小語種復合人才培養目標下數據挖掘在創新日語口譯詞匯教學模式中的應用
2020-05-08 08:33:46陳新妍
科教導刊 2020年4期
關鍵詞:詞匯教學
陳新妍


摘 要 基于數據挖掘,探討運用文本統計工具的分析結果在日語口譯課詞匯教學中的應用。主要從詞匯總量、詞頻、搭配、雙語文本數據對比四個方面,論述數據挖掘對詞匯教學創新模式有一定的輔助作用。
關鍵詞 日語口譯 詞匯教學 詞頻
Abstract Based on data mining, this paper discusses the application of the results of text statistics in vocabulary teaching of Japanese interpretation course. This paper mainly discusses the auxiliary effect of data mining on the innovation model of vocabulary teaching from four aspects: vocabulary total amount, word frequency, collocation and bilingual text data comparison.
Keywords Japanese interpretation; vocabulary teaching; word frequency
0 引言
數據挖掘是從海量的、隨機的數據中尋找趨勢、規律和特殊關系性的過程。數據挖掘技術在諸多領域都得到了廣泛應用。關于數據挖掘技術與語言學和文學研究結合,毛文偉(2018)指出有利于通過學科交叉融合拓展研究視角,豐富研究手段,幫助研究者從數量龐大、內容紛繁的數據中準確、高效地提煉出僅憑主觀難以迅速察覺的隱含規律或趨勢。
本研究嘗試基于數據挖掘技術推動教學模式創新之理念,通過可行性軟件和工具,探索科學有效的教學方法。作為初探,本文將以小語種復合人才培養模式下日語口譯課為對象,以數據挖掘應用于文本分析中較基本的方法,如詞匯總量、詞頻、搭配統計及雙語詞匯對比等方式進行統計、分析,在此基礎上,論述分析結果應用于口譯詞匯教學的可行性和有效性。
1 日語口譯詞匯教學的現狀
詞匯對口譯譯出質量起著至關重要的作用。口譯的詞匯準備也是譯前準備的關鍵環節。綜觀日語口譯教材中的詞匯出現方式,發現和其他課教材基本一致,多為對任務語篇中的生詞或難譯詞進行的語義解釋。對詞匯能力的訓練方式也主要以語篇中的單詞互譯、速譯、多譯(一對多或多對一)為主。筆者認為傳統的口譯詞匯出現和訓練方式,其局限性在于往往圍繞個別語篇,且過于聚焦微觀,無法讓學生從宏觀角度自主構建對詞匯出現總量、詞頻、關鍵度、搭配、源語目的語詞匯差異的多維認知。
另一方面,較英語相比,日語口譯教學與信息技術和計算機輔助翻譯結合不足也是目前存在的問題之一。碩士階段的口譯專門性較高,而本科階段口譯教學兼具夯實基礎和提高鞏固的雙重任務。小語種復合人才培養目標的確立,使得小語種本科階段口譯教學所處環境發生了變化。需要順應新形勢,結合自身特點,創新口譯教學模式。詞匯是口譯教學的重要一環,詞匯先行對整體模式改革的推進具有開端性和基礎性作用。
2 口譯詞匯教學的新意義和內涵
