決策樹在大學外語等級考試成績分析中的應用
2022-06-02 13:18:32王淵志
浙江紡織服裝職業技術學院學報 2022年1期
關鍵詞:成績
王淵志

摘 要:隨著數字化在教育考試領域的不斷推進,考試成績數據分析已成為考試管理領域的一大課題。本文以寧波市大學外語等級考試成績數據為基礎,利用決策樹模型挖掘出影響考試成績的關鍵因素,為高校進一步提高大學外語教學水平提供科學有效的參考。
關鍵詞:大學外語等級考試;成績;決策樹
中圖分類號:G424.74? ? ? ? ? ? ? ? ? 文獻標識碼:A? ? ? ? ? ? ? 文章編號:1674-2346(2022)01-0096-05
1? ? 大學外語等級考試成績分析的意義
大學外語等級考試是教育部考試中心負責實施的全國性的教學考試,目的在于對高校學生實際外語應用能力進行客觀、準確的測量,這項考試因為題目設計科學合理、考務流程規范,在社會上認可度很高,很多用人單位將該考試成績作為招錄工作人員的重要參考依據之一。對學校而言,考試成績既直接體現了學生的學習效果,又能評價教師日常教學水平。因此各個高校對于大學外語等級考試的成績十分關注,如何提高大學外語等級考試成績,推進外語教學,從而提升學生的實際外語水平成為眾多高校追求的目標。
目前,學校使用教育部考試中心研發的大學外語等級考試考務管理系統,主要包括報名信息錄入、照片采集、試場編排、準考證打印、缺考違紀數據錄入、成績導入等功能,對系統數據往往停留在查詢、增刪等基礎的應用方面,個別學校通過導出到EXCEL功能,進行簡單的成績統計,得出的結果往往比較單一,數據的價值沒有完全被開發。如果把數據挖掘技術應用于成績分析,可以幫助學校深入了解學生各項成績之間的關聯,找出影響成績的各項因素,對于提高教學質量,提升人才培養水平大有幫助。
2? ? 決策樹分類方法介紹
本文采用分類方法中的代表-決策樹算法,嘗試對影響考試成績幾個關鍵要素進行分析。分類方法的定義如下:找出同類事物共同性質的特征性知識和不同事物之間的差異性特征知識。基于決策樹的分類算法是一種以實例為基礎的歸納學習算法,即從一系列無序無規則的元組中推導出分類規則,以樹的形式呈現。決策樹采用自頂至下的貪婪算法,在其內部結點選擇分類效果最優的屬性向下分支,直到這棵樹能明確地分類訓練樣本,或所有屬性都被使用。決策樹中比較著名的是C4.5 算法。通過這種算法得出的結論很容易把邏輯上的關系以一種非常直觀的方法清晰地表達出來。對于判斷因素少、邏輯組合較為簡單的項目尤為適合。決策樹尤其擅長處理非數值型數據,數據預處理工作量相對較少。
采用決策樹技術進行分類包含兩個步驟:(1)使用訓練樣本構造并優化一棵決策樹,搭建模型。從實際應用上看,這個過程就是從樣本中獲取知識,進行機器學習的過程。(2)依靠構造完成的決策樹對輸入數據進行分類。從根結點依次判斷輸入記錄的屬性值,直至某個葉結點停止,從而找到該記錄對應的類。其中建樹與剪枝環節是建立決策樹模型的關鍵步驟。
3? ? 決策樹在大學英語四級成績分析中的應用
大學外語等級考試的開考科目包括英語四級、英語六級、日語四級、日語六級、法語四級等。目前全國每次均有近1000萬人參加考試,其中寧波市報考人數達到10萬人,在浙江省內居首位。報考人數最多科目為英語四級,本文主要以2019年下半年寧波市英語四級考試成績作為分析樣本。
該樣本包括考試成績記錄41222條,來自寧波16所高校。按學校層次分為重點本科、普通本科、高職專科與成教四大類,按專業類別分為理工類、醫藥類、人文類、經管類、藝術體育類五大類。
本文借助Visual Studio SSDT+SQL Server工具,采用決策樹算法,對報考數據中的學校類別、考生專業、入學年級、性別、考生學歷等項目進行挖掘分析,找出關聯特征,為高校改進教學安排提供參考。主要包括以下幾個步驟:(1)對報考數據進行預數理,即去除無關字段,離散化保留字段;(2)將報考數據分類為訓練集與測試集,并通過SSDT中的決策樹算法建立挖掘模型;(3)模型準確率驗證。
3.1? ? 數據預處理
為了獲得數據挖掘所需的凈化數據,必須對海量數據進行預處理,包括數據集成、數據選擇和數據清理,本文使用SQLSEVER2014軟件實現。
