閱讀過程中的同跳讀及其產生的認知機制
2018-01-22 13:03:30臧傳麗鹿子佳白玉張慢慢
心理與行為研究 2018年4期
關鍵詞:閱讀
臧傳麗 鹿子佳 白玉 張慢慢

摘要 在閱讀過程中,讀者并不會注視每一個詞,而是不斷地跳過很多詞。在英文閱讀中至少有30%的詞被跳讀,在中文閱讀中近50%的字詞被跳讀。那么被跳讀的字詞是否得到加工,何時得到加工,是當前閱讀過程中眼動控制模型關心的基本問題:具體包括(1)詞跳讀是基于副中央凹處詞匯的完全識別還是部分識別后發生;(2)中央凹加工負荷是否影響對下一個詞的跳讀;(3)副中央凹和中央凹加工效率與詞跳讀的關系是什么;(4)較低水平的視覺信息(如詞長、復雜性)和較高水平的語言信息(如詞頻、預測性)如何交互作用決定一個詞的跳讀。文章對上述問題進行系統分析,最后結合中文閱讀中書寫系統的特點,對未來中文閱讀中詞跳讀研究進行了展望。
關鍵詞 閱讀,跳讀,副中央凹加工,中央凹負荷。
分類號 B842.1
在自然閱讀過程中,人們通過不斷地移動眼睛來獲取新的信息。有人或許認為,讀者的眼跳是一個詞接著一個詞進行的,即從一行文字的第一個詞開始,然后第二個詞,第三個詞……直到一行結束,眼睛回掃到下一行的第一個詞,這樣循環往復進行閱讀。事實上,很多詞在閱讀中沒有被注視而是被略過,這種現象稱為跳讀(skipping)。研究表明,在英文閱讀過程中熟練的讀者至少跳讀了30%的詞(Angele & Rayner,2013;Clifton et al.,2016;Reichle & Drieghe,2013)。在中文閱讀過程中被跳讀的詞達到50%,即使這些詞在句子語境中是不可預測的(Liversedge et al.,2014;Zang et al.,2018)。
詞跳讀在閱讀過程中如此普遍,那么詞跳讀是如何產生的,被跳讀的詞是否得到了加工,何時得到的加工,不同水平的信息如何相互作用并促使讀者做出跳讀一個詞的決定。本文將通過深入分析已有的文獻,對閱讀過程中跳讀產生的機制進行系統評論。
1跳讀與注視時間的關系
單詞跳讀是如何產生的,存在什么樣的機制?很多研究者(Engbert & Kliegl,2011;Reichle,2011)認為,一個詞被跳讀或被注視是由相同的機制決定的,即影響注視時間的因素以同樣的方式影響單詞的跳讀。的確,在眼動研究中,單詞的跳讀率是反映詞匯加工的一個有效指標,如果單詞加工出現困難,會導致讀者的注視時間增長、跳讀率下降(Clifton et al.,2016;Rayner,1998,2009)。因而在注視時間和跳讀率上往往得到一致的結果趨勢。換句話說,跳讀率和注視時間通常被認為是反映同一現象的兩個相關指標。然而,研究者通過不同的實驗操縱,發現很多因素對跳讀率和注視時間有不同的影響(Choi&Gordon;,2014;Liversedge et al.,2014;Carpenter,2000)。
Liversedge等人(2014)驗證了中文單字詞的視覺復雜性和詞頻如何影響句子閱讀過程中的詞跳讀和注視時間。實驗通過眼動技術記錄了讀者在閱讀包含單字目標詞的句子中的眼動行為,操縱了目標詞的視覺復雜性和詞頻,并考察了起跳位置(launch site,眼跳從哪個位置開始啟動,隨后落在目標詞上)對跳讀率和注視時間的影響。研究發現,在跳讀率上,復雜性和詞頻的主效應都顯著,二者的交互效應不顯著;在注視時間上,二者的主效應不顯著,但交互效應顯著。結果清晰地表明,視覺復雜性和詞頻的相互作用以不同的方式影響著單詞跳讀和注視時間。本質上,注視時間反映了讀者何時(when)移動眼睛,而單詞跳讀反映了讀者把眼睛移動到何處(where),即哪一個詞被跳讀,哪一個詞又被選擇為下一次眼跳的目標。這是閱讀過程中讀者需要實時做出的兩種決定。影響“when”和“where”這兩種決定的因素可能存在質的差異,因而對單詞跳讀產生機制進行研究具有特殊的意義。2跳讀產生的理論爭論
在當前拼音文字閱讀研究中,存在兩種有影響力的計算模型:以序列加工為基礎的E-Z讀者模型(Reichle,2011;Reiehle & Drieghe,2013)和以平行加工為基礎的SWIFT模型(Engbert & Kliegl,2011)。不同模型在解釋跳讀時主要關注以下四個核心問題。
2.1跳讀是基于副中央凹詞匯的完全識別還是部分識別?