小語種復合型人才培養模式下,高校為小語種專業學生開設了非外語類專業課程,如我校為小語種專業學生提供了16學分的專業拓展課程模塊,學生可自主選修其他專業的課程。這為學生掌握一門專業知識打開了渠道,對拓展課所處領域在深度和廣度上可以形成一定的認識。這為日語口譯課程改革提供了一定的條件。筆者認為日語口譯課可改變傳統粗淺地涉及多領域的模式,分配適當學時或通過翻轉課堂、個性化學習等方式,結合學生所修非外語類拓展課程,進行縱深口譯能力訓練。
口譯詞匯學習應在新形勢下,進一步深化邏輯思考、信息分析整合、語義剖析重構、記憶及交際技能訓練的兼顧。與建構主義理論相符合,可以更好地實現這一目標。建構主義是以學習者為中心的理論,認為知識是借助他人或利用資料媒介,由認知主體充分發揮主觀性,對事物的性質、規律、內在聯系進行深入思考,不斷通過意義建構而獲得的。在建構主義理論指導下,會促使教師不斷思考和探索如何在教學中對發揮“學生主動性”和實現“意義建構”。筆者認為日語口譯詞匯教學中,數據挖掘、分析有助于激發“學生主動性”和實現“意義建構”,是讓學生自主構建對詞匯多維認知的重要且有效途徑。
3 數據統計分析結果在口譯詞匯教學中的應用
數據挖掘和分析的前提是語料。語料在口譯教學中起著重要作用。關于口譯語料庫建設,國內外已創建如“歐洲議會口譯語料庫”、日本名古屋大學的“同聲傳譯語料庫”、上海交通大學的“漢英會議口譯語料庫”、“中國總理‘兩會記者會漢英交替傳譯語料庫”等(鄧軍濤2018)。近年來,漢日或日漢口譯語料庫方面,除北京第二外國語學院在建或擬建的口譯大賽語料庫、專業譯員語料庫、電視同傳語料庫之外(路邈2018),并不多見。綜觀各類口譯語料庫,可有三點發現,首先從應用成果來看,多服務于口譯研究,而非口譯教學,尤其是在以學生為主的教學模式中,難以發揮實用性作用;其次,專業度過高,專門性過強;第三,多為真實對譯語料。這些語料很難適合本科口譯教學全方位要求,尤其無法滿足對主題多元涵蓋性和譯前準備訓練的需求,無法實現口譯教學各環節中高階思維和自主學習能力的培養。
本研究不局限于真實雙語口譯語料庫,主張結合本科教學需要,著眼于整個教學環節,根據主題自建動態、靈活、有時效性、有針對性的語料資源。因此,不僅限于口譯現場音視頻撰寫的語料,有助于譯前準備、口譯專項能力訓練的文字資料等,也是重要組成部分。
教學設計具體過程為教師確定課題,引導學生設計口譯任務流程,并對各環節進行詳細計劃。在此基礎上,進行分組,各組制定方案。就詞匯環節,各組確定目標,收集語料,再運用文本統計工具進行分析,最后進行總結發表。
3.1 詞匯總量和詞頻統計
通過量化,可以更直觀、更明確地反映出語言特征和有關主題的趨勢。以自建口譯對應語料、背景知識相關語料等為對象,進行詞匯總量和詞頻統計,引導學生思考語言特征和語言間差異、把握趨勢等。
教學設計如下:首先由教師確定課題,引導設計完整任務流程;學生分組,對任務進行分解,各組自主收集語料,對詞匯總量和詞頻進行統計、分析;最后進行匯報。
以商務相關內容為例。譯前詞匯準備任務中,常常需要進行企業概況詞匯、主題詞匯(含業界新聞、動態、同類會議等)、專業術語詞匯等準備。
企業概況、業務內容、發展是必須需要準備的內容。首先,以同質性語料為例進行教學設計。將35家日本企業概況介紹視頻進行文字轉寫,或對文字材料進行核對,形成總字數24萬7000字的日語同質性語料。語料建好后,用KH-Coder統計詞頻,得出前150位高頻詞,如表1。
