基于教育大數據環境的擬人機器學習問題分析
2020-03-17 09:35:55翟道遠
科學導報·學術 2020年59期
關鍵詞:學習問題
翟道遠
【摘 要】教育大數據的發展一直都在不斷地推動人工智能機器學習發揮更大的作用。但是很少有學生能夠找到推動的核心、智能條件和挖掘的手段,這樣一系列問題實際會直接阻礙教育不斷向前發展。本文以此為背景來針對大數據環境中擬人機器學習的問題,并在一系列分析之后找出一種真正適合人類學習的系統。
【關鍵詞】教育大數據;大數據環境;擬人機器學習;學習問題;分析策略
引言:
隨著信息化的不斷發展,數據產生的規模和數量也很大,實際也給機器學習帶來一定的難度。多數不同類型的數據不僅不夠精確,而且也顯得非常雜亂。傳統的機器學習只能夠借助傳統的計算方法來直接分析數據,這勢必無法滿足現代大數據使用的需要。在計算數據時不僅大量的數據讓人感覺困惑,更無法借助不同服務器上數據的聯系來發揮一定的作用。因此,在大數據的背景下多數人都會對機器學習功能提出更高的要求。
1.研究背景
教學中的智能化都是相對而言的,為的就是能夠在分析問題的基礎上找出教學的規律。很多不同行業內部的數據將會呈現出非準確性、非感知性和非規律性的特點,遇到這些不太規律的問題時專業人員需要借助不同的干預和認識來找到事物內部存在的規律。
但是當今技術的發展已經改變了很多人教育和教學的方法以及概念,正是因為這些技術將會在很大程度上影響我們應對胡同環境的能力,不僅輸入的數據是非線性的,而且還混合了不同的視頻、文字和圖像。教育大數據作為教育領域重要的表現也為新時代教育教學的發展提供了新的思路和方法[1]。為此更多的人需要站在人的教育角度來從海量的信息內容中提取自己真正需要的信息,再具體分析以小變大的過程,因此從分析大數據入手來解決問題顯得尤為重要。
2.教學大數據時間軸問題和對象問題研究
2.1教學大數據時間軸問題研究
教學大數據時間軸所描述的是當多個不同事件發生過程中不同事件之間的關系,實際反映的也是事件的特性,多數人可以借助數據機器學習的內容來找到合適的教學策略,并更好地預測有關的事件。發展中,借助時間軸來尋找事物之間的規律也是數據挖掘過程中重要的研究方向。
事件的密度指的是事件的慣性、強度、稀疏程度和事件的影響力,最終體現的是對一個事件的反映程度。多數數據密度和學習的慣性也有著直接的關系。例如,很多學生會選擇再業余的時間去上網,這其實就是不同教學慣性所體現出的密度,而且這是一種正常的密度。但是突發的問題則指的是非正常密度的問題。
2.2教學大數據對對象問題的研究
真正所有的教學大數據研究的對象都會在實際教學中起到非常重要的作用,而站在不同角度教學者所關心的數據也是不同的。所以專業人員實際需要在研究挖掘數據的基礎上研究不同的數據對象,整個過程都是在總結有關經驗的基礎上更好地實現的,學生也會在分析不同經驗的基礎上確定不同的問題,從而獲得更多的數據。
2.3教學大數據衍生的問題
除了要在教學中研究有關的內涵數據和外延數據之外,更需要研究其他衍生的數據。只有通過研究不同類型的衍生數據才能夠讓新數據自身額特性和作用都會發生一定的變化。衍生數據不僅可以直接改變數據自身的性質,更可以直接挖掘數據。但是這些衍生的數據只能夠作為參考數據,并不能夠反映實際的事實。
3.擬人機器學習問題研究
只有讓教育具有人的思維和智力才能夠更好地辨識各種形態,最終才能夠找出針對性的決策。因此,多數人在辨別事物時一定要對不同的教育數據進行訓練,但是訓練并不是一個一蹴而就的工作,訓練和生成中的數據也是越來越多的,所以計算的過程也就會變得越來越復雜,最終的安全隱患也就會顯得越來越明顯。在此背景下,更多專業人員需要從多個方面研究擬人機器學習問題。
3.1擬人機器學習問題的研究
只有選擇真正合適的訓練方法才能夠讓廣大教育決策者能夠熟練地摘掉內部學習的內容和方向。借助機器學習訓練來提升智力思維不僅不會引發大量的災害,也不會給人類帶來負面的影響。各個國家都在分析傳統機器學習訓練中不足條件的基礎上來找出對應的策略,由此推出了擬人機器學習的方法,于是更多的人可以直接像人一樣進行學習。