E-Z讀者模型假設,詞匯加工是以嚴格的序列方式進行的,又稱序列注意轉移模型(Sequential Attention Shift,SAS模型)(Reichle,2011;Reichle & Drieghe,2013,見圖1)。在該模型中,單詞識別與眼動控制緊密相關,單詞識別決定著眼動何時開始以及移到何處。
單詞識別分為兩個階段:第一,熟悉性檢驗(L1,familiarity check),是單詞加工的早期階段,包含對副中央凹單詞的熟悉性進行評估。L1加工階段的完成,眼球運動系統開始計劃眼跳到下一個詞n+1上(進入可變的眼跳計劃階段M1)。第二,詞匯通達(L2,lexical access),是單詞加工的后期階段。L2,的完成引起注意(A)從當前注視詞n轉移到副中央凹詞n+1上。單詞跳讀基于以下一系列的事件:如果(1)眼睛注視在單詞n上,(2)注意轉移到單詞n+1上,(3)單詞n+1在副中央凹處進行識別的第一個階段
熟悉性檢驗L1足夠迅速,到單詞n+1的眼跳計劃仍然處于可變的階段M1,那么該次眼跳計劃就被取消,系統重新計劃一次到單詞n+2的眼跳,這時單詞n+1被跳讀。當單詞n+1很容易加工時,導致在該詞上的L1階段很短,那么該詞就很容易被跳讀。因此,根據E-Z讀者模型,一個單詞被跳讀,是因為這個詞在副中央凹視覺區已經得到完全識別或者即將發生完全的詞匯識別。
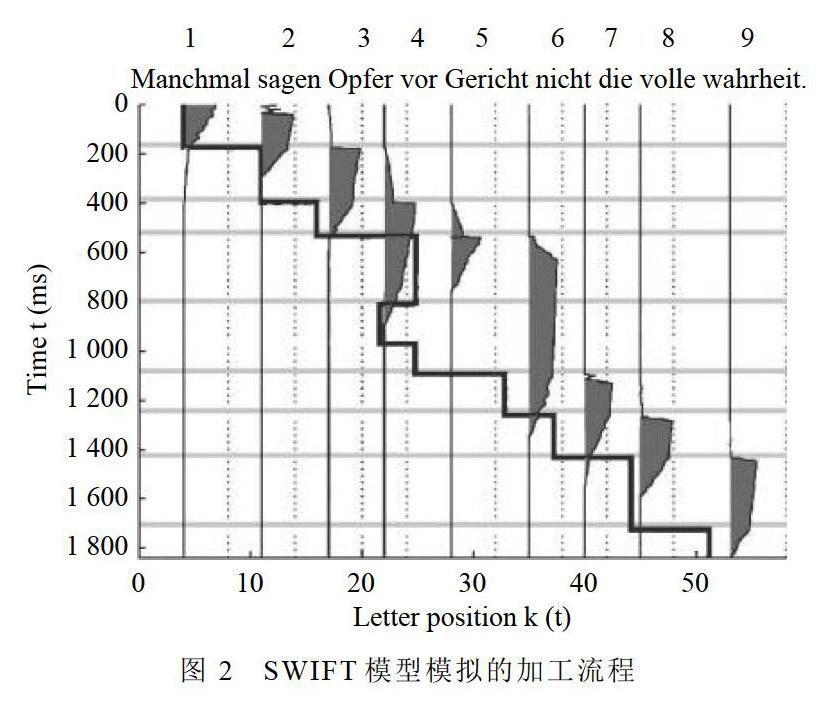
SWIFT(saccade-generation with inhibition by foveal targets)模型是一個受中央凹目標抑制的眼跳產生式模型。在注視點周圍2度視角以內的信息得到中央凹加工,副中央凹(5度視角以內)提供當前注視詞右側(或左側)單詞的信息。從中央凹到副中央凹視覺區視敏度逐漸下降,加工速度逐漸變慢。模型假設,在注意窗口中詞匯加工呈空間分布,也就是說在知覺廣度內所有單詞都可以被同時進行加工(Engbert & Kliegl,2011,如圖2)。
詞匯加工是一個動態激活系統,這種激活隨著單詞加工速率的變化而變化。一個單詞受激活的水平是由該詞的加工難度(如視敏度、詞頻和在語境中的預測性)決定的。在注意梯度范圍內,激活水平最大的單詞將成為下一次眼跳的目標。眼跳目標選擇是所有得到激活的單詞之間不斷競爭的過程,選擇一個詞作為眼跳目標的概率由其詞匯激活的相對大小來決定。當眼睛注視在詞n上,如果詞n+2的詞匯激活水平超過了詞n+1,那么下一次眼跳將會落在詞n+2上,詞n+1就會被跳讀。該模型預測,在一個句子語境中具有很高預測性的詞會被跳讀,因為該詞的識別可以在沒有或者很少的視覺輸入信息的情況下而被猜測出來。而且長詞在不完全識別的基礎上也可以被跳讀。因此,根據SWIFT模型,副中央凹單詞在部分被識別的時候,跳讀也可以發生。