(1)去除不相關字段。由于數據直接從系統中導出,數據整齊,數據噪聲情況不存在。但數據集合中共有35個字段,這些字段給挖掘提供了海量的信息,但是如果使用過多的字段作為輸入值,反而會使挖掘結果可讀性下降,影響到最終結果的獲取和分析,有必要去掉數據集中與數據挖掘關系不大的字段,如班級、班級名稱、校區、編排座位等信息,保留了其中專業名稱、年級、性別、準考證號(標志數據的主鍵)、總分、缺考、報名學校、學歷名稱等字段供挖掘使用。
(2)所屬學校歸類。16所高校按照學校層次可分為重點本科、普通本科、高職專科與成教四大類,將報名學校列替換為學校類別。
(3)專業歸類。由于考生就讀專業較多,不利于數據挖掘,根據專業性質歸為理工類、醫藥類、人文類、經管類、藝體類5種。
(4)總分離散化處理。由于總分為連續數值,不適合決策樹算法。新增“是否通過”與“是否優秀”字段。總分大于等于425分,“是否通過”為真。總分大于等于550,“是否優秀”為真。
3.2? ? 創建挖掘項目
使用 VS2017新建Analysis Service多維數據和數據挖掘項目,在關聯數據源后,選取70%的記錄作為訓練集,指定挖掘結構為決策樹,采用“準考證”為主鍵,選擇“學校類別”、“專業類別”、“入學年級”、“性別”、“考生學歷”作為輸入列,選擇“是否缺考”、“是否通過”、“是否優秀”作為可預測列,生成通過率、優秀率與實考率3個挖掘模型,從而發現通過率、優秀率、實考率與輸入字段之間的規律。
3.3? ? 驗證模型準確性
為了保證模型具有較好的精確度和健壯性,將剩余的30%的數據視為測試集,用來測試和驗證模型是否準確。經驗證,通過率、優秀率、實考率的測試結果預測概率超過80%,說明模型結果真實可靠。
4? ? 決策樹分析
由于生成的決策樹模型對應的規則較多,且樹型較大。本文以通過率、優秀率、實考率為例,從模型中抽取出一些強關聯型規則加以分析。
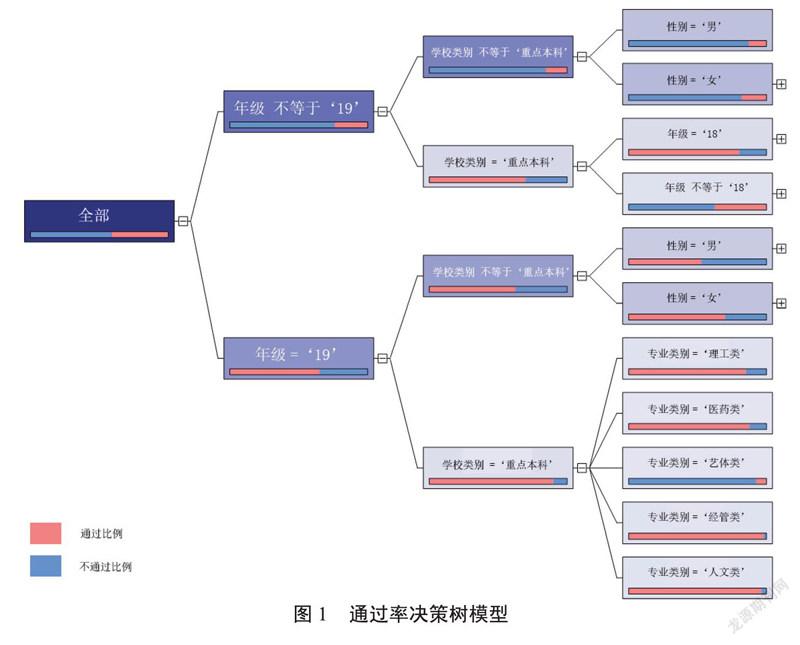
4.1? ? 通過率決策樹分析
部分強關聯規則:
IF 年級=“19級” then 通過率在65%左右
IF 年級=“19級”and 學校類別=“重點本科”then 通過率接近90%
IF 年級=“19級”and 學校類別=“重點本科” and 專業類別=“經管類”then 通過率超過97%
IF 年級=“19級”and 學校類別<>“重點本科”then 通過率在60%以上
IF 年級〈〉“19級” then 通過率不到25%
IF 年級〈〉“19級”,學校類別<>“重點本科” then 通過率僅有12%
可以發現,決定大學英語四級能否通過的首要因素是考生的年級。根據現行政策,考生第一學年允許報考英語四級,因此多數考生都不會放棄第一學年考試的機會,而且由于剛入學,學習熱情較高。反觀19級以前的考生,這些考生大多是重考生,未能在首次考試中一次性通過,一般而言英語基礎不夠扎實,而英語學科需要長期積累,基礎不實的考生往往再次考試通過率也比較低。
對于19級考生,學校類別決定了通過率。重點本科的通過率明顯高于其他類別的考生。顯然,重點本科的生源素質確實是高于其他層次考生,生源素質直接影響了四級的通過率,這與日常經驗得出的判斷是一致的。對于普通學校考生,性別因素對通過率起了關鍵的作用,女生的通過率比男生高出15個百分點。對于重點本科學生,就讀于經管與人文專業的考生的通過率要高于其他學科。
4.2? ? 優秀率決策樹分析
部分強關聯規則:
IF 學校類別=“重點本科”then 優秀率在30%以上
IF 學校類別=“重點本科”專業類別=“人文”then 優秀率在40%以上
IF 學校類別=“重點本科”專業類別=“經管”then 優秀率在45%以上
決定大學英語四級優秀率的首要因素是學校的類別。重點本科高校聚集了大批最優秀的考生,這類考生參加四級考試優秀率自然要遠遠高于其他類別學校的考生。其中重點本科高校的考生,修讀人文與經管類學科的優秀率要高于其他學科,藝體類的考生優秀率最低。高職專科考生,受制于生源素質,優秀率很低,只有極個別的人文學科考生達到了優秀,而非人文專業的無一優秀。
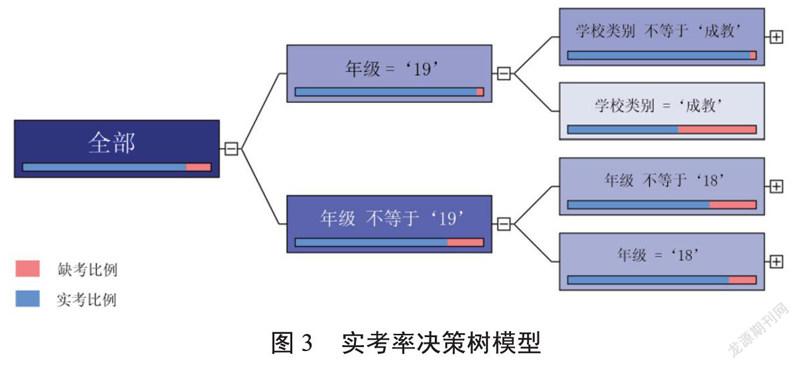
4.3? ? 實考率決策樹分析
部分強關聯規則:
IF 年級=“19”then 實考率在95%以上