一方面更多擬人機器學習訓練環境內部具有更多人為的因素,因此需要讓不同的訓練結果更好地接近人的意志,更不能夠給更多人帶來較為復雜的工作量,由此可以從擬人情感、觀點和立體構造空間出發來找出問題的答案[2]。多數擬人機器學習方法是從最近的地方引入,并借助深度規則系統進行的。更多的人可以借助原型中存在的觀察結果來系統地決定任何一件學習的事情,并直接借助擬人的思維來考慮人和教育自身的智能化。
多數擬人機器學習的方法非常適用于樣本數量有限和不連續的數據內部,這種研究思路也具有極強的精準性趨勢,內部也會存在一定的延遲現象,其不僅讓更多的影響因子出現在大眾面前,更與不同的數據訓練存在著一定的距離。
擬人化的學習會讓未來教育智能機器能夠更好地為人類服務,也更好地提升了自動化處理的水平,這樣不僅可以提升其自學和計算的效率,更可以強化教育智能化的能力。
3.2擬人機器學習在未來教育當中的應用
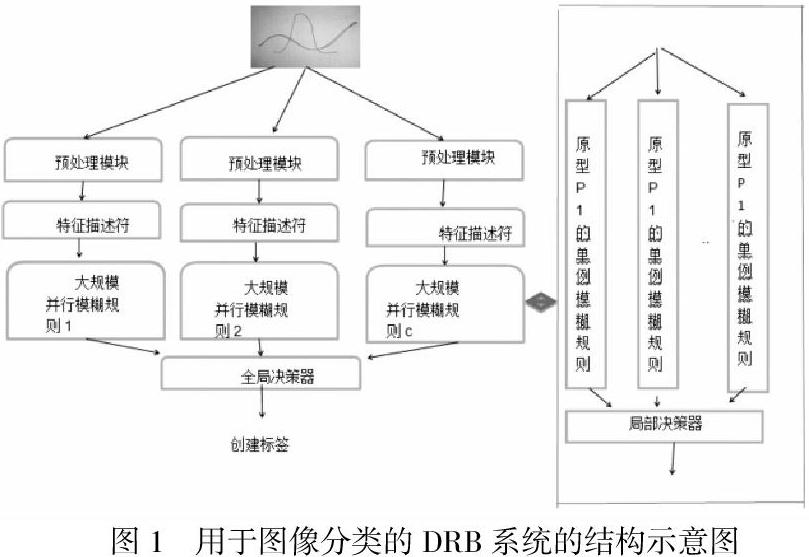
可以先識別未知的情境,并直接學習新的內容,最關鍵的是要在分析深度DRB系統的基礎上創造一種透明度較高的算法,并借助一種新的學習方法來簡單地進行修改。圖1顯示了整個DRB系統的結構,內部主要是由預處理模塊、特征描述符、大規模模糊規則庫和決策器組成。
第一,預處理器指的是存在于計算機視覺領域內部的預處理技術,主要是由歸一化、縮放、旋轉和分割組成;第二,特征描述為的就是能夠將一個原始的圖像直接投影到一個具有一定特征的空間內部,并讓不同的圖像有效地分離開來[3]。第三,大規模并行的模糊規則庫屬于一種較為復雜的非線性預測模型,不僅可以直接充當學習中的引擎,更可以讓不同訓練過程中的樣本都發揮更大的作用。因此專業人員需要從不同圖像內部識別出三個不同的并行模糊規則。第四,決策器指的是一個類別內部存在的決策器,專業人員可以在分析這些局部建議的基礎上來選擇真正合適的類別標簽。
4.結束語
綜上所述,教育人工智能屬于一個較為龐大的系統工程,實際可以在對事物進行定位的基礎上找出不同數據的特性。而我們只有在運用有效學習方法的基礎上才能夠學習更多透明、可解釋和可調控的陌生場景。而真正盲目的數據挖掘會帶來非常不好的效果。未來也只有真正按照人的意志來提取教育中所需的東西才能夠更好地實現智能化發展,相信人工智能的前途是無量的。
參考文獻:
[1]李尚晉.大數據環境下的機器學習研究 [J]. 電子世界,2018,(1):62-63
[2]顧潤龍.大數據下的機器學習算法探討 [J]. 通訊世界,2019,26(5):279-280
[3]Gu,Xiaowei & Angelov,Plamen.Semi -supervisedDeep Rule-based Approach for Image Classification. Applied Soft Computing,2018:68. 10.1016/j.asoc.2018.03.032
(作者單位:圣碼智能科技(深圳)有限公司)
猜你喜歡
文學教育·中旬版(2017年8期)2017-08-08 22:49:17
新教育時代·教師版(2017年24期)2017-07-28 17:59:31
法制與社會(2017年10期)2017-04-18 05:19:20
南北橋(2017年6期)2017-04-08 18:54:33
新校園·上旬刊(2016年9期)2017-04-06 19:02:19
中學課程輔導·教學研究(2017年3期)2017-03-30 09:21:20
科教導刊(2016年32期)2017-02-27 16:18:02
知音勵志·社科版(2016年9期)2016-11-09 06:49:33
考試周刊(2016年77期)2016-10-09 12:30:01
讀與寫·下旬刊(2016年6期)2016-06-24 12:13:42