跳讀到底取決于副中央凹單詞的完全識別還是粗略的部分識別,不同研究者通過不同實驗操縱獲得了不同的結果。例如,Drieghe,Rayner和Pollatsek(2005)驗證了可預測性詞和不可預測性詞的跳讀率,并設置一種非詞預視條件,該非詞與可預測性目標詞除了在尾部的一個字母存在差異外,其他方面都相同(如liver作為liver的預視詞)。這一微小的操縱竟然使預測性效應完全消失,導致視覺相似非詞條件下的跳讀率與視覺不相似條件下的跳讀率沒有差異。Drieghe等人推測,在眼球運動系統執行一次跳讀的決定之前,副中央凹單詞需要加工到一個較高的水平。換句話說,他們的結果不支持部分識別或猜測機制來解釋單詞跳讀(Fitzsimmons & Drieghe,2013;Gordon,Plummer,& Choi,2013)。然而Balota等人(Balota,Pollatsek,& Rayner,1985)報告了一個非常類似的研究,發現在可預測的視覺相似的非詞(cahc)和可預測的詞(cake)預視條件下跳讀率一樣多,表明副中央凹單詞在部分識別時就能產生跳讀。造成這種不一致結果的原因可能在于,對于副中央凹詞匯加工到什么程度,眼球運動系統將做出一次跳讀的決定,僅僅依靠現有的眼動技術,仍然無法準確地回答這個問題。
2.2中央凹加工負荷是否影響對下一個詞的跳讀?
E-Z讀者模型把注意轉移和眼跳計劃分離開來:到副中央凹詞n+1上的眼跳計劃已經開始,當前注視詞n的語言加工仍在繼續。詞n的加工時間受中央凹加工負荷的影響。在詞n被加工完之前,通常在眼跳計劃完成前,注意已經轉移到詞n+1上并開始對其進行預加工。由于眼跳計劃和注意轉移的分離,預加工詞n+1(眼睛還在注視詞n)的時間受詞n識別時間(第二階段L2持續時間)的影響:L1結束后,眼跳計劃開始,并一直持續一段固定的時間。當前注視詞n上的L2時間越短,就有越多的時間來對副中央凹詞n+1進行預視(見圖1)。因此,根據E-Z讀者模型,當前注視詞加工越容易,副中央凹預視效應越大,識別和跳讀副中央凹詞的概率也越大。
SWIFT模型沒有具體預測中央凹加工負荷會調節副中央凹的預加工,但根據其核心假設,它能夠很好地解釋中央凹單詞加工越難,副中央凹單詞的激活越容易被抑制,因而預視效益越少。與SWIFT模型相似的Glenmore模型明確指出,眼動控制系統中“when”和“where”決定受中央凹加工難度的影響。模型假設,多個單詞可以被同時加工,單詞之間語言加工的激活水平存在競爭。如果當前注視詞n需要較長時間的激活,它將限制對詞n+1的加工。因此,中央凹加工負荷會減少副中央凹單詞的預視效益。模型還假設,每個詞都有一個凸顯值(salience value),該值會受影響注視時間的語言激活系統的限制,眼球運動系統會選擇凸顯值最大的詞作為目標詞(Reilly & Radach,2006)。因此,根據SWIFT和Glenmore模型,可以推測單詞跳讀受中央凹加工負荷的調節。
基于序列加工和平行加工的理論都能解釋中央凹加工負荷影響副中央凹的預加工,主要表現在閱讀時間上的預視效益,這一點在很多實驗中得到證實(如White,Rayner,& Liversedge,2005;Yan,Kliegl,Richter,Nuthmann,& Shu,2010)。并且,這些模型認為中央凹負荷以同樣的方式調節著單詞的跳讀,然而很多研究并沒有發現預視詞的跳讀受中央凹加工負荷的影響(如Drieghe et al.,2005;Yan,Kliegl,Shu,Pan,& Zhou,2010)。根據我們前面提到的,同一因素對單詞跳讀和閱讀時間可能產生不同的影響。因此,盡管中央凹負荷調節副中央凹的預加工(通過閱讀時間來反映),但未必對眼睛移到哪里即“where”決定產生影響(由跳讀率來反映)。
2.3副中央凹和中央凹加工效率是否影響詞的跳讀?
