約中主Chunk分配的序列號決定。設計租約機制的目的是為了最小化Master節點的管理負擔。租約的初始超時設置為60秒。不過,只Chunk被修改了,主Chunk就可以申請更長的租期,通常會得到Master節點的確認并收到租約延長的時間。這些租約延長請求和批準的信息通常都是附加在Master節點和Chunk服務器之間的心跳消息中來傳遞。有時Master節點會試圖提前取消租約(例如,Master節點想取消在一個已經被改名的文件上的修改操作)。即使Master節點和主Chunk失去聯系,它仍然可以安全地在舊的租約到期后和另外一個Chunk副本簽訂新的租約。寫入流程如下,例如有1個主副本,2個從副本的情況:
客戶機向Master節點詢問哪一個Chunk服務器持有當前的租約,以及其它副本的位置。如果沒有一個Chunk持有租約,Master節點就選擇其中一個副本建立一個租約(這個步驟在圖上沒有顯示)。Master節點將主Chunk的標識符以及其它副本(又稱為secondary副本、二級副本)的位置返回給客戶機。客戶機緩存這些數據以便后續的操作。只有在主Chunk不可用,或者主Chunk回復信息表明它已不再持有租約的時候,客戶機才需要重新跟Master節點聯系。
客戶機把數據推送到所有的副本上。客戶機可以以任意的順序推送數據。Chunk服務器接收到數據并保存在它的內部LRU緩存中,一直到數據被使用或者過期交換出去。由于數據流的網絡傳輸負載非常高,通過分離數據流和控制流,我們可以基于網絡拓撲情況對數據流進行規劃,提高系統性能,而不用去理會哪個Chunk服務器保存了主Chunk。
(1)當所有的副本都確認接收到了數據,客戶機發送寫請求到主Chunk服務器。這個請求標識了早前推送到所有副本的數據。主Chunk為接收到的所有操作分配連續的序列號,這些操作可能來自不同的客戶機,序列號保證了操作順序執行。它以序列號的順序把操作應用到它自己的本地狀態中(也就是在本地執行這些操作,這句話按字面翻譯有點費解,也許應該翻譯為“它順序執行這些操作,并更新自己的狀態”)。
(2)主Chunk把寫請求傳遞到所有的二級副本。每個二級副本依照主Chunk分配的序列號以相同的順序執行這些操作。
(3)所有的二級副本回復主Chunk,它們已經完成了操作。
(4)主Chunk服務器(即主Chunk所在的Chunk服務器)回復客戶機。
任何副本產生的任何錯誤都會返回給客戶機。在出現錯誤的情況下,寫入操作可能在主Chunk和一些二級副本執行成功。(如果操作在主Chunk上失敗了,操作就不會被分配序列號,也不會被傳遞。)客戶端的請求被確認為失敗,被修改的region處于不一致的狀態。我們的客戶機代碼通過重復執行失敗的操作來處理這樣的錯誤。
在從頭開始重復執行之前,客戶機會先從步驟(3)到步驟(7)做幾次嘗試。如果應用程序一次寫入的數據量很大,或者數據跨越了多個Chunk,GFS客戶端代碼會把它們分成多個寫操作。這些操作都遵循前面描述的控制流程,但是可能會被其它客戶機上同時進行的操作打斷或者覆蓋。因此,共享的文件region的尾部可能包含來自不同客戶機的數據片段,盡管如此,由于這些分解后的寫入操作在所有的副本上都以相同的順序執行完成,Chunk的所有副本都是一致的。這使文件region處于上一節描述的一致的、但是未定義的狀態。讀取流程可以再看一下設計架構圖中的conrol和data流。
(1)GFSclient將服務所要讀取的文件名與byteoffset,根據系統chunk大小,換算成文件的chunkindex,即文件數據所處的第幾個chunk。
(2)將filename與chunkindex傳給master。
(3)Master返回給client元數據信息(包含chunkhandle與實際存儲的chunkserverlocation)。然后client獲取到該信息,作為key值與filename+chunkindex緩存起來。
(4)Client根據這些元數據信息,直接對chunkserver發出讀請求。對于三副本而言(一份chunk存儲在三臺不同的chunkserver),client選擇離自己最近的chunkserver(網絡?),通過之前獲取的元數據信息找到需要讀的chunk位置以及下一個chunk位置。如果緩存的元數據信息已過期,則需要重新向master去獲取一遍。
(5)Chunkserver返回給client要讀的數據信息。
結語
GFS的設計思路決定了它的主體框架及設計要點。針對于GFS大部分都是順序讀取的場景來說,不需要做進一步的優化。針對數據追加的優化才是針對順序寫的目標場景進行的好的優化設計點。NEFS的目標場景跟GFS有一定的差別,NEFS上層對接的是NOS對象存儲,基本都是大量的小文件(100MB以下),總體量比較大,對象個數比較多。而且大部分是順序寫,隨機讀場景,因此目標場景不一致導致結構和設計會有一定的差異。
參考文獻
[1] Thomas Anderson, Michael Dahlin, Jeanna Neefe, David Patterson, Drew Roselli, and Randolph Wang. Serverless networkfil e systems. In Proceedings of the 15th ACM Symposium on Operating System Principles, pages 109–126, Copper Mountain Resort, Colorado, December 1995.
[2] Remzi H. Arpaci-Dusseau, Eric Anderson, Noah Treuhaft, David E. Culler, Joseph M. Hellerstein, David Patterson, and Kathy Yelick. Cluster I/O with River: Making the fast case common. In Proceedings of the Sixth Workshop on Input/Output in Parallel and Distributed Systems (IOPADS 99), pages 10–22, Atlanta, Georgia, May 1999.
[3] Luis-Felipe Cabrera and Darrell D. E. Long. Swift: Using distributed disks triping to provide high I/O data rates. Computer Systems, 4(4):405–436, 1991.
作者簡介
孫偉(1981-),男,漢族,內蒙古察呼倫貝爾人,集寧師范學院計算機學院講師,工程碩士,研究方向:軟件工程。
猜你喜歡
數學學習與研究(2016年18期)2017-01-07 11:11:05
中國信息技術教育(2016年24期)2017-01-03 22:23:42
都市家教·下半月(2016年11期)2016-12-29 17:44:14
綠色科技(2016年20期)2016-12-27 18:47:42
藝術科技(2016年9期)2016-11-18 18:41:03
藝術科技(2016年9期)2016-11-18 15:09:45
藝術科技(2016年9期)2016-11-18 15:07:22
小學教學參考(語文)(2016年10期)2016-11-01 08:40:53
考試周刊(2016年78期)2016-10-12 13:16:07
考試周刊(2016年35期)2016-05-27 00:23:20