同質性語料的收集和統計分析在口譯詞匯長期準備內容之一。從同質性語料中抽取的高頻詞,推斷是在同類場合出現頻率較高的詞語。以往的口譯教學模式中,在詞匯方面,傾向于對新詞、專業術語、難譯詞展開訓練,而如表1中出現的高頻詞因較基礎且簡單,往往被忽視,未能加以訓練。高頻詞雖看似簡單,但仍需相應的強化或定式訓練,加強在聽、記、譯上的熟練度,從而減輕短時記憶負擔,增強口譯中接受源語和產出目的語的能力。
結合高頻詞詞表,可從三方面展開訓練。首先,針對高頻詞,設計訓練,使達到超出對一般詞語的理解度、快譯度和準確度,如限時完成規定數量的高頻詞速譯訓練;其次,句子速譯訓練,利用KH-Coder的索引功能,抽取例句進行針對性速譯訓練;再者,針對部分高頻詞,運用數學或繪畫符號等,設計筆記符號,并進行練習鞏固,筆記訓練是本科口譯教材和實戰訓練中較難實現的環節,導致這一問題的原因是缺乏對詞語出現頻率的認知,比如名詞往往是筆記符號教學中容易被忽視的內容,但通過表1可以看出名詞所占比例較大。還可以抽取全部詞匯,通過EXCEL表格的重復刪除功能,與自建單詞表進行比對,即可在一定程度上得到生詞;最重要的是以高頻詞及句型為線索,掌握常用句式,熟悉核心信息,從而提高接受與理解信息的能力。
其次,也可選用關聯性語料進行統計分析。關聯性語料是多角度背景信息語料,如公司新聞、媒體報道、行業信息等都可以是商務主題關聯性語料的重要來源。關聯性語料音視頻資源較難獲得,但文字資源渠道較多,可廣泛利用。以華為公司為例,收集華為官方網站日文版(2019年1月-7月)之間的公司新聞。在對其進行預處理后,測算出現頻率前150位的詞匯(對個別識別錯誤進行調整后,得到表2所示的141個。
以“5G”為例,由高頻詞第1位可推斷“5G”是華為動向中熱點詞,“5G”直譯即可,但大部分學生卻并不能馬上聽懂或快速準確地譯出“5Gに関する商用契約、5G展開コスト、5Gフィールド試験”等。利用KH-Core的索引功能對“5G”進行檢索,可以抽取相關用法,轉錄音頻后還可以通過速譯、聽譯和筆記訓練等方式加以練習。
3.2 搭配
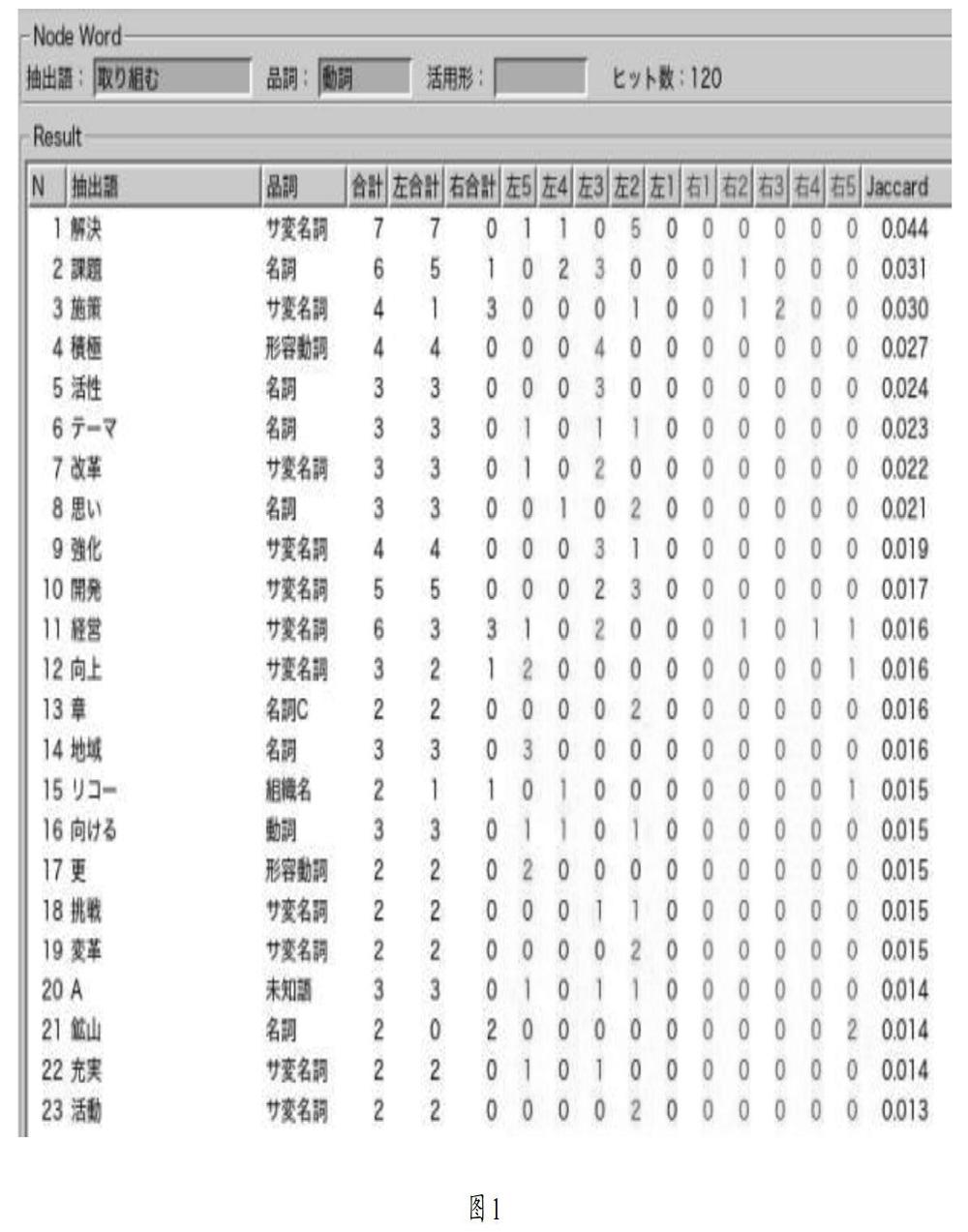
語料分析軟件或工具,在測算詞匯總量和詞頻的同時,也可以根據詞語索引實例,便于分析搭配。以3.1中使用的公司概況介紹語料為例,以其中出現次數為120次的“取り組む”一詞為例,通過軟件的句子索引功能,可調出所有含有“取り組む”的例句,也可以進一步將前后搭配詞語及所處位置進行統計(圖1)。
可見“取り組む”常與“充実、拡大、活用、事業、プロジェクト、変革、投資、開発、対策、角化、計畫、コスト削減”等詞搭配。通過較為集中的訓練,可增強學生對“取り組む”一詞的理解能力、預測能力和應變能力,減輕記憶負荷。
再以華為高頻詞統計第一位“5G”為例,即便學生能聽出“5G”,但往往會因聽不出或不理解與之搭配詞語,造成口譯過程中信息處理中斷或不完整。而運用KH-Coder進行抽取檢索,可以一目了然地歸納出常用搭配,如「5G技術、5G基地局(の設置/性能)、5Gに関する商用契約、5G展開を加速する、5G投資、5Gネットワークの構築、5G営業免許の発給、5G商用化 商用展開 商用導入 商用活用、5G特許、5Gフィールド試験、5Gを運用する、5Gのサイバーセキュリティ保証、5G展開コスト/5G展開の將來、5Gの産業応用、5Gオープンラボ」等,可以以此進行集中訓練,再進一步運用索引例句功能,選取實例,轉成音頻,做速譯、聽譯、筆記訓練。