副中央凹和中央凹加工效率或信息利用的有效性可能影響對下一個詞的跳讀。在E-Z讀者模型的理論框架下,Rayner,Slattery和Belanger(2010)采用移動窗口范式,發現慢速閱讀者的知覺廣度比快速閱讀者小。他們認為慢速閱讀者需要更多的資源去編碼和加工當前中央凹詞,導致沒有可利用的資源來加工注視點右側的副中央凹信息。然而Risse(2014)進一步探討了副中央凹加工和閱讀速度的關系,結果發現副中央凹預視與總體句子閱讀速度呈負相關,即閱讀速度越慢,副中央凹預視效益越大。也就是說,與快速閱讀者相比,慢速閱讀者能有效地從副中央凹視覺區獲得更大的預視效益。Risse認為慢速閱讀者之所以能夠更有效地使用副中央凹信息,是因為注視當前中央凹詞的時間長,增加了處理副中央凹信息的時間,使副中央凹的預加工更為有效。這一解釋與SWIFT模型的觀點一致,即注意在多個詞之間呈梯度分布,多個詞可以同時進行加工。相反,快速閱讀者是更熟練的讀者,他們的單詞識別過程可能是高度自動化的,因而能快速補償較少的副中央凹預視。探討兩類讀者在副中央凹信息使用的差異或加工效率與跳讀的關系能夠進一步驗證理論的爭論。
Rayner等人(Rayner,Reichle,Stroud,Williams,& Pollatsek,2006;Rayner,Yang,Schuett,& Slattery,2013)還發現,老年人在對副中央凹信息的利用和加工效率上與大學生存在差異。他們認為,相比大學生,老年人在閱讀過程中需要更長的注視時間。但老年人采用更冒險的閱讀策略來補償他們較慢的閱讀速度。也就是說,為了加快閱讀速度,他們在閱讀過程中總是提前往下看,總是不斷地猜測下一個詞,這一策略導致老年人更多地依賴于副中央凹的部分信息,使他們在加工副中央凹視覺信息時更有效,因而產生了更多的跳讀。然而老年人往往頻繁地回視到被跳讀的單詞上,這表明他們的猜測并不總是有效的。老年人和大學生在注視時間和跳讀率上的差異,并沒有導致兩組群體在閱讀理解上存在差異。老年人在回答閱讀理解問題的時候與大學生一樣有效。E-Z讀者模型和SWIFT模型對老年人閱讀的數據進行了模擬。二者通過調整參數來降低詞匯加工速率,從而成功模擬出老年人閱讀需要更多的注視和更長的時間。E-Z讀者模型通過修改與預測性有關的參數從而使跳讀率增加(Rayner et al.,2006)。然而,SWIFT模型并沒有模擬出老年人在跳讀中的表現(Laubrock,Kliegl,& Engbet,2006)。這一現象是拼音文字特有的還是具有普遍意義,從不同群體進行驗證對于進一步解決跳讀產生的機制、擴展當前閱讀過程中的眼動控制模型是非常重要的。
2.4視覺和語言信息在詞跳讀中的作用哪一個更重要?