IF 年級=“19” 學校類別〈〉“成教”then 實考率接近97%
IF 年級〈〉“19”then 實考率在 80%以上
IF 年級=“18”then 實考率在 85%以上
決定實考率高低的首要因素還是年級,這與通過率的首要因素保持一致。19級的考生,第一次參加考試,往往比較重視這項考試。而19級前的考生,往往是多次參加考試,其對考試的重視程度不如19級的考生,因此缺考人數明顯增加。對于19級的考生而言,成教學生與其他全日制學生產生了明顯的差異。成教學生英語基礎較差,考生自信心不足,無法認真對待這項考試,因此有一半考生放棄了考試。全日制學生首次報名缺考比較少。對于19級的全日制學校的學生而言,性別依然是決定到實考率的關鍵因素,女生的實考率要比男生高出3個百分點。
5? ? 結語
影響通過率首要因素是考生年級,第一學年的考生通過率明顯高于其他年級。影響優秀率首要因素是考生學校類別,重點高校的考生優秀率明顯高于其他類別。影響實考率首要因素是考生年級,第一學年考生的實考率明顯高于其他年級。
實驗表明,3個模型的預測準確率超過80 %,分析結果也符合現實認知。當然該模型還存在不足,比如對成績庫中相關字段選取過程人為因素較大,未采用更為先進的算法等,都值得進一步研究。
參考文獻
[1]袁樂泉,朱亞輝.基于隨機森林的大學英語四級通過率預測模型[J].電子測試,2021(4):54-55.
[2]葉澤俊.基于數據挖掘的大學英語四級通過率預測建模研究[J].長春師范大學學報,2019(12):8.
[3]欒紅波.數據挖掘在大學英語教學和測評中的研究與應用[D].北京:北京郵電大學,2017:22-25.
The Application of Decision Tree in the Analysis of College Foreign Language Test Scores
WANG Yuan-zhi
(Ningbo Education Examinations Authority,Ningbo,Zhejiang 315000,China)
Abstract: With the continuous advancement of digitalization in the field of education examinations,the analysis of examination result data has become a major topic in the field of examination management.Based on the scores data of Ningbo’s College Foreign Language Test,this paper uses the Decision Tree model to dig out the key factors that affect test scores so as to provide scientific and effective reference for colleges and universities to further improve college foreign language teaching.
Key words: College Foreign Language Test;score;Decision Tree
猜你喜歡
東方教育(2016年8期)2017-01-17 19:34:48
都市家教·下半月(2016年11期)2016-12-29 09:58:13
現代商貿工業(2016年21期)2016-12-26 15:56:05
新教育時代·教師版(2016年26期)2016-12-06 12:05:42
人間(2016年28期)2016-11-10 22:37:55
考試周刊(2016年67期)2016-09-22 13:53:00
中國科技博覽(2016年17期)2016-08-26 22:42:06
科教導刊·電子版(2016年13期)2016-06-28 18:24:02
戲劇之家(2016年11期)2016-06-22 11:49:40
中國科技博覽(2016年11期)2016-05-06 02:38:00