基于大量信息,經數據統計得出常用搭配,可高效地歸納出使用規則,以此進行集中訓練,可以提高譯出質量;同時,利用句子或段落可以進行速譯、跟讀、復述、概述、提煉等練習,可提高轉換理解和預測文脈的高階能力,尤其有助于口譯中對邏輯最上層信息的提煉能力,這也是口譯縱向分析訓練即邏輯分層能力訓練的創新模式,可幫助提高區分關鍵信息和輔助信息的能力。同時可以增強應變能力,減少心理壓力和認知負荷。高頻詞不僅反映出頻率,而且也是其信息重要度的體現。“5G”以第一位高頻詞被抽取,說明它是華為業務和發展的關鍵詞,可以進一步收集有關“5G”的信息,深度構建背景知識。KH-Core文本分析工具為高頻詞與背景知識構建、管理能力培養的深度結合提供了可能。
3.3 雙語詞匯對比
運用文本分析統計工具,將微小對譯語料資源進行對比,觀察總量或詞頻,分析語言差異或多譯現象等。
以華為某條新聞語篇中日雙語語料(日語共1045字,漢語515)進行粗略對比為例,日語語料用KH-Core,漢語語料用AntConc,分別進行統計,制成單詞列表和詞頻表,觀察差異并進行分析。下面以“業務、增長、的、會”為例,探討分析結果在詞匯教學中的應用。
以“業務/事業”為例,漢語語料中出現了4次,而翻譯成日語語料卻出現了11次,由此利用索引功能抽取句子,可發現漢語和日語在語言表達習慣上的差異。
(1)消費者業務收入為2208億元。智能手機發貨量(含榮耀)達到1.18億臺,同比增長24%,平板、PC、可穿戴設備發貨量也實現了健康、快速增長。①
(1)′ コンシューマー向け端末事業。同事業グループの2019年度上半期売上高は2,208億元に上りました。スマートフォンの出荷臺數(Honorブランドを含む)は前年同期比24%増の1億1,800萬臺に達したほか、タブレット、PC、ウェアラブルなどの製品分野でも大きく成長を遂げ、ファーウェイはあらゆるシーンでシームレスでインテリジェントなユーザー體験の提供を可能とするデバイスエコシステムを拡大しつつあります。②
在一定的文脈中漢語形成了較簡潔的行業特殊說法,且只出現1次;而日語更講究字面嚴謹和預告性,出現了2次,口語中“続いてコンシューマー向け端末事業(について)ですが、同事業グループの2019年度上半期売上高は2,208億元に上りました”更符合目的語聽眾的理解習慣。
通過文本統計分析工具,可以讓我們從數據中直觀且迅速地捕捉到差異,以此為線索進行比照,可分析出語言表達習慣的不同,便于在口譯中作出增減。不斷積累,可以更好地理解源語,經過較為準確的重構,形成聽眾接受度較高的目的語。
再如“增長”一詞,觀察到數量差異,調取文本進行比對,如以下兩個句子,可以發現被譯成“急速な伸び、成長”等。通過一對多、多對一對譯分析,可以豐富詞匯積累,避免口譯過程中語言匱乏和單調。
(2)梁華表示,“五月份之前,華為收入增長較快,‘實體清單之后,因為存在市場慣性,也取得了增長。……”③
(2)′梁は決算內容について、次のように述べています。「當社の売上高は5月まで急速な伸びを示し、エンティティリストに追加されてからも、成長を維持しました。……④
(3)平板、PC、可穿戴設備發貨量也實現了快速增長。⑤
(3)′タブレット、PC、ウェアラブルなどの製品分野でも大きく成長を遂げました。⑥
再看一下“的”,漢語語料中“的”僅有4次,而日語中“の”出現了17次,“的/の”的詞頻差是對譯語料普遍觀察到的現象。可以通過進一步分析歸納哪些情況翻成“の”更符合日語表達習慣。如漢語習慣使用時間狀語,而日語習慣轉換成定語修飾。漢語更簡潔凝練,日語需要進行必要的補充,由此帶來“の”的使用。