在探討跳讀機制的過程中,不可避免涉及到一個重要問題,即什么因素決定著眼球運動系統在注視當前詞n時產生一次到詞n+2的眼跳,而不是到達詞n+1上。以往研究表明,較低水平的視覺信息(如詞長、起跳位置等)和較高水平的語言信息(如詞頻、預測性等)都可能影響一個詞是否被跳讀。然而這些因素對跳讀的影響或許并不具有同等的重要性。詞長和起跳位置效應在E-Z和SWIFT模型中具有同等的重要性。短詞和起跳位置近的詞容易被跳讀,因為它們位于視敏度較高的視覺區域,它們的長度和距離使其在眼跳發生之前已經被完全識別,因而不可能成為下一次眼跳的目標詞。Brysbaert等人(Brysbaert,Drieghe,& Vitu,2005)采用元分析方法,比較了詞頻和可預測性對單詞跳讀的影響。結果發現,5%的效應來自于詞頻,8%的效應來自于預測性,表明預測性對單詞跳讀的影響比詞頻更大。然而很多研究發現預測性效應大小超過10%(Drieghe et al.,2005;Drieghe,Desmet,& Brysbaert,2007)。為了系統比較這些因素對詞跳讀的相對重要性以及這一規律是否具有跨語言的普遍性,還需要更多的實驗證據。
3中文書寫系統的特性及其對詞跳讀研究的啟示
中文書寫系統具有與英文書寫系統顯著不同的特點(Li,Zang,Liversedge,Pollatsek,2015),這些特點可能影響中文閱讀過程中詞的跳讀。
第一,單位空間內信息密度大。中文書面文本是由一系列的方塊漢字構成的。每個漢字在形狀和復雜性上(如“乙”和“齉”)存在很大差異,但每個字占用的空間大小是相同的。中文比英文書面排列更緊密,因而單位空間內的信息密度更大。這一特點可能使讀者在有限的空間內獲得更多的信息,在注視當前詞的時候,能夠同時對副中央凹處的單詞進行更多的預加工(Zang,Liversedge,Bai,& Yan,2011;王穗蘋,佟秀紅,楊錦綿,冷英,2009;臧傳麗,張慢慢,岳音其,白學軍,閆國利,2013),因而可能會導致更多的跳讀。
第二,詞長分布相對集中。英文單詞的詞長分布很廣,從一個字母詞(如“a”)到二十個字母詞(如“internationalization”)不等。中文詞是由漢字構成,很多漢字本身可以作為一個獨立的詞出現,也可以與其他漢字構成一個多字詞。根據《現代漢語常用詞詞典》(2009)統計的56008個詞中,雙字詞占72%,單字詞占6%。如果考慮到字詞的使用頻率,那么單字詞占70%,雙字詞占27%,單字詞具有比其他長度字詞更高的使用頻率。這些特點可能使中文讀者采用不同于拼音文字閱讀的跳讀策略。
第三,中文詞邊界信息缺乏。在拼音文字書寫系統中,詞與詞之間有明顯的邊界信息(空格)。讀者能夠利用副中央凹的預加工,迅速地判斷哪一組字母構成一個詞。而中文文本是由一系列連續的字組成,沒有明顯的詞邊界信息,讀者不能從視覺特征上直接獲得哪些漢字構成一個詞,而且中文讀者對于詞的意識非常淡薄(“et al.,2015;Zang et al.,2011)。這一特點可能使中文讀者在利用副中央凹視覺區進行詞匯切分時存在困難,進而影響詞的跳讀。
中文書寫系統的這三個顯著特性使我們研究中文閱讀過程中的詞跳讀具有獨特的意義。在閱讀過程中,讀者需要實時地做出兩種決定,即何時(when)移動眼睛以及眼睛移到何處(where)。近年來,國內外研究者對影響“when”決定的因素進行了大量研究,也有研究者對“where”決定中當一個詞得到注視時的注視位置分布進行了研究(Li et al.,2015;Zang et al.,2011;Wei,Li & Pollatsek,2013;Yan,Kliegl,Richter,Nuthmann,& Shu,2010;Zang,Liang,Bai,Yan,& Liversedge,2013;Zang,Meng,Liang,Bai,& Yan,2013;臧傳麗,孟紅霞,自學軍,閆國利,2013)。然而關于詞跳讀的研究非常有限(白學軍,劉麗萍,閆國利,2008;季靖,楊桂芳,劉志方,潘運,2012;王雨函,隋雪,劉西瑞,2008)。例如,白學軍等(2008)發現,詞的預測性是影響跳讀的重要因素。然而,預測性在多大程度上起作用,什么時候起作用,與其他變量的關系及作用機制等,都不清楚。
4以往研究的不足及研究展望
總結以往有關閱讀過程中詞跳讀機制的研究,我們發現至少存在三個方面的不足,并在此基礎上對未來研究進行展望。
第一,研究內容上,以往研究者對詞跳讀產生的機制進行了大量的理論探討和基礎性實驗研究。目前,閱讀中的眼動控制模型認為,詞匯加工驅動著眼球運動,單詞跳讀與詞匯加工密切相關。然而,這些模型在一些基本的問題上存在很大爭論:(1)詞匯加工是怎樣起作用的;(2)從注視開始到結束的過程中詞匯加工何時起作用;(3)詞匯加工在多大程度上控制著眼球運動。這三個問題涉及到詞匯加工和眼球運動控制發生的時間進程。需要指出的是,當前的眼動控制模型是基于拼音文字而提出的,大部分實驗研究也是基于拼音文字而進行的。與拼音文字不同,中文書寫系統具有自己獨特的特點,當前對中文詞跳讀機制的研究也非常有限。對中文詞跳讀的機制進行系統地研究,可以為驗證跳讀產生的機制是具有跨語言的普遍適用性還是具有特異性提供重要啟示。
第二,技術手段上,以往研究者主要采用眼動技術(特別是經典的研究范式如邊界范式)探討副中央凹區域中信息的加工和利用并對跳讀產生的影響,并在大量實驗證據的基礎上,構建了閱讀中的眼動控制模型。眼動技術是一種測量行為反應的技術,眼動技術所提供的指標往往反映了閱讀過程中所有認知加工的綜合(例如,注視時間反映了詞匯在大腦中的整體加工過程)。僅僅根據眼動技術指標,仍然無法準確地回答眼動控制過程中的重要問題。ERP技術時間分辨率高,且具有刺激鎖時性,可以測查刺激呈現后的早期激活過程和不同認知加工水平的電生理反應。近年來,有研究者開始思考將眼動和ERP技術結合,實現眼動和ERP技術的同步記錄。通過對注視相關電位(fixation-related potentials,FRPs)和眼跳相關電位(saccade-related potentials,SRPs)進行分析,可以對正常句子閱讀過程中的眼球運動和腦電活動進行直接的比較,為探討自然閱讀過程中詞跳讀的產生機制提供了新的技術手段,使我們對詞跳讀產生機制的認識從行為層面推進到了神經生理層面(例如,Dimigen,Sommer,Hohlfeld,Jaeobs,&Kliegl;,2011;Henderson,Luke,Sehmidt,& Riehards,2013)。
第三,被試群體上,以往在拼音文字閱讀過程中,研究者普遍采用大學生為被試,有些研究者開始關注老年人跳讀的特點。中國老年人采取什么樣的跳讀策略,與拼音文字閱讀中老年人是否存在差異?從被試群體的角度驗證副中央凹和中央凹加工與詞跳讀的關系,可以進一步探討并驗證以往的研究結果是否能推廣到不同群體中。因此,有必要從不同角度、不同群體來進一步驗證并解決這些跳讀產生的基本問題。這些問題的解決對于擴展當前閱讀中的眼動控制模型,以及有效指導個體(特別是老年人群體)閱讀與學習具有重要的現實意義。
猜你喜歡
小學教學參考(綜合)(2016年11期)2016-11-14 20:37:26
人間(2016年27期)2016-11-11 16:15:40
人間(2016年27期)2016-11-11 16:11:35
人間(2016年28期)2016-11-10 22:36:19
知音勵志·社科版(2016年9期)2016-11-09 06:05:57
課程教育研究·學法教法研究(2016年21期)2016-10-20 17:43:02
中學課程輔導·教師教育(中)(2016年9期)2016-10-20 16:05:53
考試周刊(2016年76期)2016-10-09 09:22:30
大學教育(2016年9期)2016-10-09 08:27:51
成才之路(2016年25期)2016-10-08 10:49:29