(4) 2019年上半年,華為業務運作平穩、組織穩定。⑦
(4)′2019年度上半期の事業運営は安定し、組織も健全でした。⑧
(5)? 計劃2019年研發投入1200億人民幣。⑨
(5)′當年度の研究開発投資は1,200億元に達すると見込んでいます。⑩
(6) 無線網絡、光傳輸、數據通信、IT等生產發貨情況總體平穩。
(6)′無線ネットワーク、光伝送、データ通信、ITなど関連製品の生産 出荷狀況は総じて安定しております。
觀察詞頻統計,發現漢語語料中“會”出現了3次,調取語料進行比對,三處中一處未翻,一處被翻譯“かもしれない”,一處被翻譯成“ことでしょう”。通過區別分析訓練,可以鍛煉學生的母語語法思維,也可以通過集中口譯訓練,培養語感,增加譯出速度。
詞匯總量的差異也可以讓學生更直觀地理解調整語速或選擇適當長度詞語的必要。
4 結語
以上,基于數據挖掘,淺析了文本統計工具分析結果在日語口譯課詞匯教學中的應用。主要從詞匯總量、詞頻、搭配、雙語文本數據對比四個方面,論述了數據挖掘對詞匯教學創新模式有一定的輔助作用。運用KH-Core或AntConc等對文本進行數據統計,可以幫助我們發現詞匯使用的一些規律和趨勢,有助于集中且有針對性地進行各種訓練,也可以激發學生自主構建詞匯多維認知的能力。基于大量靈活的語料資源,運用數據挖掘技術,較傳統口譯詞匯教學方式相比,更有助于口譯詞匯的長期積累,在培養口譯全方位能力如口譯思維、信息接受和重構能力、譯出質量等方面,具有一定優勢。小語種復合人才培養模式不斷推進,深度結合所復合專業,推進縱深口筆譯能力培養必將越來越重要。以建構主義學習理論為指導,基于語料,漸進式應用數據挖掘技術具有一定的可行性和必要性。
參考文獻
[1] 毛文偉.數據挖掘技術在文本特征分析中的應用研究——以夏目漱石中長篇小說為例[J].日語學習與研究,2018(12).
[2] 鄧軍濤.口譯教學語料庫:內涵、機制與展望[J].外語界,2018(3).
[3] 路邈.漢語口譯語料庫的構建及其在翻譯教學研究中的應用[J].日語學習與研究,2018(6).
[4] 毛文偉.論數據挖掘技術在文本分析中的應用[J].日語學習與研究,2019(1).
[5] 張威.中國口譯學習者語料庫建設與研究:理論與實踐的若干思考[J].翻譯教學,2017.
[6] 許常玲.探索建構主義理論下日語口譯教學的改進策略[J].中國校外教育,2018.
[7] 張理想.語塊視角下西班牙語口譯詞匯教學研究[J].現代交際,2019(12).
猜你喜歡
啟迪與智慧·教育版(2016年9期)2016-11-26 09:13:42
考試周刊(2016年88期)2016-11-24 14:11:33
儷人·教師版(2016年14期)2016-11-22 21:25:56
儷人·教師版(2016年15期)2016-11-22 03:01:01
考試周刊(2016年84期)2016-11-11 23:24:32
考試周刊(2016年85期)2016-11-11 01:39:48
考試周刊(2016年85期)2016-11-11 01:34:57
考試周刊(2016年85期)2016-11-11 01:29:36
南北橋(2016年10期)2016-11-10 16:47:08
課程教育研究·學法教法研究(2016年21期)2016-10-20 19:44:43
